1 Stan 编码
考虑一个 Stan 编码的线性模型,代码来自 Stan 用户指南,如下:
data {
int<lower=0> N; // number of data items
int<lower=0> K; // number of predictors
matrix[N, K] x; // predictor matrix
vector[N] y; // outcome vector
}
parameters {
real alpha; // intercept
vector[K] beta; // coefficients for predictors
real<lower=0> sigma; // error scale
}
model {
// alpha ~ normal(0, 1); // prior
// beta ~ normal(0, 1); // prior
y ~ normal(x * beta + alpha, sigma); // likelihood
}Stan 模型代码至少需要三块:数据、参数和模型,各个部分尽量采用向量化的编程方式,少用 for 循环。编译 Stan 模型,传递数据进去,采样计算获得结果。
2 Stan 配置
在 R 语言社区,很早就存在一个 R 包 rstan ,它整合了编译代码、运行采样、模型输出等功能。下面先加载 R 包,设置 Stan 运行参数,准备输入数据,拟合模型。
library(StanHeaders)
library(rstan)
# Stan 代码不变就不要重复编译模型
rstan_options(auto_write = TRUE)
# 单核跑模型
options(mc.cores = 1)
# 每条链用一个线程
rstan_options(threads_per_chain = 1)
# 准备数据
cars_d <- list(
N = nrow(cars), # 观测记录的条数
K = 1, # 协变量个数
x = cars[, "speed", drop = F], # N x 1 矩阵
y = cars[, "dist"] # N 向量
)设置拟合模型的算法的各项参数。
# 拟合模型
fit_rstan_cars <- stan(
file = "code/cars.stan", # stan 代码文件路径
data = cars_d, # 观测数据
iter = 3000, # 每条链迭代次数
warmup = 1000, # 初始化阶段迭代次数
chains = 4, # MCMC 链条数
model_name = "cars_model", # 模型名称
verbose = FALSE, # 不显示中间输出
algorithm = "HMC", # 指定 HMC 算法
seed = 2022, # 设置随机数种子
control = list(adapt_delta = 0.8),
refresh = 0 # 不显示采样进度
)3 Stan 输出
fit_rstan_cars 是一个模型输出对象,可以用函数 print() 打印结果。
# 模型结果
print(fit_rstan_cars, probs = c(0.025, 0.5, 0.975), digits_summary = 3)## Inference for Stan model: cars_model.
## 4 chains, each with iter=3000; warmup=1000; thin=1;
## post-warmup draws per chain=2000, total post-warmup draws=8000.
##
## mean se_mean sd 2.5% 50% 97.5% n_eff Rhat
## alpha -17.606 0.070 6.943 -31.268 -17.640 -3.751 9719 1.000
## beta[1] 3.935 0.004 0.429 3.077 3.933 4.781 10281 1.000
## sigma 15.772 0.025 1.697 12.868 15.618 19.507 4593 1.001
## lp__ -159.481 0.024 1.266 -162.730 -159.170 -158.033 2888 1.000
##
## Samples were drawn using HMC(diag_e) at Mon Mar 10 10:37:39 2025.
## For each parameter, n_eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor on split chains (at
## convergence, Rhat=1).设置 4 条迭代链,每条链初始化阶段 warmup 迭代 1000 次,总迭代 3000 次,则初始化后阶段迭代 2000 次,4 条链总迭代 8000 次。
参数 alpha 是截距,beta[1] 是斜率,sigma 是标准差,lp__ 后验似然的对数,n_eff 表示采样效率,值越大越好,Rhat 表示马氏链混合效果,越接近 1 越好。
4 分布检查
4.1 参数迭代轨迹
以参数 \(\alpha\) 的迭代轨迹为例,如下图所示:
library(ggplot2)
stan_trace(fit_rstan_cars, pars = "alpha") +
labs(y = expression(alpha), color = "链条")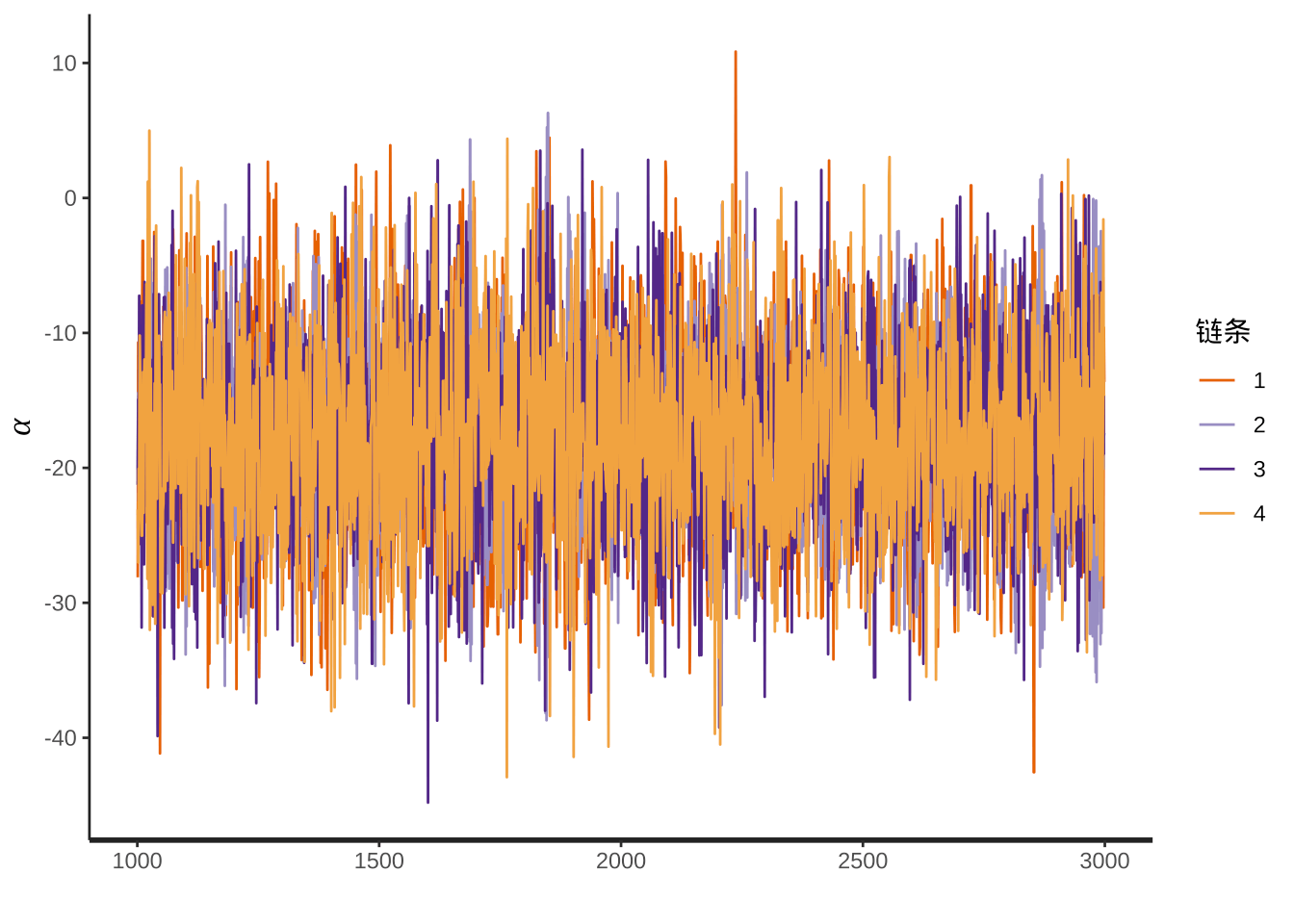
图 1: 参数 \(\alpha\) 的迭代轨迹
可见,4条链在初始化阶段之后的混合很好,很平稳。参数 \(\alpha\) 和 \(\beta_1\) 的联合分布如下:
stan_scat(fit_rstan_cars,
pars = c("alpha", "beta[1]"),
size = 1, color = "lightblue"
) +
geom_point(
data = data.frame(alpha = -17.579, beta1 = 3.932),
aes(x = alpha, y = beta1), color = "orange", size = 2
) +
labs(x = expression(alpha), y = expression(beta[1]))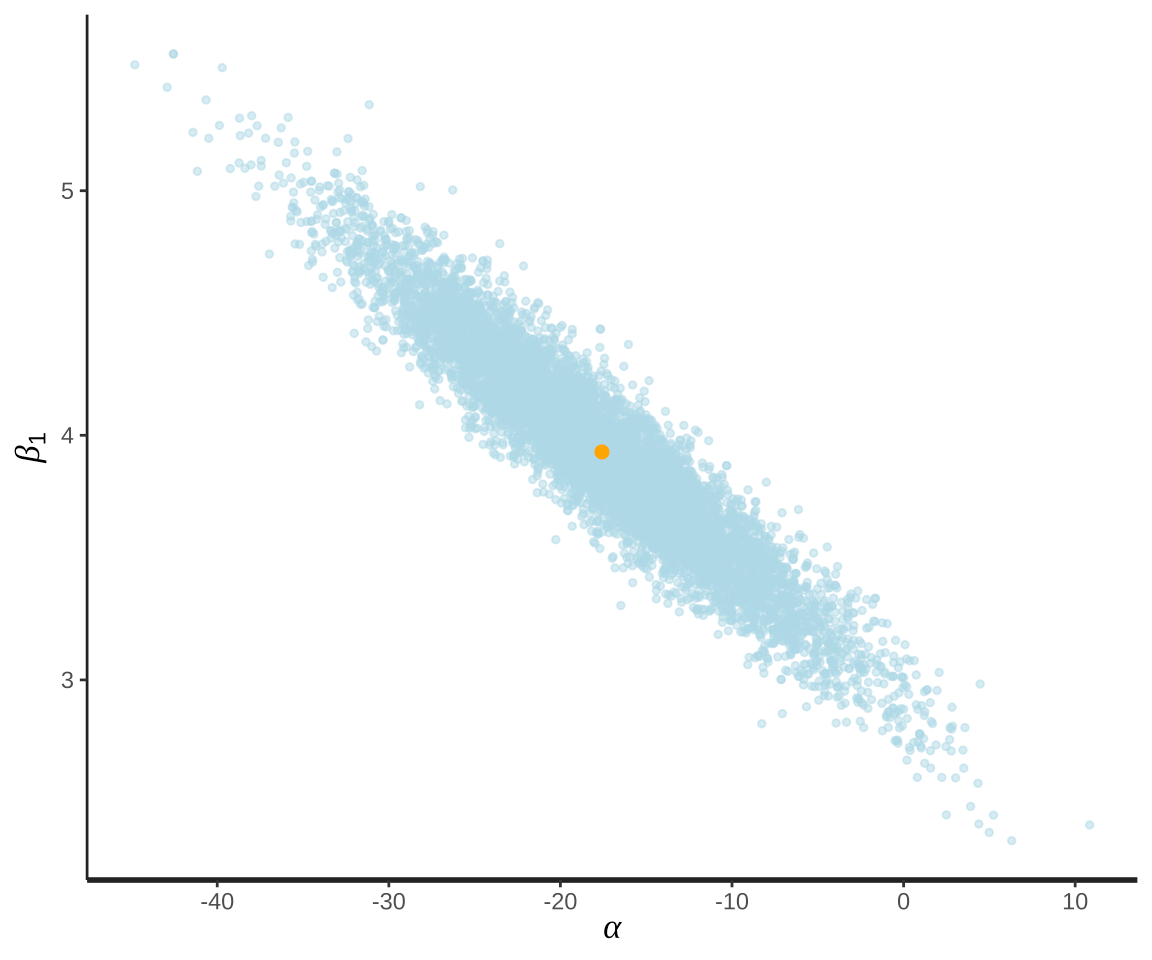
图 2: 参数 \(\alpha\) 和 \(\beta_1\) 的联合分布
理论上,参数 \(\alpha\) 和 \(\beta_1\) 的联合分布是二元正态分布,图上所示也是吻合的。
4.2 参数后验分布
根据每条马氏链的迭代值,获得参数 \(\alpha\) 的后验分布,每条链都是接近正态分布。
stan_dens(fit_rstan_cars, pars = "alpha",
separate_chains = TRUE, alpha = 0.35) +
labs(x = expression(alpha), fill = "链条")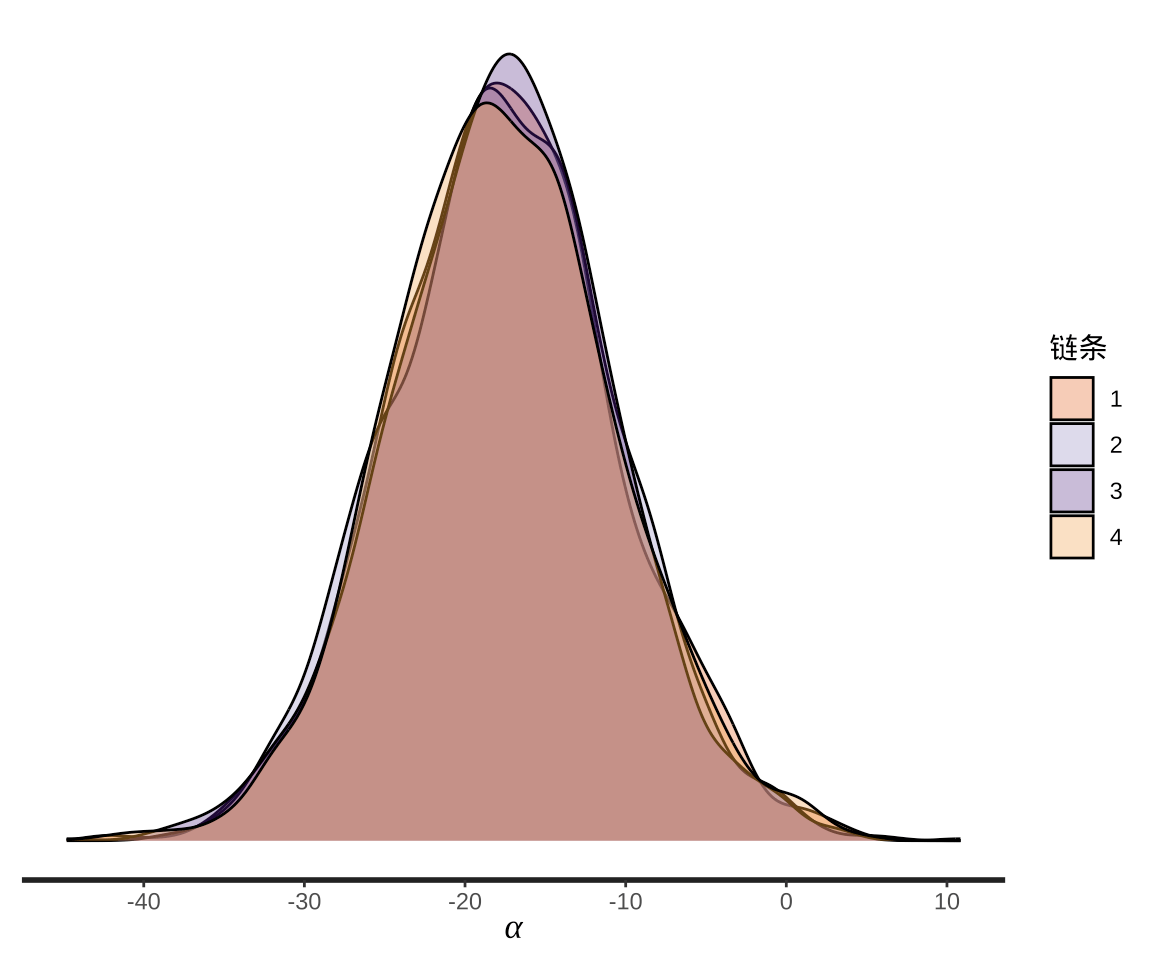
图 3: 参数 \(\alpha\) 的核密度估计
分别查看参数 \(\alpha\) 和 \(\beta_1\) 的后验分布。
stan_dens(fit_rstan_cars, pars = "alpha", fill = "lightblue") +
geom_vline(xintercept = -17.579, color = "orange", lwd = 1) +
labs(x = expression(alpha))
stan_dens(fit_rstan_cars, pars = "beta[1]", fill = "lightblue") +
geom_vline(xintercept = 3.932, color = "orange", lwd = 1) +
labs(x = expression(beta[1]))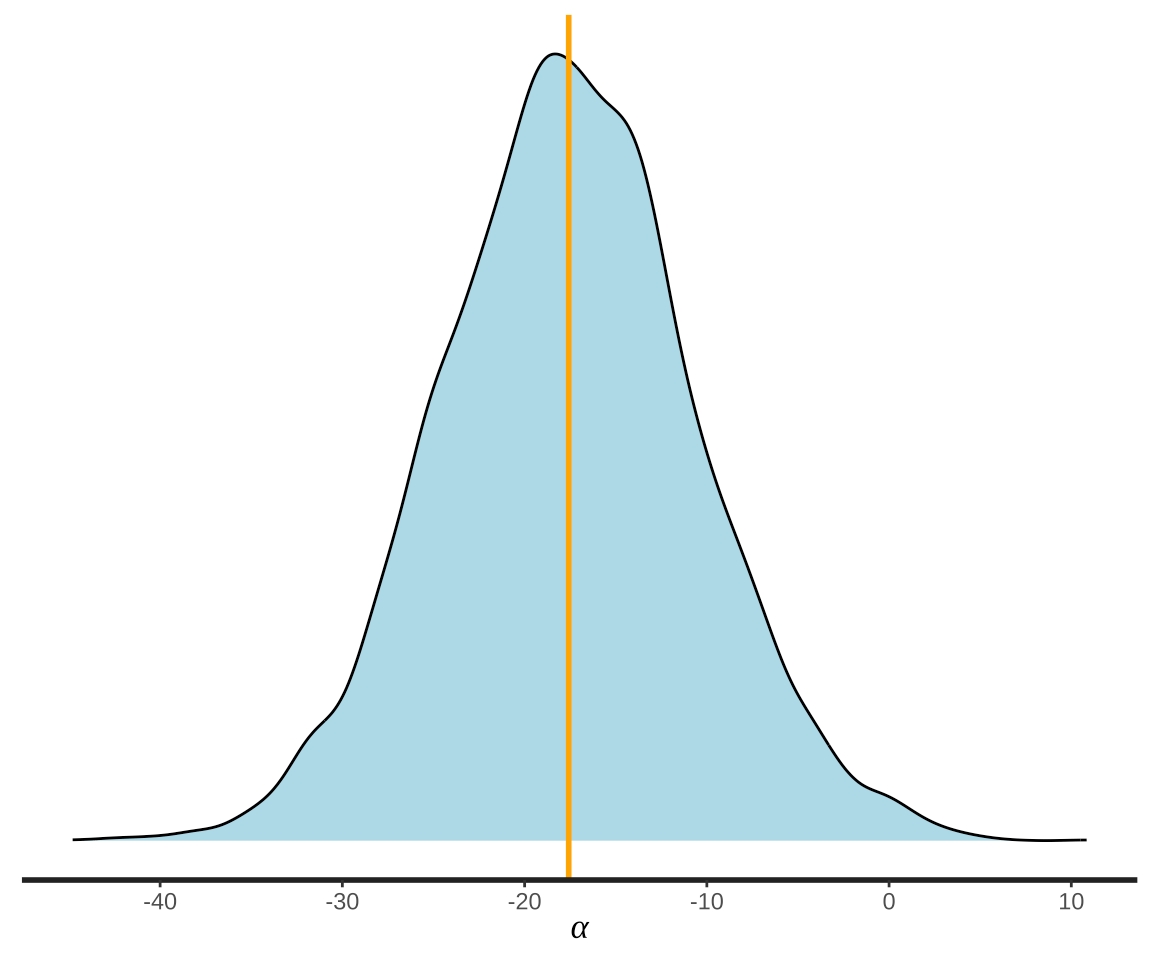
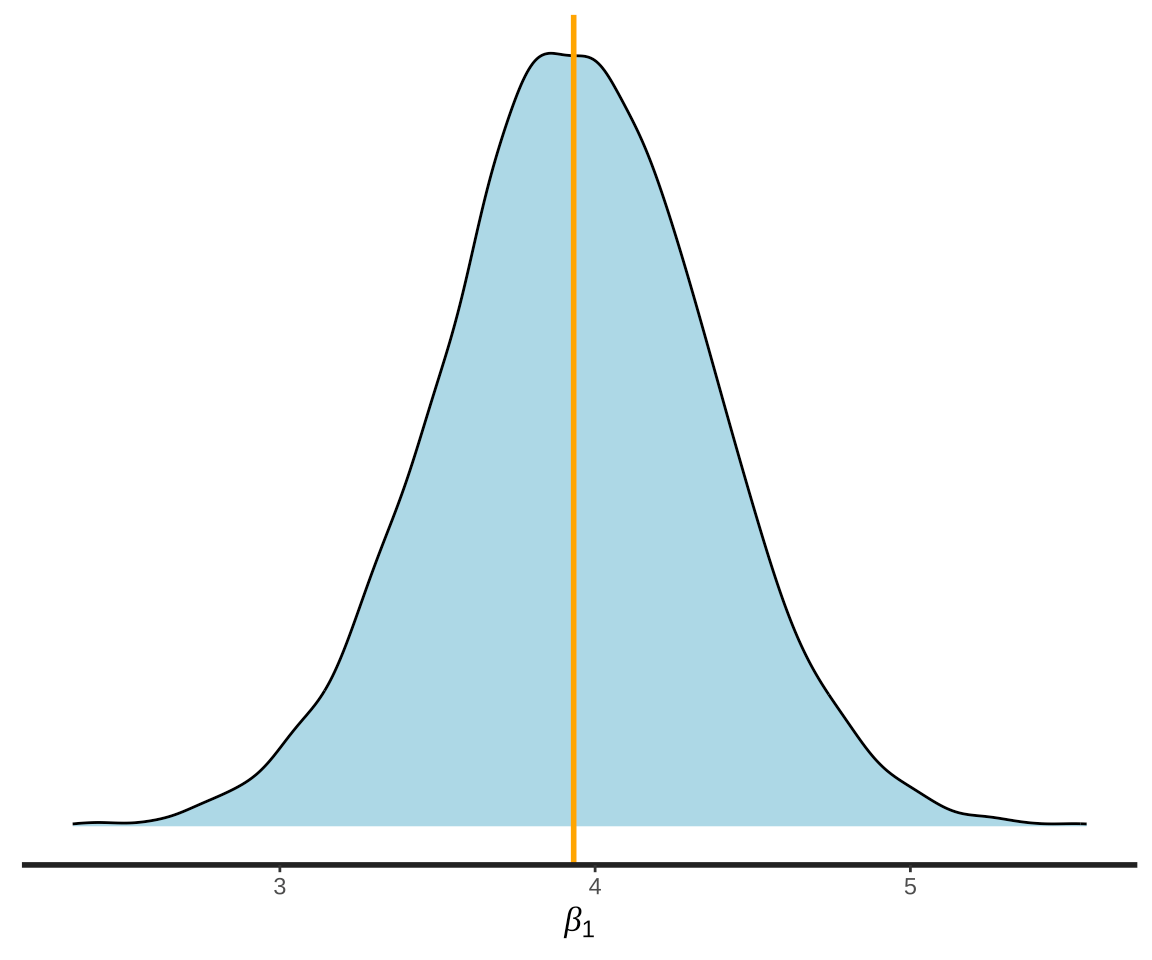
图 4: 参数的后验分布
5 brms 包
Paul-Christian Bürkner 开发和维护的brms 包是站在 RStan 和 cmdstanr 包肩膀上扩展包,封装了大量基于 Stan 语言的贝叶斯统计模型,可以拟合相当广泛的模型,线性模型不在话下。
fit_brm_cars <- brms::brm(
dist ~ speed, # 使用语法与 lme4 包类似
data = cars, # 数据集
family = gaussian(), # 响应变量的分布
backend = "cmdstanr", # 调用 cmdstanr 还是 rstan 包
algorithm = "sampling", # Stan 采样器
refresh = 0, # 不显示采样详细过程
seed = 2022, cores = 1, # 设置随机数种子和不并行
chains = 4, iter = 2000 # 4条马氏链迭代2000次
)## Start sampling## Running MCMC with 4 sequential chains...
##
## Chain 1 finished in 0.0 seconds.
## Chain 2 finished in 0.0 seconds.
## Chain 3 finished in 0.0 seconds.
## Chain 4 finished in 0.0 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 0.0 seconds.
## Total execution time: 0.7 seconds.此线性模型是非常简单的,模型拟合时间非常短。拟合模型的输出结果如下:
fit_brm_cars## Family: gaussian
## Links: mu = identity; sigma = identity
## Formula: dist ~ speed
## Data: cars (Number of observations: 50)
## Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup draws = 4000
##
## Regression Coefficients:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -17.57 6.99 -31.59 -3.97 1.00 3667 2596
## speed 3.92 0.43 3.09 4.76 1.00 3792 2995
##
## Further Distributional Parameters:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sigma 15.71 1.70 12.78 19.40 1.00 3915 2523
##
## Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).可见 brms 包与 rstan 包拟合模型的输出结果是非常相近的。各个参数的后验分布如下:
plot(fit_brm_cars)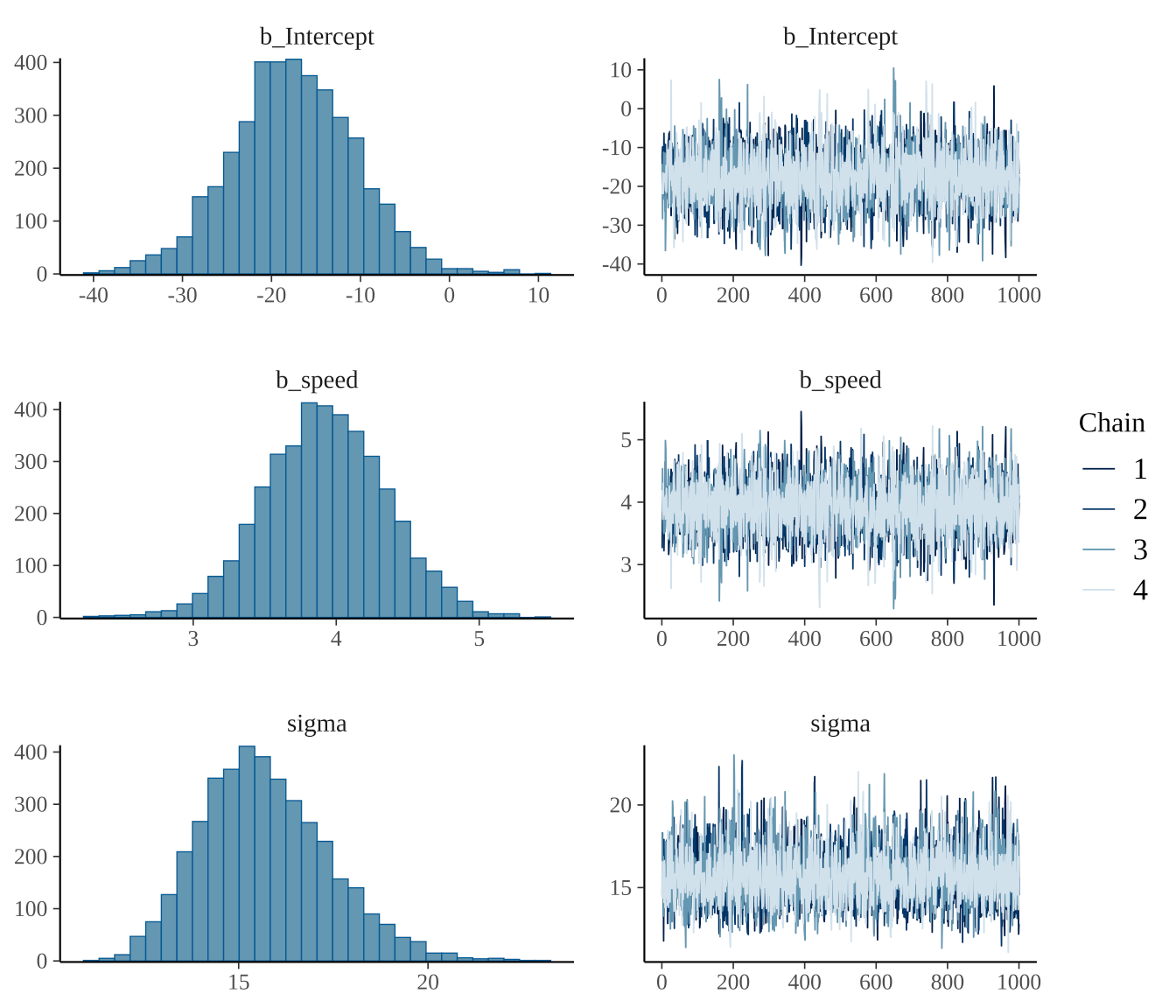
图 5: 参数的后验分布和迭代轨迹
在得知迭代过程平稳,后验分布也已获得,接下来,想要知道模型的效果,这有一些评估指标,函数 brms::loo() 基于后验似然做近似交叉留一验证。类似 AIC 和 BIC,针对贝叶斯模型这里有 LOOIC 以及 Pareto k 诊断。
brms::loo(fit_brm_cars)##
## Computed from 4000 by 50 log-likelihood matrix.
##
## Estimate SE
## elpd_loo -210.1 6.5
## p_loo 3.5 1.3
## looic 420.2 13.0
## ------
## MCSE of elpd_loo is 0.1.
## MCSE and ESS estimates assume MCMC draws (r_eff in [0.7, 1.0]).
##
## All Pareto k estimates are good (k < 0.7).
## See help('pareto-k-diagnostic') for details.类似调整的 \(R^2\) ,这里也可以计算贝叶斯 \(R^2\) 。
brms::bayes_R2(fit_brm_cars)## Estimate Est.Error Q2.5 Q97.5
## R2 0.641 0.05341 0.514 0.7163与频率派结果对照。
m <- lm(dist ~ speed, data = cars)
summary(m)##
## Call:
## lm(formula = dist ~ speed, data = cars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -29.07 -9.53 -2.27 9.21 43.20
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -17.579 6.758 -2.60 0.012 *
## speed 3.932 0.416 9.46 1.5e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.4 on 48 degrees of freedom
## Multiple R-squared: 0.651, Adjusted R-squared: 0.644
## F-statistic: 89.6 on 1 and 48 DF, p-value: 1.49e-12