本文主要学习一下贝叶斯可加模型及其在时间序列数据中的应用,标题中「大规模」的含义有三层,其一是此方法可以让大量不熟悉时间序列训练的人来使用,其二,此方法适用于大量不同的场景的预测任务,其三,此方法适用于大量时间序列数据的预测。时间序列预测在企业的应用中是很广泛的,比如谷歌的 GA(Google Analysis) 套件中的预测模块,脸书核心数据科学团队开发的先知预测框架 prophet。
贝叶斯可加模型的技术细节见 Sean J. Taylor and Benjamin Letham 的文章Forecasting at Scale,文中披露脸书团队开发的预测框架 Prophet (Taylor and Letham 2018) 采用 Stan 语言 — 继 BUGS 和 JAGS 之后的一种概率编程语言。这个框架同时提供 Python 语言和 R 语言扩展包。1
1 准备工作
本文在 R 语言计算环境中介绍 Prophet 框架的预测方法,先加载 prophet 包和必要的依赖。prophet 包基于 Stan 语言实现贝叶斯可加模型,用于时间序列数据的预测,支持日粒度数据,可以识别年季节性、周季节性、特殊节假日等。prophet 包依赖 rstan 包(贝叶斯计算框架 Stan 的 R 语言接口),所以,rstan 包的依赖也都需要提前装上。若读者熟悉 rstan 包的使用,那么调用prophet 包配置 Stan 的运行参数是类似的。
library(Rcpp)
library(rlang)
library(prophet) # 脸书公司的预测框架示例数据集来自 prophet 包的官方代码仓库,它是Peyton Manning(佩顿·曼宁)的维基百科页面访问量的对数。
# 加载数据
df <- read.csv('data/peyton_manning.csv', colClasses = c("Date", "numeric"))
str(df)## 'data.frame': 2905 obs. of 2 variables:
## $ ds: Date, format: "2007-12-10" "2007-12-11" ...
## $ y : num 9.59 8.52 8.18 8.07 7.89 ...读取数据加载到 R 语言环境中,数据集 df 包含 2905 天的页面访问量数据。Peyton Manning(佩顿·曼宁)的维基百科页面访问量的对数的时序图如下:
library(ggplot2)
ggplot() +
geom_line(data = df, aes(x = ds, y = y)) +
theme_bw() +
labs(x = "日期", y = "访问量(对数)")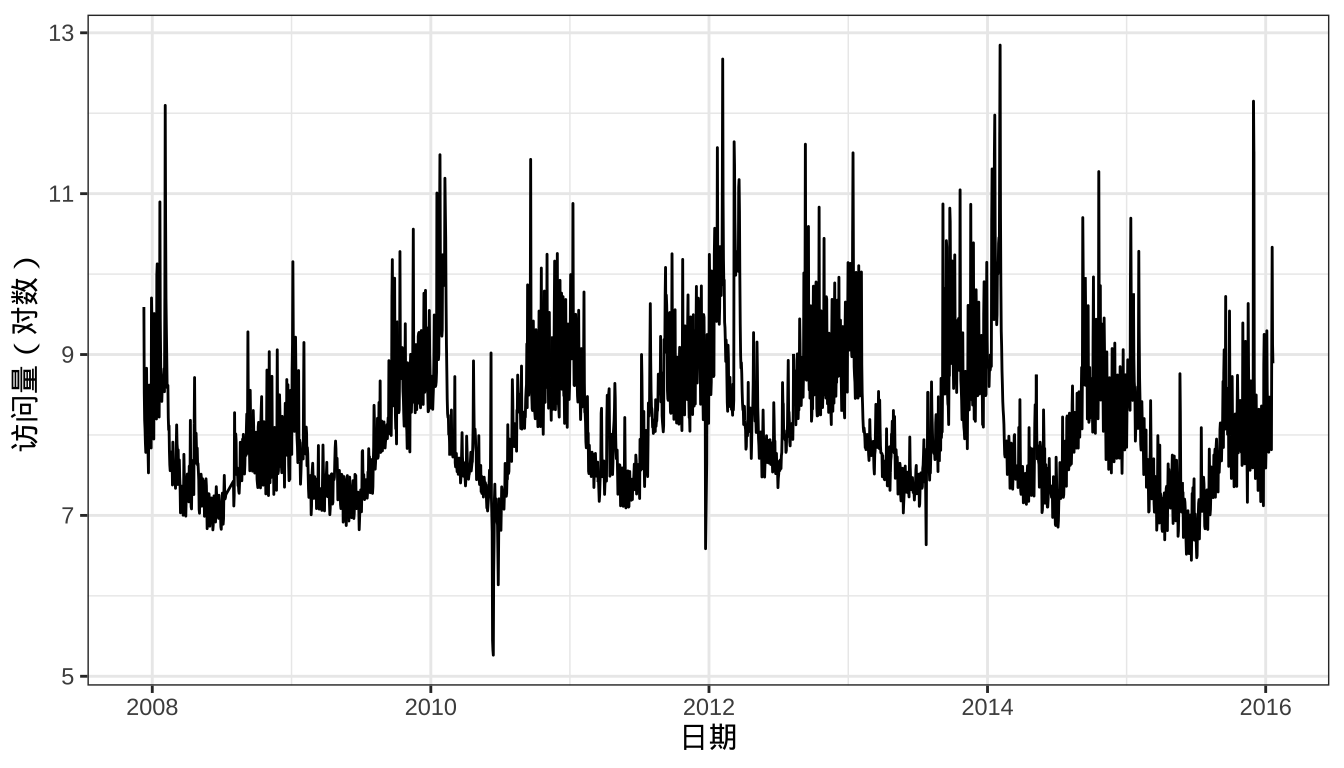
图 1: 佩顿·曼宁维基百科页面访问量
图中可以看到某种重复的波形变化。为了更好的观察数据中存在的季节性、周期性,下面根据日期扩展出 weekday ,截取 2013 年以后的数据,并以散点图形式展示。
df$weekday <- format(df$ds, format = "%a")
df$weekday <- factor(df$weekday, levels = c("Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"))
ggplot() +
geom_point(data = df[df$ds >= "2013-01-01",], aes(x = ds, y = y, color = weekday)) +
scale_color_viridis_d() +
theme_bw() +
labs(x = "日期", y = "访问量(对数)")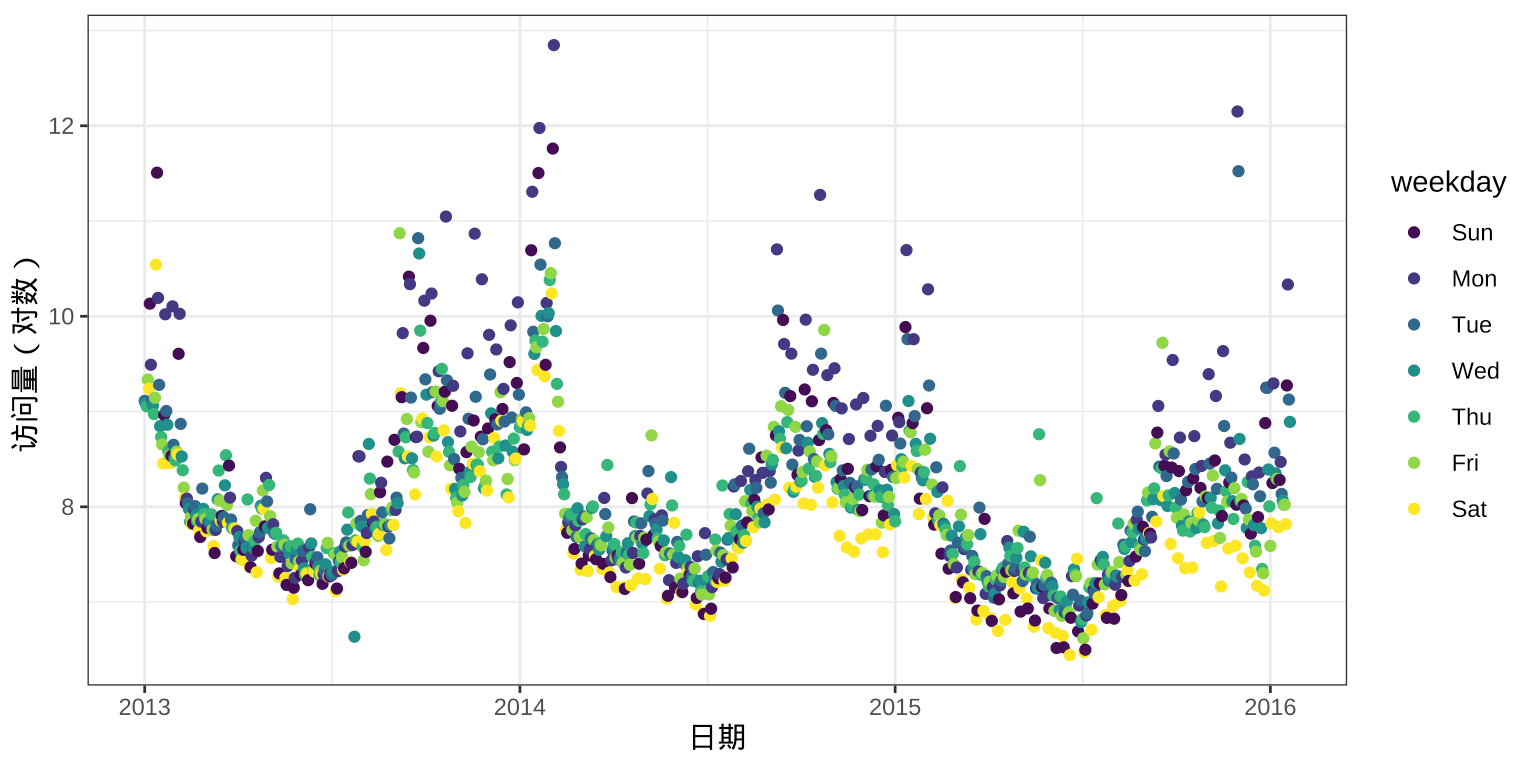
图 2: 访问量的年季节性
从 2013 至 2016年,有3年的数据,可以看到年的周期性,每年的趋势变化存在重复性,一年内的变化趋势是非线性的。再截取2015年之后的数据,放大某一年的数据,看周季节性,如下图所示。
ggplot() +
geom_point(data = df[df$ds >= "2015-01-01",], aes(x = ds, y = y, color = weekday)) +
scale_color_viridis_d() +
theme_bw() +
labs(x = "日期", y = "访问量(对数)")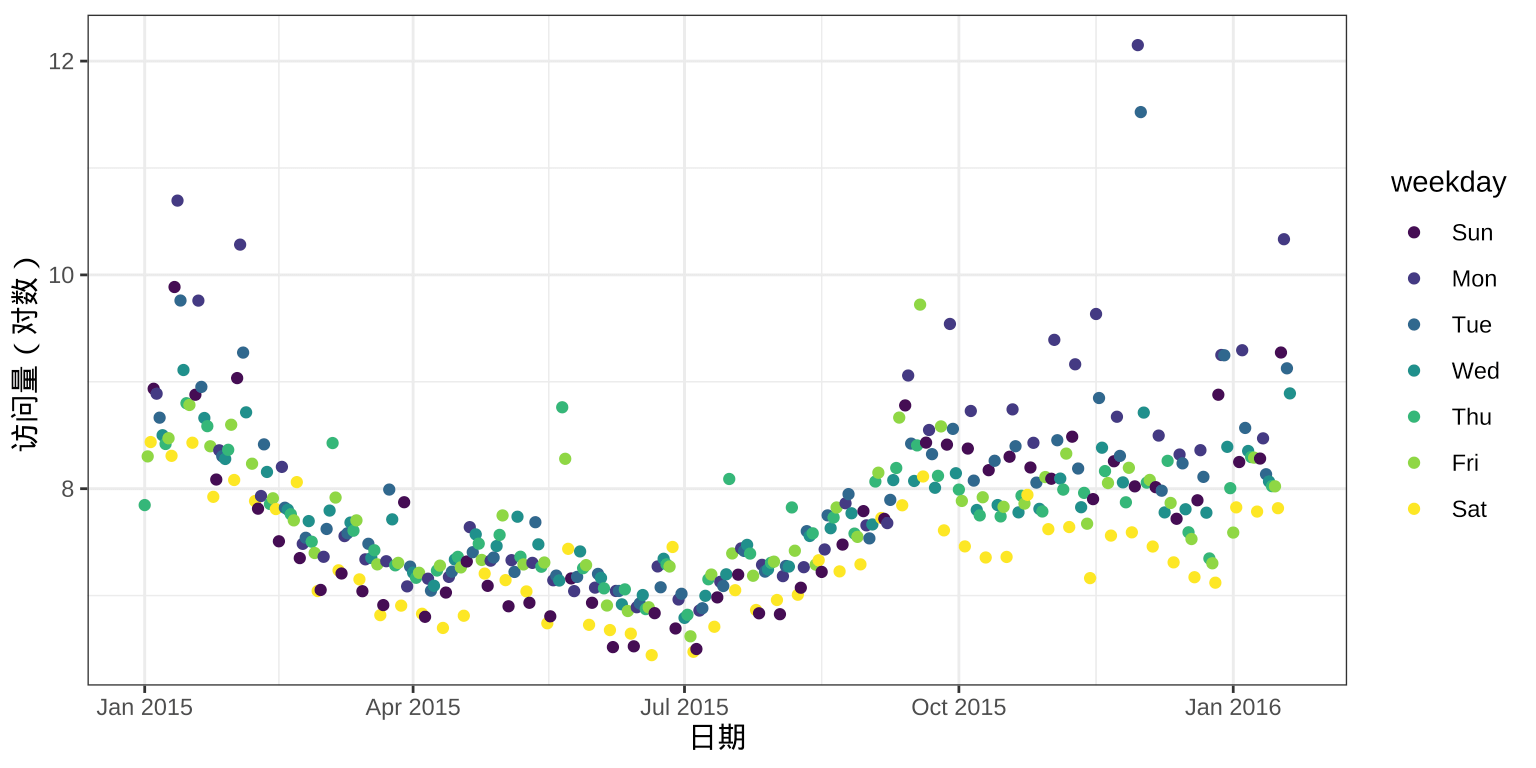
图 3: 访问量的周季节性
周的周期性,周日、周一至周六,存在重复性变化,全年的周日、周一至周六,存在分层,一周内的变化趋势是非线性的。
2 模型结构
Prophet 使用可分解的时间序列模型,这个模型的优势在于有很强的可解释性。模型各成分和参数有直观的实际意义,这个特点对于分析师根据实际数据调整模型很有帮助。模型包含三个主要的模型成分:趋势 \(g(t)\) 、季节性 \(s(t)\) 和假期 \(h(t)\) 。趋势常常是非线性的,季节性在这里包含周期性(周、年),假期成分针对特殊的节假日进行建模,残差 \(\epsilon_t\) 代表三个主成分不能建模的剩余部分,在这里,假定它服从正态分布。
\[ y(t) = g(t) + s(t) +h(t) + \epsilon_t \]
以上模型设定与广义可加模型 GAM 非常相似,在 R 语言中,mgcv 包专门拟合这类模型。(先挖个坑,以后再填)
3 模型拟合
此示例数据来自 prophet 官网,用此数据集是为了介绍 prophet 的使用。这里和官网采用一样的设置拟合贝叶斯可加时间序列模型,模型中设定增长趋势是线性的,季节性(周期性)是可加的,年、周的季节性通过数据自动确定。
library(prophet)
m <- prophet(df, growth = "linear", seasonality.mode = "additive", fit = TRUE)值得注意,df 是一个数据框类型的数据,它必须包含列名分别为 ds (日期类型存储的日期)和 y (观测数据)的两列,列名和类型是写死的。
4 模型预测
构造预测阶段的日期数据,准备预测未来 365 天的页面访问量
future <- make_future_dataframe(m, periods = 365)
tail(future)## ds
## 3265 2017-01-14
## 3266 2017-01-15
## 3267 2017-01-16
## 3268 2017-01-17
## 3269 2017-01-18
## 3270 2017-01-19调用函数 predict() 输入模型对象 m 和预测阶段的日期数据 future,生成预测结果。其中,yhat 表示预测值,yhat_lower 和 yhat_upper 是预测的上下限。
forecast <- predict(m, future)
tail(forecast[c('ds', 'yhat', 'yhat_lower', 'yhat_upper')])## ds yhat yhat_lower yhat_upper
## 3265 2017-01-14 7.829 7.129 8.596
## 3266 2017-01-15 8.211 7.458 8.912
## 3267 2017-01-16 8.536 7.802 9.329
## 3268 2017-01-17 8.323 7.622 9.060
## 3269 2017-01-18 8.156 7.406 8.854
## 3270 2017-01-19 8.168 7.443 8.854调用函数 plot() 展示预测结果,图中黑点表示观测值,蓝线表示预测值。
plot(m, forecast) +
theme_bw() +
labs(x = "日期", y = "访问量(对数)")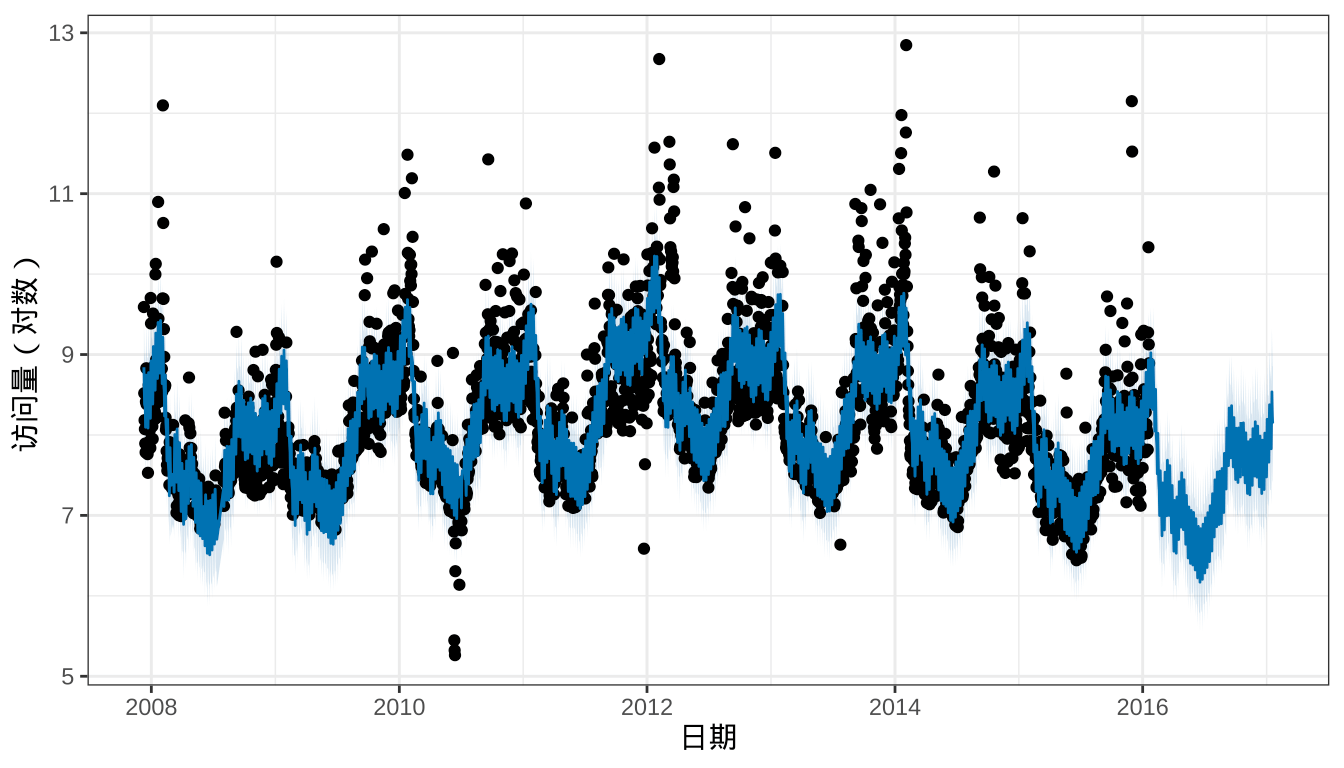
图 4: 访问量预测
5 模型成分
调用函数 prophet_plot_components() 展示趋势和季节性成分(年、周)。
prophet_plot_components(m, forecast)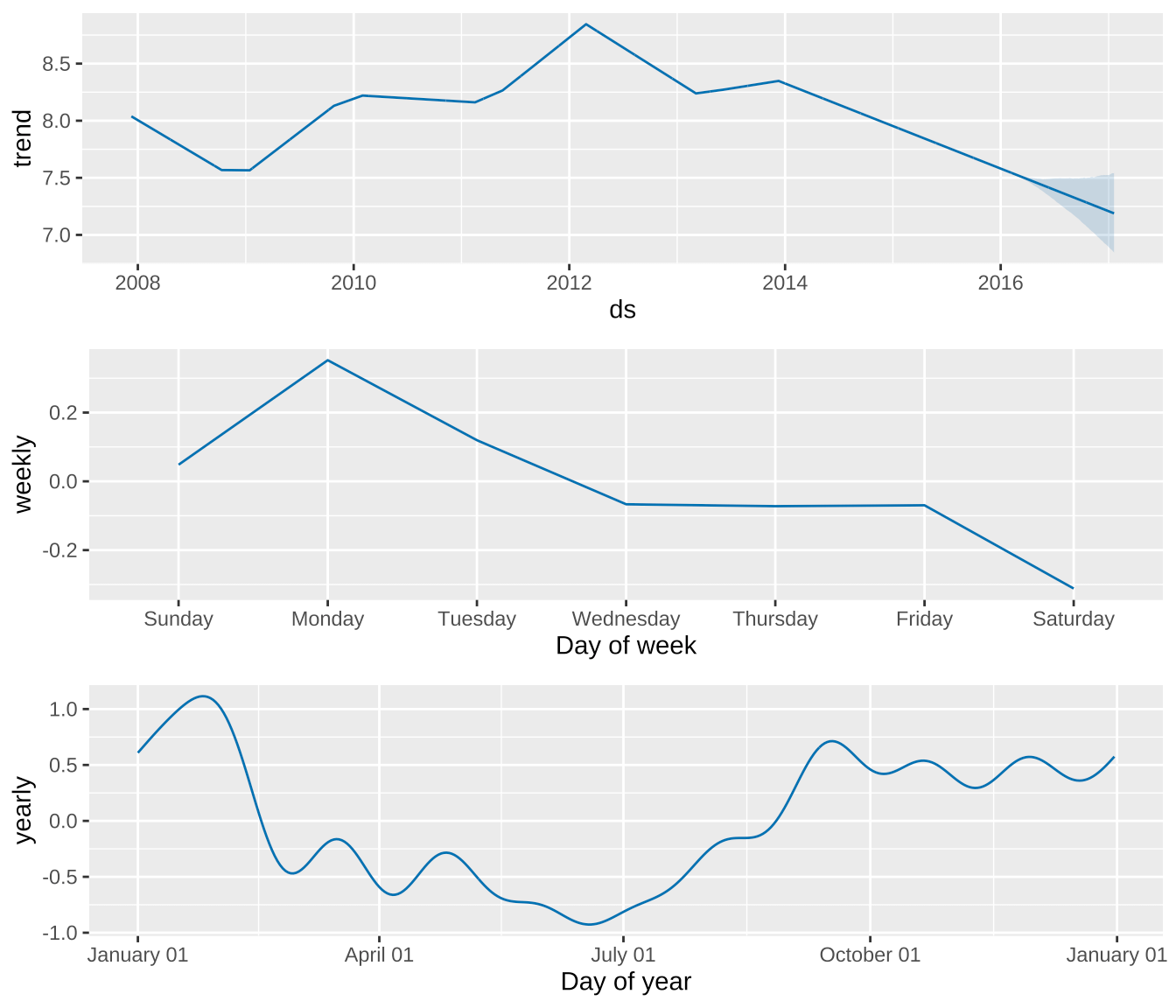
图 5: 时间序列分解图
四个子图依次代表历史趋势成分、周季节性、年季节性。趋势成分显示从 2008-2016 的年度变化是非线性的(分段线性),周的季节性成分显示一周内的变化也是非线性的(分段线性),年的季节性成分显示访问量的起伏变化,2月份和9月份是访问量的高峰(因为美国超级碗和劳动节),6月份是访问量的低谷。
6 节假日成分
前面没有考虑节假日影响,下面考虑一些影响较大的特殊日,比如佩顿·曼宁在季后赛出现的日期会导致维基百科访问量大增。(橄榄球比赛按照规格分例行赛、季后赛、超级碗。)超级碗是全国橄榄球联盟的年度冠军赛,胜者被称为“世界冠军”。超级碗一般在每年1月最后一个或2月第一个星期天举行,那一天称为超级碗星期天。
# R
# 季后赛
playoffs <- dplyr::tibble(
holiday = 'playoff',
ds = as.Date(c('2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07')),
lower_window = 0,
upper_window = 1
)
# 超级碗 一年一次
superbowls <- dplyr::tibble(
holiday = 'superbowl',
ds = as.Date(c('2010-02-07', '2014-02-02', '2016-02-07')),
lower_window = 0,
upper_window = 1
)
holidays <- dplyr::bind_rows(playoffs, superbowls)在模型中添加节假日信息之后,再预测。
# R
m <- prophet(df, holidays = holidays, growth = "linear", fit = TRUE,
seasonality.mode = "additive", yearly.seasonality = TRUE,
weekly.seasonality = TRUE, daily.seasonality = FALSE)
forecast <- predict(m, future)检查模型中包含的国家传统节假日或法定节假日。
# R
m$train.holiday.names## [1] "playoff" "superbowl"将节假日的预测结果筛选出来,查看一下。
# R
forecast |>
dplyr::select(ds, playoff, superbowl) |>
dplyr::filter(abs(playoff + superbowl) > 0) |>
tail(10)## ds playoff superbowl
## 17 2014-02-02 1.223 1.21
## 18 2014-02-03 1.906 1.43
## 19 2015-01-11 1.223 0.00
## 20 2015-01-12 1.906 0.00
## 21 2016-01-17 1.223 0.00
## 22 2016-01-18 1.906 0.00
## 23 2016-01-24 1.223 0.00
## 24 2016-01-25 1.906 0.00
## 25 2016-02-07 1.223 1.21
## 26 2016-02-08 1.906 1.43绘制模型各个成分的分解图,第二个子图展示节假日信息。
prophet_plot_components(m, forecast)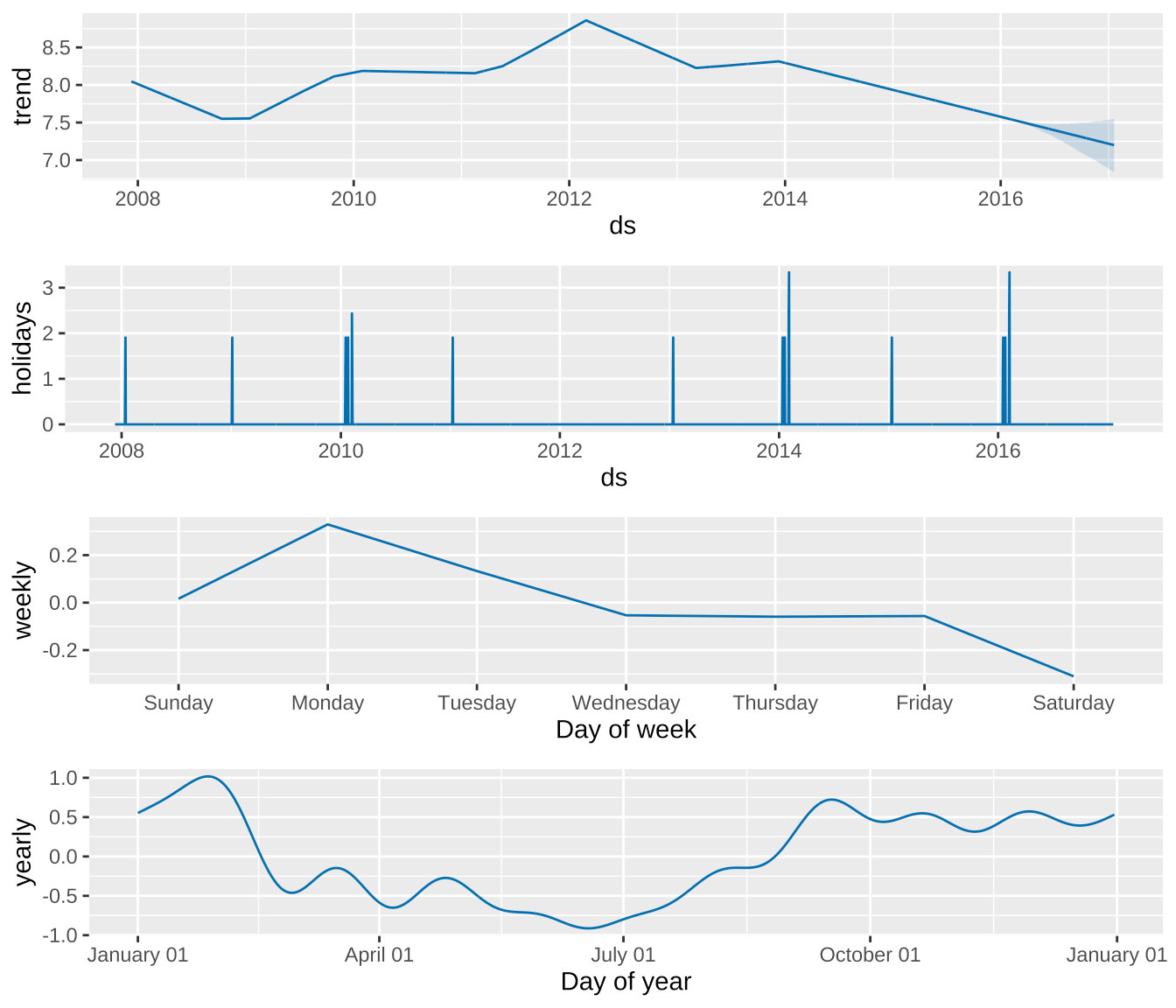
图 6: 时间序列分解图(含节假日)
在不同的应用场景中,节假日的含义是不同的,需要根据具体情况具体分析。就预测佩顿·曼宁的维基百科页面访问量来说,因为佩顿·曼宁在橄榄球赛事的影响力,橄榄球赛事有一年一度的超级碗,这些合在一起就构成这个具体问题的特殊性。如果要预测某平台的粽子销量,那么在中国,有端午节,粽子和端午节存在强联系,特别是在南方。总而言之。节假日需要根据预测问题的实际背景信息来收集。
此外,还有的时候,预测会受到特殊事件的影响,从而产生离群值。由于特殊事件的偶发性而产生不可(难以)预测性,在实际建模过程中,需要识别和剔除。
7 参考文献
prophet 包上次更新是 2021-03-30,已经是四年前了。↩︎