1 cars 数据集
数据集 cars 来自 Base R 内置的 datasets 包,仅有两个变量 speed (单位:英里/每小时)和 dist(单位:英尺),1 英里约等于 1.6 公里,1 英尺约等于 30.48 厘米。下表展示了数据集 cars 的部分内容。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| speed | 4 | 4 | 7 | 7 | 8 | 9 | 10 | 10 | 10 | 11 | 11 | 12 | 12 | 12 | 12 | 13 | 13 | 13 | 13 | 14 |
| dist | 2 | 10 | 4 | 22 | 16 | 10 | 18 | 26 | 34 | 17 | 28 | 14 | 20 | 24 | 28 | 26 | 34 | 34 | 46 | 26 |
将每一对速度与距离的值绘制在图上,并添加线性趋势拟合线及其预测值的置信带。下图展示 20 世纪 20 年代汽车里程与行驶速度的关系,那时候的汽车也就比乌龟爬得快一些,距今已有 100 年历史了。
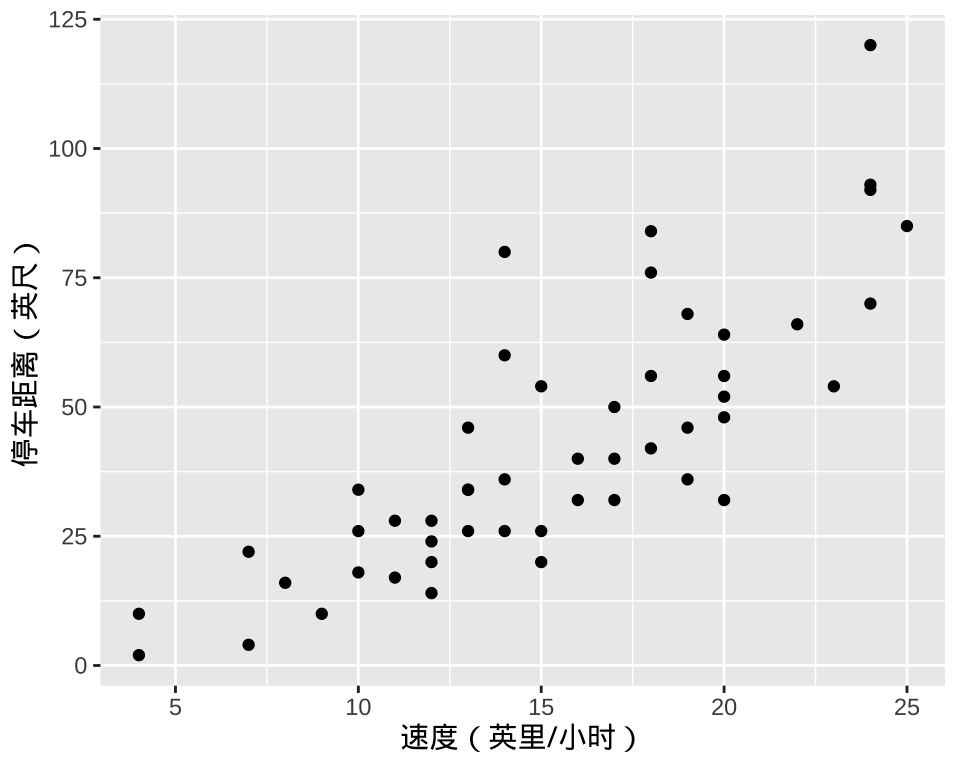
图 1.1: 汽车里程与速度的关系
2 线性模型
一般线性模型如下:
\[ \begin{aligned} \bm{y} &= X\bm{\beta} + \bm{\epsilon} \\ \bm{\epsilon} &\sim \mathrm{MVN}(\bm{0},\sigma^2 I) \end{aligned} \]
其中,\(\bm{y}\) 是观测的响应变量值,\(X\) 是观测的预测变量对应的系数矩阵,不是随机的,\(\bm{\beta}\) 是与预测变量对应的回归系数,\(\bm{\epsilon}\) 是随机的残差,各分量相互独立,且服从均值为 0,方差为 \(\sigma^2\) 的正态分布,\(I\) 表示单位矩阵。
回归系数 \(\bm{\beta}\) 最小二乘估计和残差方差 \(\sigma^2\) 的无偏估计如下:
\[ \begin{aligned} \hat{\boldsymbol{\beta}} &= (X^{\top}X)^{-1}X^{\top}\boldsymbol{y} \\ \hat{\sigma^2} &= \frac{\boldsymbol{y}^{\top}(I - X(X^{\top}X)^{-1}X^{\top})\boldsymbol{y}}{n - \mathrm{rank}(X)} \end{aligned} \]
其中,\(X^{\top}X\) 是可逆的,\(\mathrm{rank}(X)\) 表示矩阵 \(X\) 的秩。\(\hat{\sigma^2}\) 是根据残差的情况构造出来的。
关于残差 \(\hat{\bm{\epsilon}}\) 有如下结果:
\[ \begin{aligned} \hat{\bm{\epsilon}} &= \bm{y} - X\hat{\bm{\beta}} = (I - X(X^{\top}X)^{-1}X^{\top})\bm{y} \\ \hat{\bm{\epsilon}}^{\top}\hat{\bm{\epsilon}} &= (\bm{y} - X\hat{\bm{\beta}})^{\top}(\bm{y} - X\hat{\bm{\beta}}) \\ &= \boldsymbol{y}^{\top}(I - X(X^{\top}X)^{-1}X^{\top})\boldsymbol{y} \end{aligned} \]
\(\sigma^2\) 的极大似然估计如下:
\[ \widetilde{\sigma^2} = \frac{n - \mathrm{rank}(X)}{n}\hat{\sigma^2} \]
可见,极大似然估计有偏,但是它比最小二乘估计小。
回归系数 \(\bm{\beta}\) 的最小二乘估计的方差 \(\mathrm{Var}\{\hat{\bm\beta}\}\) 如下:
\[ \begin{aligned} \mathrm{Var}\{\hat{\bm\beta}\} & =\mathrm{Var}\{(X^{\top}X)^{-1}X^{\top}\bm{y}\}\\ & =(X^{\top}X)^{-1}X^{\top}\mathrm{Var}\{\bm{y}\}((X^{\top}X)^{-1}X^{\top})^{\top}\\ & =(X^{\top}X)^{-1}X^{\top}\mathrm{Var}\{\bm{y}\}X(X^{\top}X)^{-1}\\ & =(X^{\top}X)^{-1}X^{\top}\sigma^{2}\mathsf{I}X(X^{\top}X)^{-1}\\ & =(X^{\top}X)^{-1}\sigma^{2} \end{aligned} \]
3 手搓线性回归
在 R 语言环境中,矩阵计算的函数是很丰富的,回归系数的计算涉及矩阵的乘法和求逆,分别用内置函数 crossprod() 和 solve() 即可。
y = cars[, "dist"] # 这是一个向量
X = cbind(1, cars[, "speed"]) # 这是一个矩阵
# 回归系数 beta 向量
solve(a = crossprod(X), b = crossprod(X, y))## [,1]
## [1,] -17.579
## [2,] 3.932截矩项和速度变量的系数分别是 -17.579 和 3.932 。所以回归方程如下:
\[ \begin{aligned} \mathrm{dist} = -17.579 + 3.932 \times \mathrm{speed}. \end{aligned} \]
# 系数矩阵 X 的秩
qr(X)$rank## [1] 2# 样本量
nrow(cars)## [1] 50# 投影阵
P = diag(rep(1, nrow(cars))) - X %*% solve(crossprod(X)) %*% t(X)
# sigma 的估计
sqrt((t(y) %*% P %*% y) / (50 - 2))## [,1]
## [1,] 15.384 R 语言函数 lm()
统计计算和建模是 R 语言的核心优势之一,对于线性模型拟合,已有内置函数 lm() 。
fit_lm_cars <- lm(data = cars, dist ~ speed)
# 输出线性模型拟合结果
summary(fit_lm_cars)##
## Call:
## lm(formula = dist ~ speed, data = cars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -29.07 -9.53 -2.27 9.21 43.20
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -17.579 6.758 -2.60 0.012 *
## speed 3.932 0.416 9.46 1.5e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.4 on 48 degrees of freedom
## Multiple R-squared: 0.651, Adjusted R-squared: 0.644
## F-statistic: 89.6 on 1 and 48 DF, p-value: 1.49e-12从模型输出结果来看,线性模型的参数分别是 \(\alpha = -17.579, \beta = 3.932, \sigma = 15.4\) 。这与前面手搓的结果一样。
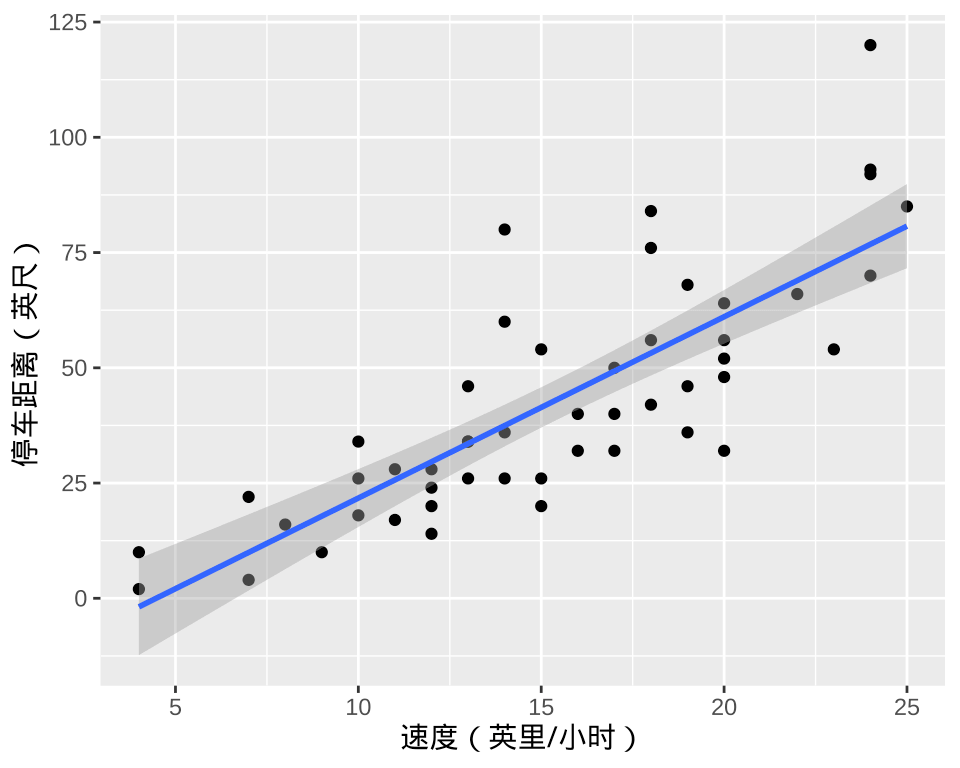
图 4.1: 汽车里程与速度的关系
5 JAGS 软件
JAGS 是一款用于贝叶斯计算的开源免费软件。它的 R 语言接口是 rjags 包,另有一个 coda 包专门处理后验分布采样的数据。
5.1 模型设定
在 cars 数据集中,对距离与速度的关系进行建模,在贝叶斯分析框架下,参数的先验分布做如下设置。
\[ \begin{aligned} \alpha &\sim \mathcal{N}(0, 0.0001) \\ \beta &\sim \mathcal{N}(0, 0.0001) \\ \tau &\sim \Gamma(0.001, 0.001) \\ \sigma &= 1/\sqrt{\tau} \end{aligned} \]
则 \(\tau = 1/\sigma^2\) ,意味着 \(1/\sigma^2 \sim \Gamma(0.001,0.001)\) ,此伽马分布的图像如下。
ggplot() +
geom_function(
fun = dnorm, args = list(mean = 0, sd = 0.0001),
aes(colour = "dnorm"), linewidth = 1.2, xlim = c(-6, 6)
) +
geom_function(
fun = dgamma, args = list(shape = 0.001, scale = 0.001),
aes(colour = "dgamma"), linewidth = 1.2, xlim = c(-6, 6)
) +
theme_classic() +
labs(x = expression(x), y = expression(f(x)), colour = NULL)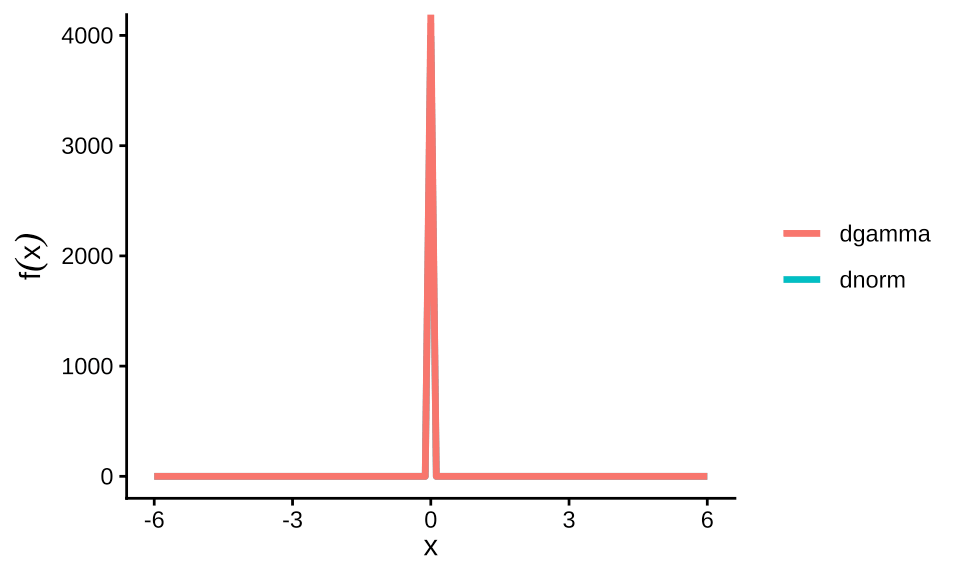
图 5.1: 标准差的先验分布
5.2 模型编码
一个简单线性模型(一元线性回归)的 JAGS 代码如下:
model {
for (i in 1:N) {
Y[i] ~ dnorm(mu[i], tau)
mu[i] <- alpha + beta * x[i]
}
# Prior distribution
alpha ~ dnorm(0.0, 1.0E-4)
beta ~ dnorm(0.0, 1.0E-4)
sigma <- 1.0/sqrt(tau)
tau ~ dgamma(1.0E-3, 1.0E-3)
}模型内容包裹在一对大括号{}内,且有保留的关键词 model 声明。循环控制语句 for 含义和一般编程语言无二,变量可以不先声明类型和初始化即可使用,这和 R 语言的习惯也是一样。JAGS 是用两类关系来表示模型的,一类是表示确定性的关系,对应赋值符号<-,一类是表示随机性的关系,对应等价符号 ~,在 LaTeX 中排版变量独立同分布的数学公式用到命令 \sim ,就是这个符号。JAGS 还定义了很多分布函数,以上代码块用到了正态分布 dnorm 和伽马分布 dgamma 的概率密度函数。
代码中的 x、y 和 N 是需要用户输入的数据。
5.3 模型配置
library(coda)
library(rjags)## Linked to JAGS 4.3.2## Loaded modules: basemod,bugs# 准备数据
line_data <- list(
"x" = cars$speed,
"Y" = cars$dist,
"N" = 50
)
# 初始值
line_inits <- list(
list(".RNG.name" = "base::Marsaglia-Multicarry",
".RNG.seed" = 20222022,
"alpha" = 3, "beta" = 0, "tau" = 1.5),
list(".RNG.name" = "base::Marsaglia-Multicarry",
".RNG.seed" = 20232023,
"alpha" = 0, "beta" = 1, "tau" = 0.375)
)除了数据外,还需要指定随机数生成器,随机数种子(为了结果可重复),各参数的初始值。
5.4 模型训练
当数据、初始值和模型都准备好后,就是在函数 jags.model 里将它们传递给模型,一起训练。
# 模型
model <- jags.model(
file = "code/cars.bugs",
data = line_data,
inits = line_inits,
n.chains = 2 # 两条链
)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 50
## Unobserved stochastic nodes: 3
## Total graph size: 148
##
## Initializing model# burn-in 初始迭代次数
update(model, n.iter = 500)训练时,会输出模型的信息。 JAGS 将贝叶斯模型看成一个有层次的模型图。
Observed stochastic nodes: 50观测数据 50 条记录,根据模型结构表达观测数据的隐含模式,模型含有未知参数,即随机变量。Unobserved stochastic nodes: 3模型未知参数 3 个,对应 3 个先验分布。在贝叶斯框架下,未知参数都是随机变量,需要指定先验分布。
5.5 模型输出
函数 coda.samples() 对参数 \(\alpha,\beta,\sigma\) 做 Gibbs 抽样。下面设置迭代 1000 次,每次迭代的值都采样。
# 抽样
samples <- coda.samples(model,
variable.names = c("alpha", "beta", "sigma"),
thin = 1, # 采样间隔
n.iter = 1000 # 迭代次数
)
# 参数的后验估计
summary(samples)##
## Iterations = 501:1500
## Thinning interval = 1
## Number of chains = 2
## Sample size per chain = 1000
##
## 1. Empirical mean and standard deviation for each variable,
## plus standard error of the mean:
##
## Mean SD Naive SE Time-series SE
## alpha -17.95 6.967 0.15579 0.6511
## beta 3.95 0.429 0.00959 0.0416
## sigma 15.63 1.643 0.03674 0.0390
##
## 2. Quantiles for each variable:
##
## 2.5% 25% 50% 75% 97.5%
## alpha -31.43 -22.58 -17.66 -13.25 -4.77
## beta 3.15 3.67 3.94 4.23 4.79
## sigma 12.79 14.45 15.46 16.64 19.20除了输出采样的信息,此外,还有采样结果,也就是参数的贝叶斯估计。
从输出结果来看,\(\alpha = -17.95, \beta = 3.95, \sigma = 15.63\) ,这和前面函数 lm() 计算的结果是很接近的。
5.6 后验分布
模型训练得到一个 mcmc.list 类型的列表,coda 包专为操作此数据。
class(samples)## [1] "mcmc.list"str(samples)## List of 2
## $ : 'mcmc' num [1:1000, 1:3] -15.7 -14.1 -16.2 -15.4 -13.6 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:3] "alpha" "beta" "sigma"
## ..- attr(*, "mcpar")= num [1:3] 501 1500 1
## $ : 'mcmc' num [1:1000, 1:3] -9.52 -12.09 -8.87 -11.15 -12.11 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:3] "alpha" "beta" "sigma"
## ..- attr(*, "mcpar")= num [1:3] 501 1500 1
## - attr(*, "class")= chr "mcmc.list"这个列表存储了模型参数在采样过程中的迭代值,两条链对应列表的两个元素,每个元素是一个二维矩阵。了解了这个数据结构后,下面查看第一条链模型三个参数 \(\alpha,\beta,\sigma\) 的前几个迭代值。
head(samples[[1]])## Markov Chain Monte Carlo (MCMC) output:
## Start = 501
## End = 507
## Thinning interval = 1
## alpha beta sigma
## [1,] -15.73 3.776 13.90
## [2,] -14.14 3.680 14.77
## [3,] -16.21 4.065 13.46
## [4,] -15.35 3.710 14.18
## [5,] -13.64 3.754 13.74
## [6,] -10.48 3.291 13.06
## [7,] -11.63 3.827 17.375.6.1 参数区间估计
参数后验区间估计,前面设置了两条马尔可夫迭代链,所以输出两个结果,两个结果是很接近的。
# Highest Posterior Density intervals
HPDinterval(samples)## [[1]]
## lower upper
## alpha -30.444 -4.305
## beta 3.136 4.784
## sigma 12.784 19.109
## attr(,"Probability")
## [1] 0.95
##
## [[2]]
## lower upper
## alpha -31.539 -4.875
## beta 3.155 4.759
## sigma 12.593 18.908
## attr(,"Probability")
## [1] 0.955.6.2 参数后验分布
coda 包可视化参数的迭代轨迹图和后验概率密度图。
每个参数的后验分布的概率密度图,两条链。
library(lattice)
# 密度图
densityplot(samples)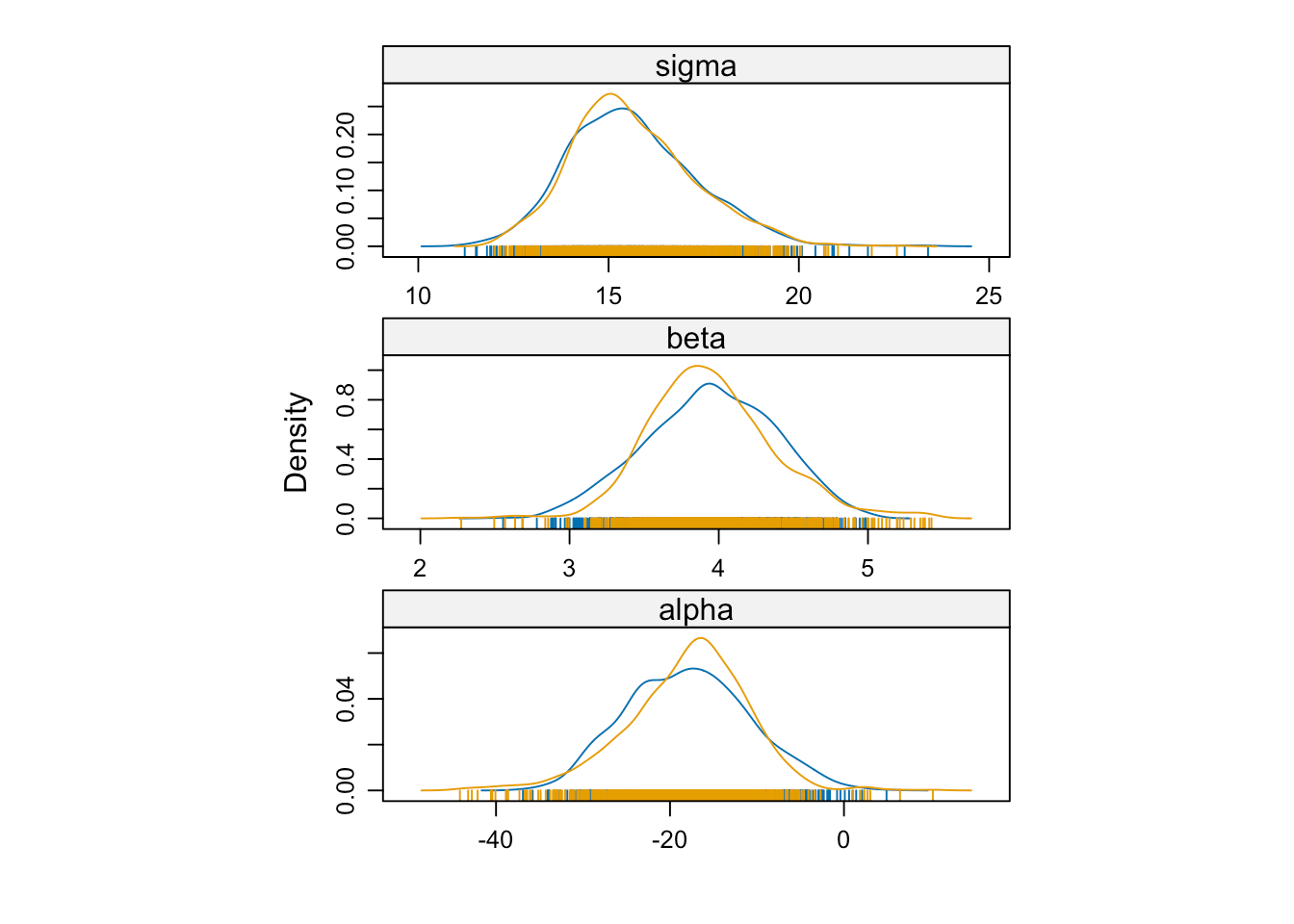
图 5.2: 后验分布的概率密度图
每个参数的迭代序列,看作一个时间序列,这个时间序列应该是平稳的。
# 自相关图
acfplot(samples)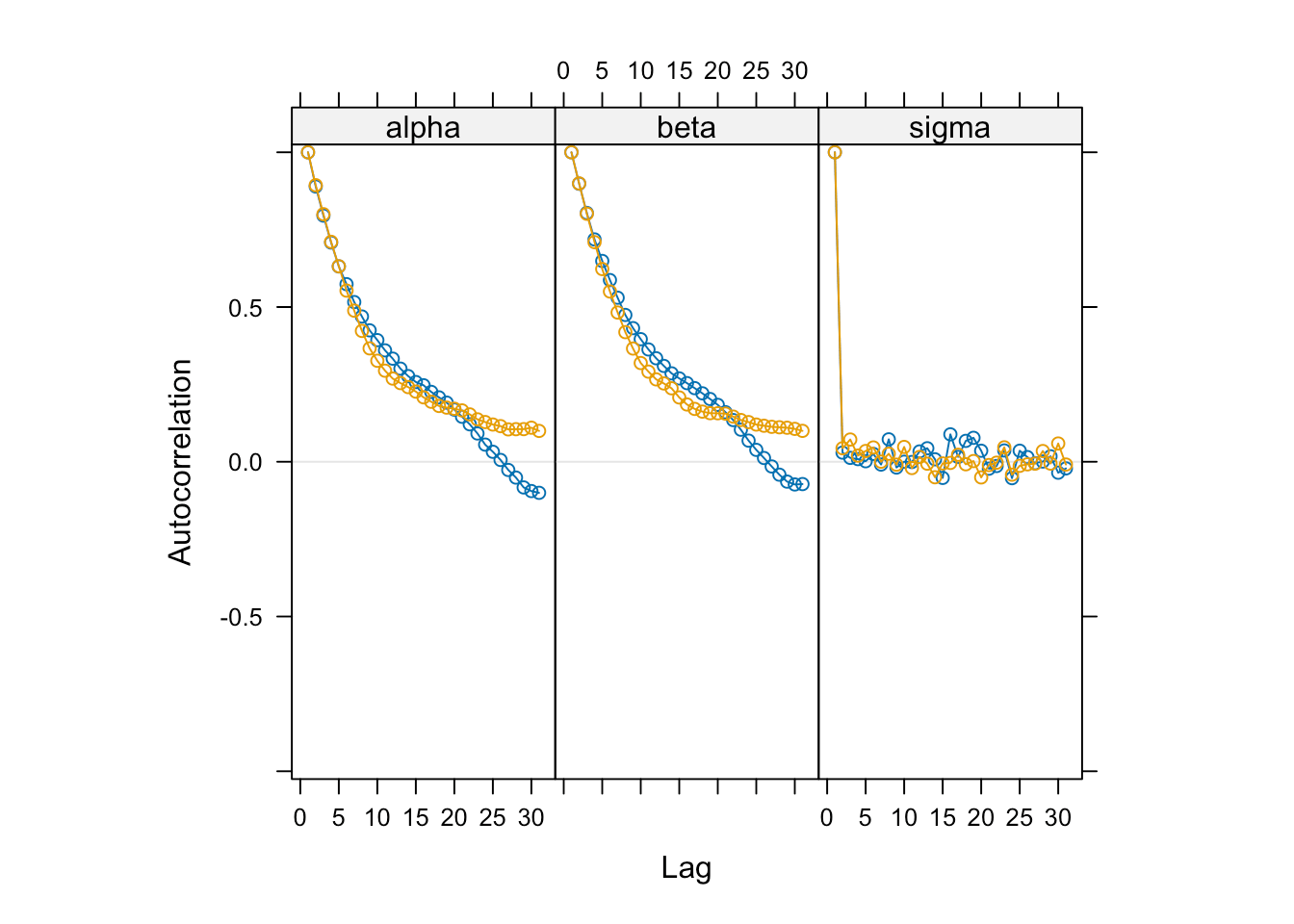
图 5.3: 迭代序列的自相关图
5.7 模型诊断
5.7.1 潜在尺度缩减因子
Gelman and Rubin’s 收缩因子随迭代次数的变化。
gelman.plot(samples)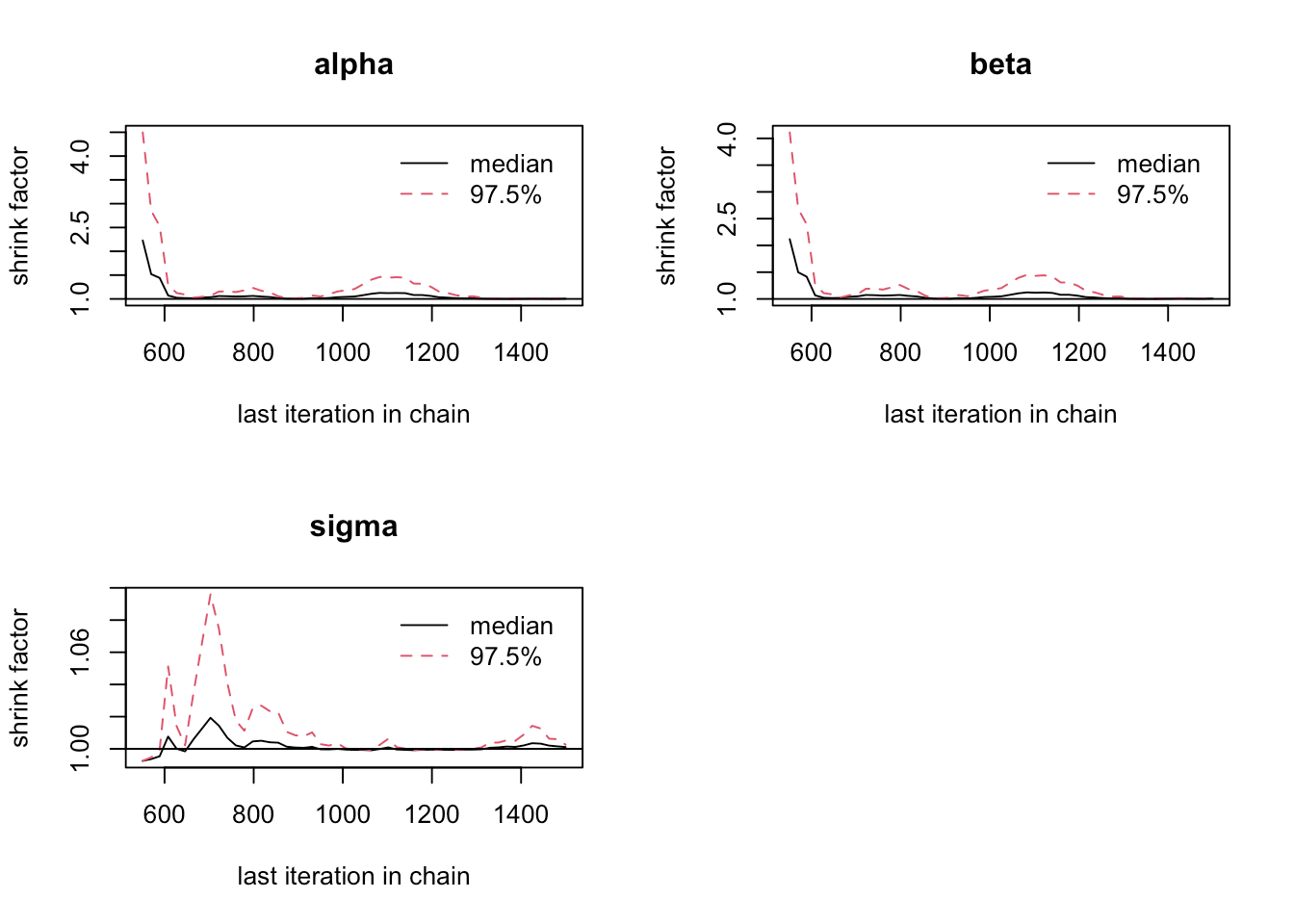
图 5.4: Gelman-Rubin-Brooks 图
Gelman and Rubin 收敛性诊断,潜在尺度缩减因子(Potential Scale Reduction Factors,简称 psrf),也就是通常所说的 \(\hat{R}\) ,它要越接近 1 越好,表示迭代序列混合效果好。
gelman.diag(samples, confidence = 0.95)## Potential scale reduction factors:
##
## Point est. Upper C.I.
## alpha 1.01 1.01
## beta 1.01 1.01
## sigma 1.00 1.00
##
## Multivariate psrf
##
## 15.7.2 有效样本量 ESS
ESS 表示 Effective sample size for estimating the mean 参数后验均值估计的有效样本量。
effectiveSize(samples)## alpha beta sigma
## 114.6 106.4 1794.75.8 模型评估
5.8.1 DIC
Generate penalized deviance samples
dic.samples(model, n.iter = 1000)## Mean deviance: 416
## penalty 3.05
## Penalized deviance: 4196 CmdStan 软件
CmdStan 是 Stan 的命令行接口,cmdstanr 包是 CmdStan 的 R 语言接口。
6.1 编码模型
Stan 编码的线性模型如下:
data {
int<lower=0> N; // number of data items
int<lower=0> K; // number of predictors
matrix[N, K] x; // predictor matrix
vector[N] y; // outcome vector
}
parameters {
real alpha; // intercept
vector[K] beta; // coefficients for predictors
real<lower=0> sigma; // error scale
}
model {
// alpha ~ normal(0, 1); // prior
// beta ~ normal(0, 1); // prior
y ~ normal(x * beta + alpha, sigma); // likelihood
}
generated quantities {
vector[N] log_lik; // pointwise log-likelihood for LOO
vector[N] y_rep; // replications from posterior predictive dist
for (i in 1 : N) {
real y_hat_i = alpha + x[i] * beta;
log_lik[i] = normal_lpdf(y[i] | y_hat_i, sigma);
y_rep[i] = normal_rng(y_hat_i, sigma);
}
}6.2 编译模型
# 不检查新版 CmdStan
Sys.setenv(cmdstanr_no_ver_check=TRUE)
library(cmdstanr)
# 编译模型
mod_cars <- cmdstan_model(
stan_file = "code/cars.stan",
compile = TRUE,
cpp_options = list(stan_threads = TRUE)
)6.3 准备数据
# 准备数据
cars_d <- list(
N = nrow(cars), # 观测记录的条数
K = 1, # 协变量个数
x = cars[, "speed", drop = F], # N x 1 矩阵
y = cars[, "dist"] # N 向量
)
nchains <- 2 # 2 条迭代链
# 给每条链设置不同的参数初始值
inits_data <- lapply(1:nchains, function(i) {
list(
alpha = runif(1, 0, 1),
beta = runif(1, 0, 1),
sigma = runif(1, 1, 10)
)
})6.4 训练模型
采样拟合模型
# 采样拟合模型
fit_cars <- mod_cars$sample(
data = cars_d, # 观测数据
init = inits_data, # 迭代初值
iter_warmup = 500, # 每条链预处理迭代次数
iter_sampling = 1000, # 每条链总迭代次数
chains = nchains, # 马尔科夫链的数目
parallel_chains = 1, # 指定 CPU 核心数,可以给每条链分配一个
threads_per_chain = 1, # 每条链设置一个线程
show_messages = FALSE, # 不显示迭代的中间过程
refresh = 0, # 不显示采样的进度
seed = 20190425 # 设置随机数种子,不要使用 set.seed() 函数
)6.5 模型输出
模型参数估计结果如下:
| variable | mean | median | sd | mad | q5 | q95 | rhat | ess_bulk | ess_tail |
|---|---|---|---|---|---|---|---|---|---|
| alpha | -17.850 | -17.841 | 6.868 | 6.719 | -29.072 | -6.495 | 1.002 | 622.3 | 719.1 |
| beta[1] | 3.953 | 3.956 | 0.424 | 0.426 | 3.273 | 4.645 | 1.002 | 608.6 | 731.0 |
| sigma | 15.712 | 15.610 | 1.573 | 1.498 | 13.265 | 18.491 | 1.004 | 970.6 | 1083.4 |
| lp__ | -159.428 | -159.097 | 1.246 | 0.998 | -161.885 | -158.103 | 1.003 | 594.5 | 772.0 |
6.6 后验分布
6.6.1 参数迭代轨迹图
library(bayesplot)
## This is bayesplot version 1.15.0
## - Online documentation and vignettes at mc-stan.org/bayesplot
## - bayesplot theme set to bayesplot::theme_default()
## * Does _not_ affect other ggplot2 plots
## * See ?bayesplot_theme_set for details on theme setting
mcmc_trace(fit_cars$draws(c("alpha", "beta")),
facet_args = list(
labeller = ggplot2::label_parsed, strip.position = "top", ncol = 1
)
) + theme_bw(base_size = 12)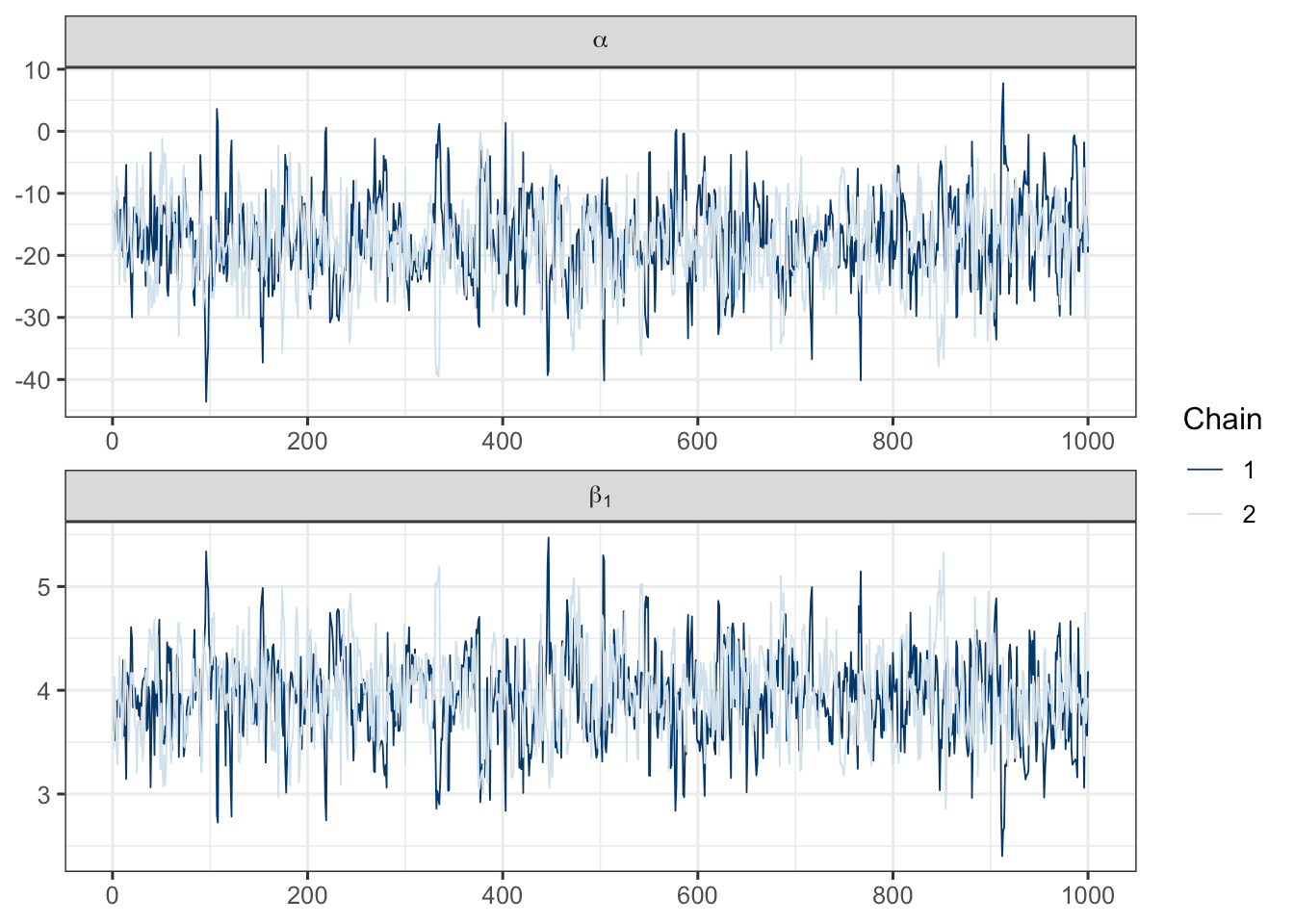
图 6.1: 参数迭代轨迹图
6.6.2 参数后验分布图
mcmc_dens(fit_cars$draws(c("alpha", "beta")),
facet_args = list(
labeller = ggplot2::label_parsed, strip.position = "top", ncol = 1
)
) + theme_bw(base_size = 12)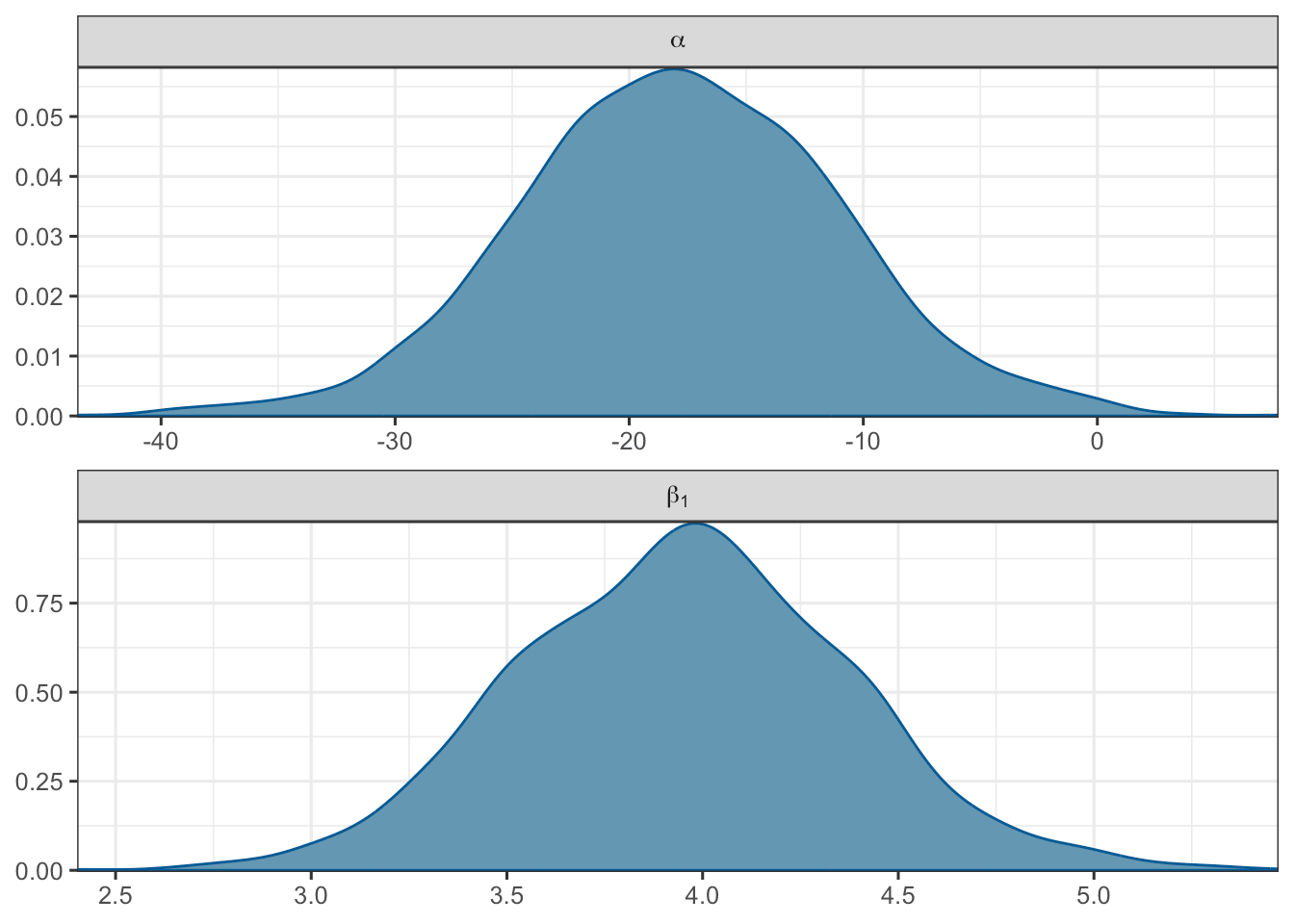
图 6.2: 参数后验分布图
6.7 模型诊断
6.7.1 潜在尺度收缩因子
潜在尺度收缩因子 \(\hat{R}\)
bayesplot::rhat(fit_cars, pars = c("alpha", "beta", "sigma"))## alpha beta[1] sigma
## 1.002 1.002 1.004rhat 值越接近 1 越好。
6.7.2 有效样本量
neff_ratio 衡量采样效率,有效样本比率。
bayesplot::neff_ratio(fit_cars, pars = c("alpha", "beta", "sigma"))## alpha beta[1] sigma
## 0.3096 0.3043 0.48586.8 模型评估
6.8.1 WAIC
fit_cars_waic <- loo::waic(fit_cars$draws(variables = "log_lik"))## Warning:
## 2 (4.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.print(fit_cars_waic)##
## Computed from 2000 by 50 log-likelihood matrix.
##
## Estimate SE
## elpd_waic -209.9 6.3
## p_waic 3.3 1.2
## waic 419.8 12.7
##
## 2 (4.0%) p_waic estimates greater than 0.4. We recommend trying loo instead.6.8.2 LOOIC
fit_cars_loo <- fit_cars$loo(variables = "log_lik", cores = 2)
print(fit_cars_loo)##
## Computed from 2000 by 50 log-likelihood matrix.
##
## Estimate SE
## elpd_loo -209.9 6.3
## p_loo 3.3 1.2
## looic 419.9 12.7
## ------
## MCSE of elpd_loo is 0.1.
## MCSE and ESS estimates assume MCMC draws (r_eff in [0.4, 1.1]).
##
## All Pareto k estimates are good (k < 0.7).
## See help('pareto-k-diagnostic') for details.7 运行环境
本文用到的 JAGS 版本为 4.3.2,CmdStan 版本为 2.37.0。
xfun::session_info(
packages = c("ggplot2", "rjags", "coda", "cmdstanr", "bayesplot", "lattice", "loo"),
dependencies = F
)## R version 4.5.3 (2026-03-11)
## Platform: aarch64-apple-darwin20
## Running under: macOS Tahoe 26.4.1
##
## Locale: en_US.UTF-8 / en_US.UTF-8 / en_US.UTF-8 / C / en_US.UTF-8 / en_US.UTF-8
##
## Package version:
## bayesplot_1.15.0 cmdstanr_0.9.0 coda_0.19-4.1 ggplot2_4.0.2
## lattice_0.22-9 loo_2.9.0 rjags_4-17