空间数据主要分为三大类:
- 空间区域数据 Areal data
- 空间离散区域上的聚合数据,如行政区划上的人均收入。
- 空间点模式数据 Point pattern data
- 空间位置是随机的,如北京市出租车的位置。
- 空间点参考数据/地统计数据 Point-referenced data
- 空间位置是固定的,如北京市各小区疫苗接种率分布。
描述数据的空间分布是很常见的任务,展示区域数据的图形有地区分布图、比例符号图和变形地图等,展示点过程和地统计数据有热力分布图、地形轮廓图、三维地形图等。下面以 R 软件内置的数据集 state.x77 为例展示 1975 年美国各州人口密度 — 每平方英里的人口数。state.x77 数据集的 Population 列代表州人口数,数据来自 1977 年美国人口调查局发布的统计数据,单位是 1000 人,统计的是 1975 年的人口数据,原始数据可以从官网发布的年度报告Statistical Abstract of the United States: 1977获取。
library(sf)
#> Linking to GEOS 3.10.2, GDAL 3.4.2, PROJ 8.2.1; sf_use_s2() is TRUE
# 美国州级多边形边界地图
us_state_map <- readRDS(file = "data/us-state-map-2010.rds")
# 将观测数据与地图数据合并
state_x77 <- data.frame(state.x77,
state_name = rownames(state.x77),
state_region = state.region,
state_abb = state.abb,
check.names = FALSE
)
us_state_df <- merge(us_state_map, state_x77,
by.x = "NAME", by.y = "state_name", all.x = TRUE
)
# 计算人口密度
us_state_df <- within(us_state_df, {
den <- 1000 * Population / Area
})1 地区分布图
基于 sf 包,ggplot2 包提供图层 geom_sf() 专门用于绘制空间矢量数据,可以展示空间点、多边形和线等三类常见几何数据。如图所示,展示 1975 年美国各州人口密度(单位:每平方英里人口数)。
library(ggplot2)
ggplot() +
geom_sf(
data = us_state_df, aes(fill = den),
color = "gray80", lwd = 0.25
) +
scale_fill_viridis_c(
trans = "log10", option = "plasma",
na.value = "white"
) +
labs(
fill = "人口密度", title = "1975 年美国各州人口密度",
caption = "数据源:美国人口调查局"
) +
theme_void() +
theme(plot.title = element_text(hjust = 0.5))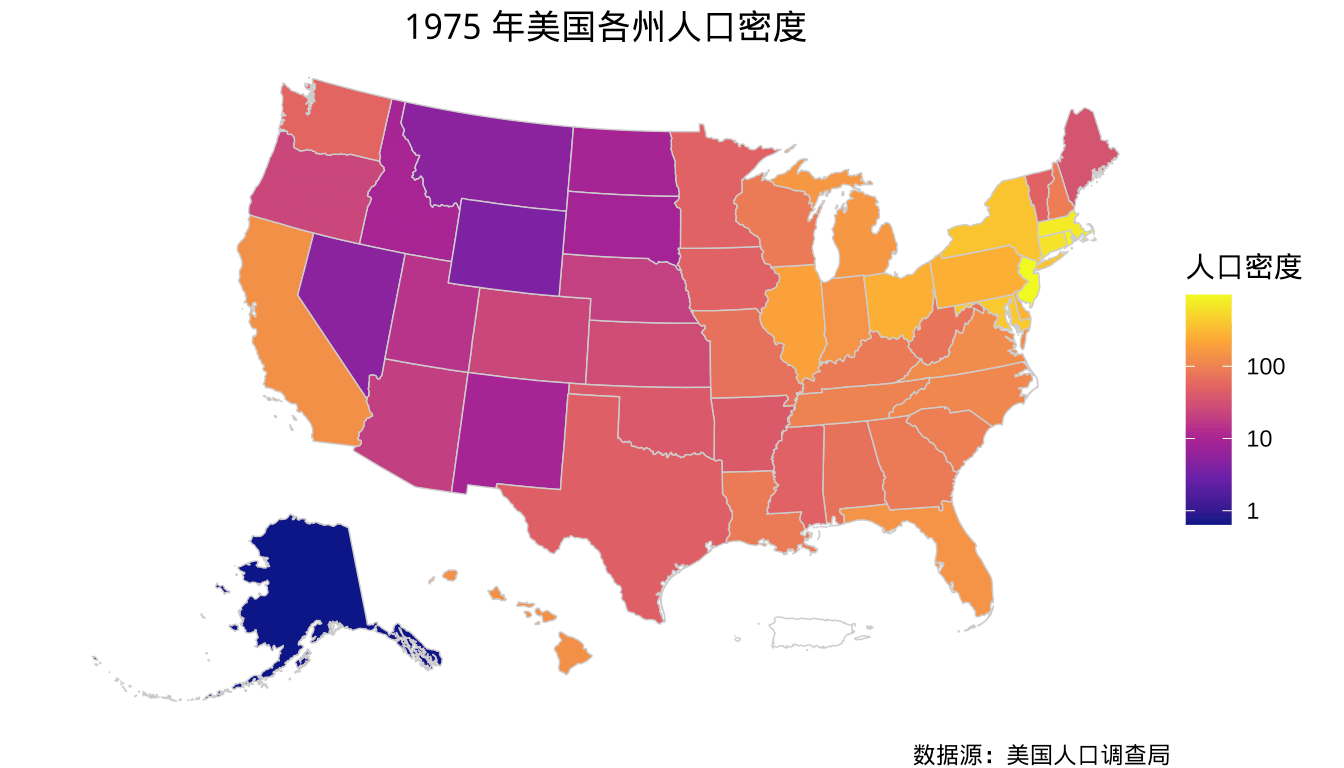
图 1.1: 1975 年美国各州人口密度
将人均 GDP 和预期寿命分段,借助 biscale 包构造二维的图例,以二维地区分布图展示预期寿命和人均 GDP 的空间相关性。
library(biscale)
# 将数据根据分位点分箱
us_bi_data <- bi_class(us_state_df[!is.na(us_state_df$Income),],
x = Income, y = `Life Exp`,
style = "quantile", dim = 3
)
# 创建主体地图
us_bi_map <- ggplot() +
geom_sf(data = us_state_df, color = "gray80", fill = I("white")) +
geom_sf(
data = us_bi_data, aes(fill = bi_class),
color = "white", linewidth = 0.05, show.legend = FALSE
) +
bi_scale_fill(pal = "DkViolet2", dim = 3) +
theme_void() +
theme(plot.title = element_text(hjust = 0.5))
# 创建图例数据
us_bi_leg_data <- data.frame(expand.grid(x = 1:3, y = 1:3),
bi_fill = biscale::bi_pal(pal = "DkViolet2", dim = 3, preview = FALSE)
)
# 绘制二元图例的函数 bi_legend 不支持中文,因此改其源代码
# 创建图例瓦片
us_bi_leg <- ggplot(
data = us_bi_leg_data,
aes(x = x, y = y, fill = bi_fill)
) +
geom_tile() +
scale_fill_identity() +
labs(
x = substitute(paste("人均 GDP", "" %->% "")),
y = substitute(paste("预期寿命", "" %->% ""))
) +
coord_fixed() +
theme_void() +
theme(
axis.title = element_text(size = 8),
axis.title.y = element_text(angle = 90)
)
library(patchwork)
# 组合图形
us_bi_map + inset_element(us_bi_leg,
left = 0.875, bottom = 0, right = 1, top = 0.35
)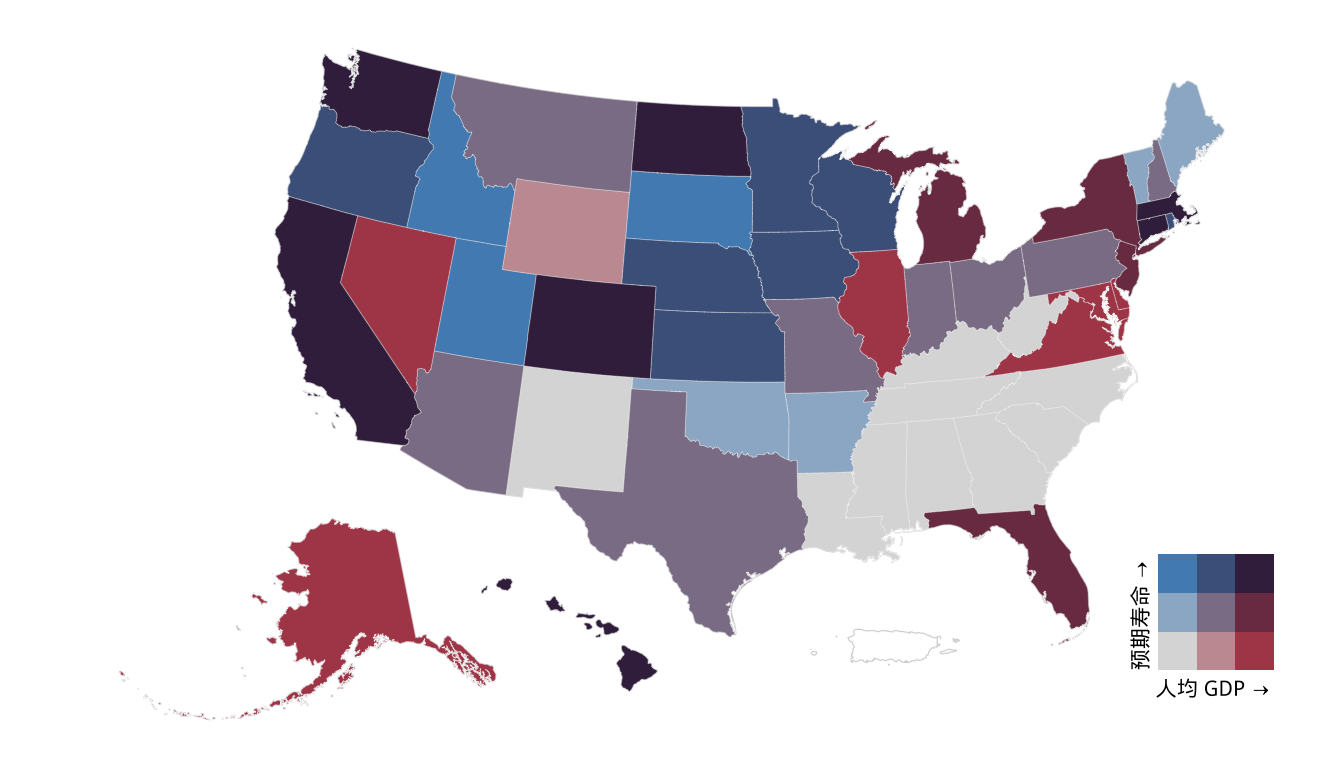
图 1.2: 预期寿命与人均 GDP 的空间相关性
2 比例符号图
1975 年美国各州人口密度,单位为每平方英里人口数,人口密度映射为气泡的面积,美国划分为东北部、南方、西部、中北部四个区域,如图所示。
ggplot() +
geom_sf(
data = us_state_df, fill = NA, aes(color = state_region)
) +
labs(title = "美国各州的区域划分", color = "区域划分",
caption = "数据源:美国人口调查局") +
theme_void() +
theme(plot.title = element_text(hjust = 0.5))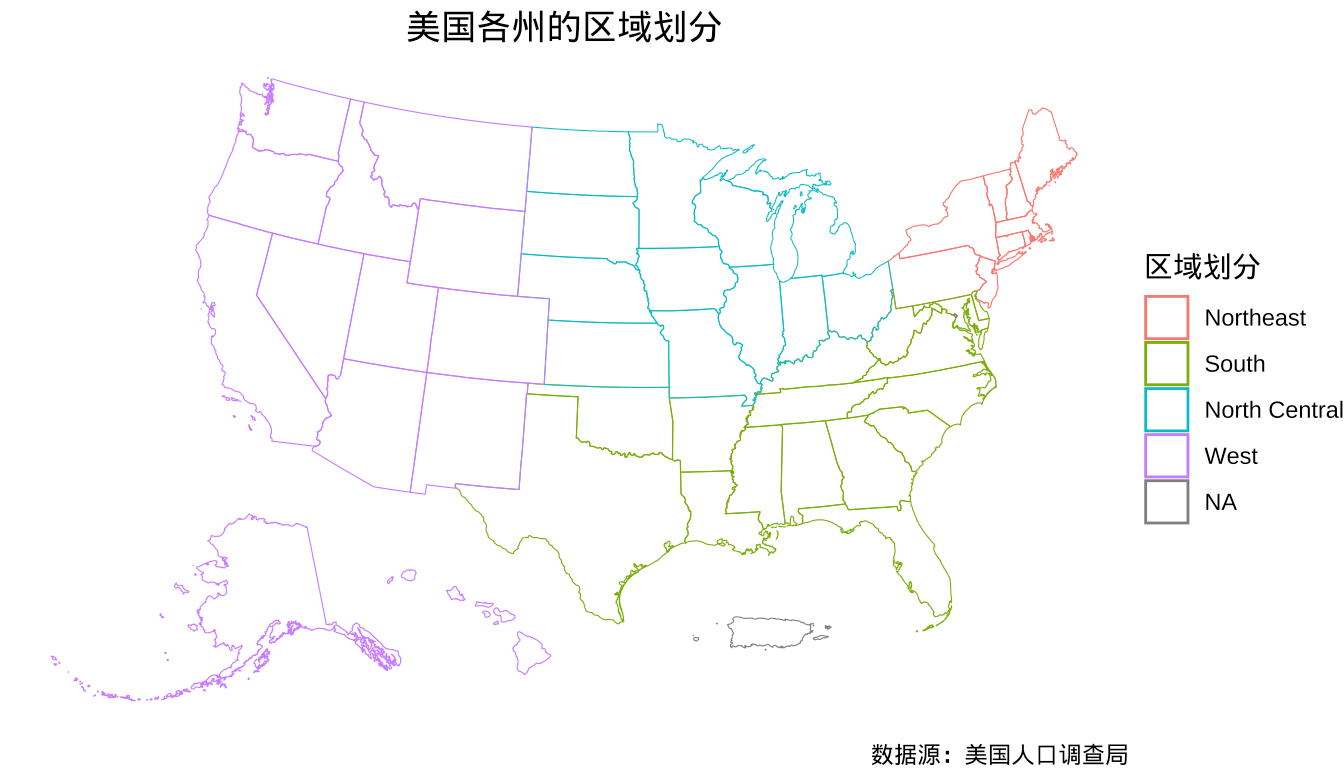
图 2.1: 美国各州的区域划分
在上图的基础上,添加各州州名的缩写,比如 New York 缩写为 NY,这非常类似于我国对各省的简称,比如湖南省简称为湘。
ggplot() +
geom_sf(
data = us_state_df, fill = NA, aes(color = state_region)
) +
geom_sf_label(data = us_state_df, aes(label = state_abb),
size = 3, na.rm = T) +
labs(
title = "美国各州的区域划分", color = "区域划分",
caption = "数据源:美国人口调查局"
) +
theme_void() +
theme(plot.title = element_text(hjust = 0.5))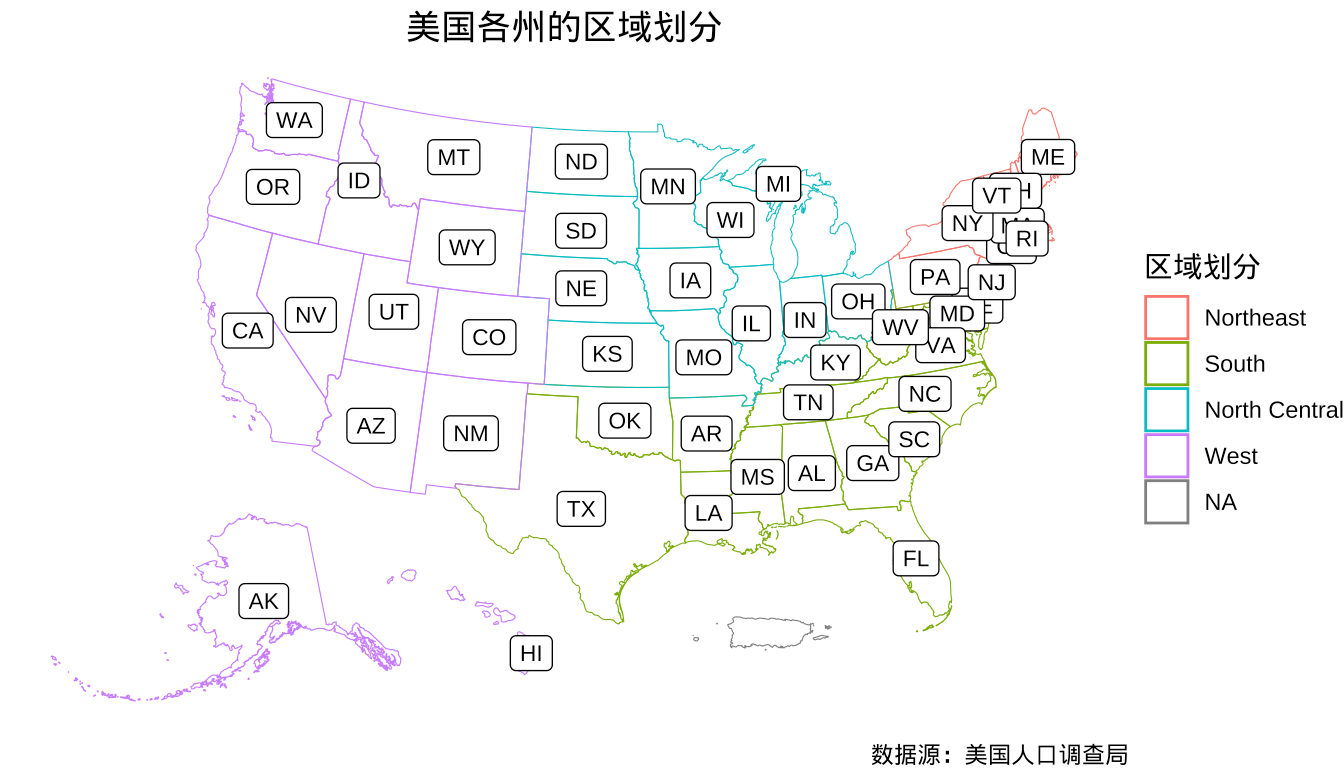
图 2.2: 美国各州的区域划分
对了解美国地图的人来说,在已有各州边界及区域划分的信息下,在图上添加各州名称就会显得多余,而对缺乏了解的人来说,则是有用的。绘图区域是有限的,信息自然可以越堆越多,关键是这个图形想要传递什么信息,应该优先保障重点突出。此例是以比例符号图展示美国各州人口密度的分布,重点便是展示人口密度数据,如图所示。
us_state_df <- within(us_state_df, {
geometry_center <- st_centroid(geometry)
})
library(ggnewscale)
ggplot() +
geom_sf(
data = us_state_df, fill = NA, aes(color = state_region)
) +
labs(color = "区域划分") +
new_scale_color() +
geom_sf(
data = us_state_df,
aes(geometry = geometry_center, color = den, size = den),
show.legend = c(color = FALSE, size = TRUE), na.rm = TRUE
) +
scale_color_viridis_c(
trans = "log10", option = "plasma", na.value = "white"
) +
labs(
title = "1975 年美国各州人口密度", size = "人口密度",
caption = "数据源:美国人口调查局"
) +
theme_void() +
theme(plot.title = element_text(hjust = 0.5))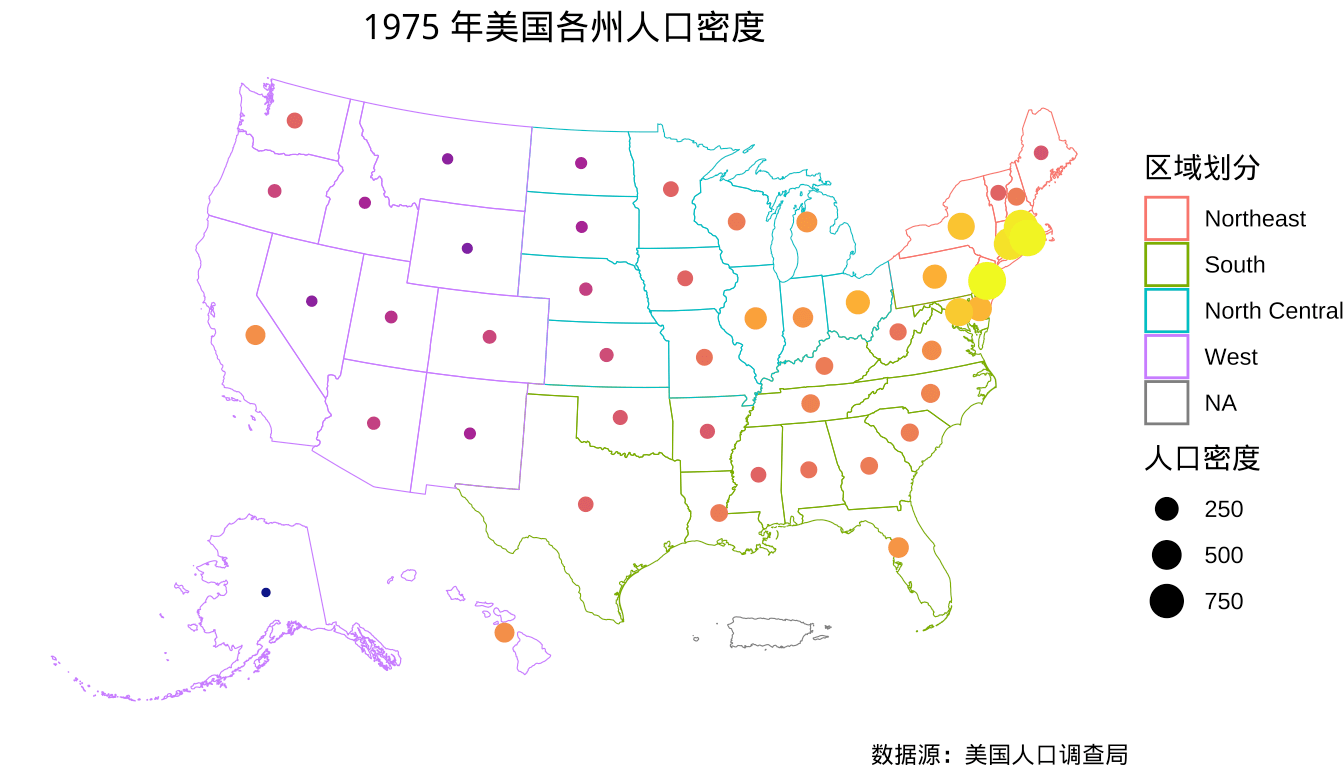
图 2.3: 1975 年美国各州人口密度
在州名数量有限的情况下,特别是用一页纸可以完全展示的情况,还可以考虑用分组条形图替代地区分布图或比例符号图,好处是人口密度的对比更加突出,也避免美国东北部各州因面积小、人口密度大导致的气泡相互重叠的问题。
# 按区域分组后按人口密度排序
us_state_df <- us_state_df[with(us_state_df, order(state_region, -den)), ]
# 添加新列记录排序后的序号
us_state_df$rowid <- 1:nrow(us_state_df)
# 绘图
ggplot(
data = us_state_df,
aes(x = den, y = reorder(NAME, rowid, FUN = function(x) 1 / (1 + x)))
) +
geom_col(aes(fill = state_region)) +
theme_classic() +
labs(
x = "人口密度", y = "州名", fill = "区域划分",
title = "1975 年美国各州人口密度",
caption = "数据源:美国人口调查局"
)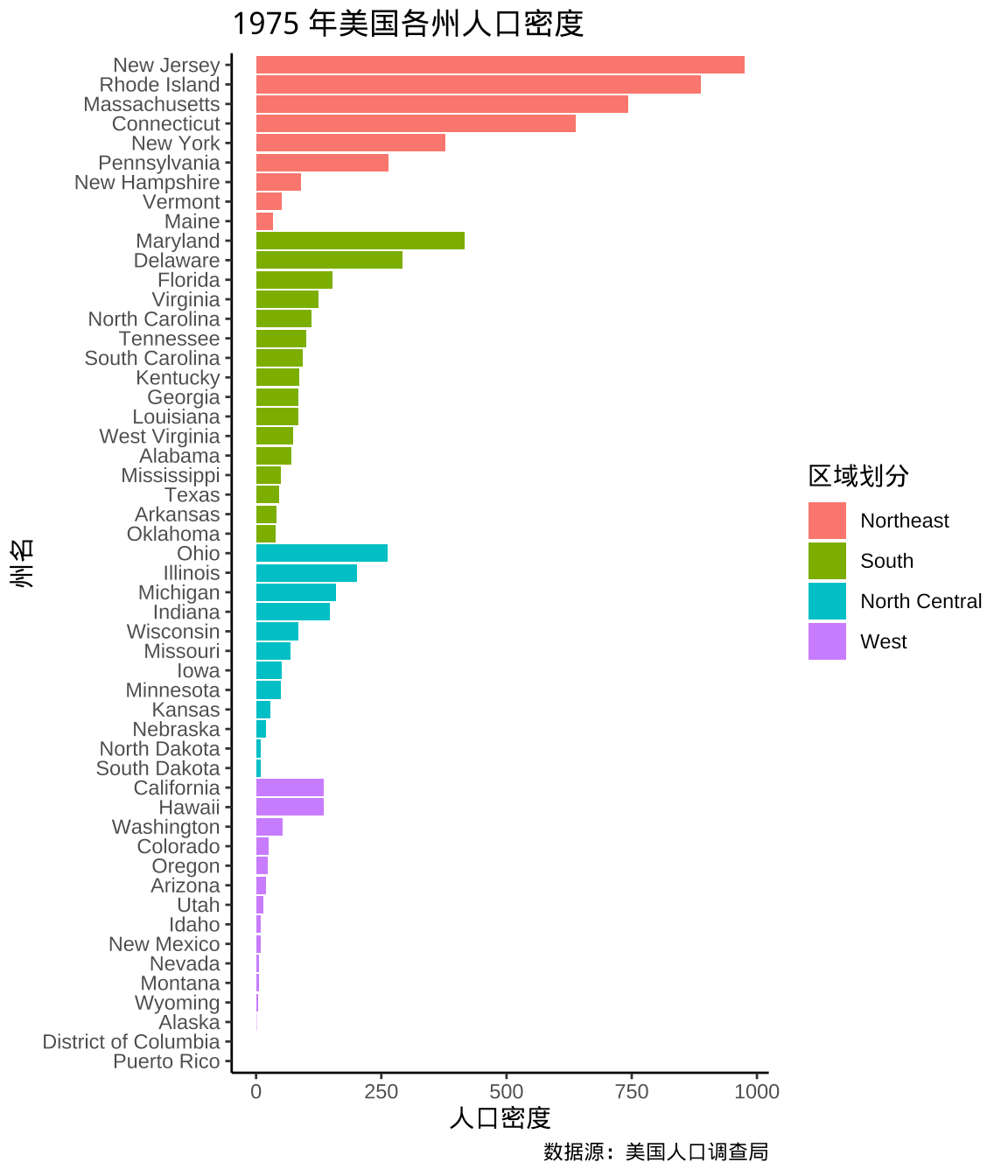
图 2.4: 1975 年美国各州人口密度
3 扭曲变形图
变形地图中变形的是多边形地理边界,从而将数据映射到地理区域的面积上。cartogram 包提供变形算法构造变形地图,如 图所示,根据各州的多边形边界地图数据和人口密度数据构造新的多边形边界地图。
library(cartogram)
# 构造变形地图
us_state_carto <- cartogram_cont(us_state_df, weight = "den", itermax = 5)
# 绘制变形地图
ggplot(us_state_carto) +
geom_sf(aes(fill = den), color = "gray80", lwd = 0.25) +
scale_fill_viridis_c(
trans = "log10", option = "plasma",
na.value = "white"
) +
labs(
fill = "人口密度", title = "1975 年美国各州人口密度",
caption = "数据源:美国人口调查局"
) +
theme_void() +
theme(plot.title = element_text(hjust = 0.5))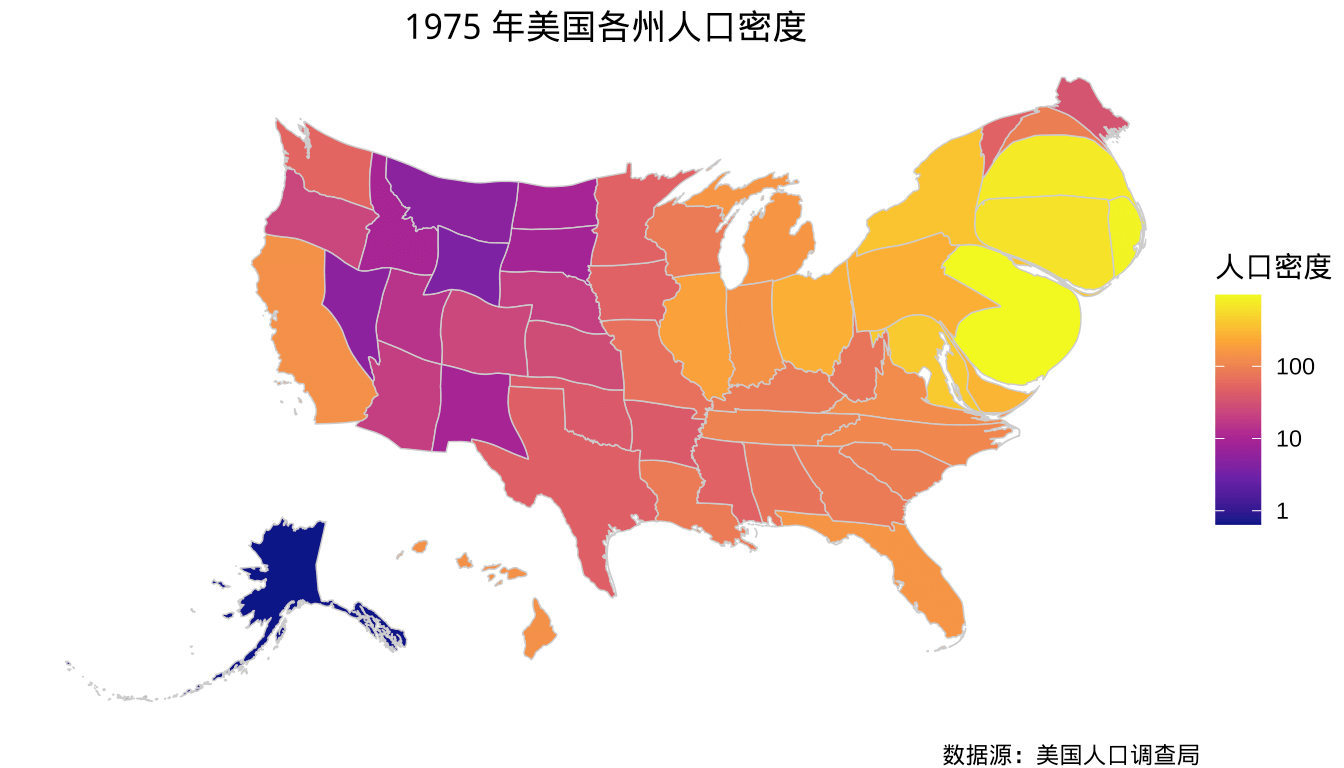
图 3.1: 1974 年美国各州人口密度分布
根据 1974 年各州的人均收入,将收入划分为低收入(低于3500)、中低收入(3500-4500)、中高收入 (4500-5500)、高收入(5500 以上)四档。
# 将连续型的收入分段
state_x77$Income_break <- cut(state_x77$Income,
breaks = 4,
labels = c("低收入", "中低收入", "中高收入", "高收入")
)statebins 包以小方块表示美国各州,小方块的位置根据各州的相对位置摆放,各州的边界和面积不再有意义,而小方块的填充色表示数值的大小,如图所示,展示 1974 年美国各州人均收入的空间分布。
library(statebins)
# 绘制变形地图
ggplot(data = state_x77, aes(state = state_name, fill = Income_break)) +
geom_statebins() +
scale_fill_brewer(palette = "RdPu") +
theme_statebins() +
labs(title = "1974年美国各州人均收入分布", fill = "收入水平") +
theme(plot.title = element_text(hjust = 0.5),
plot.margin = margin(10, 10, 10, 10))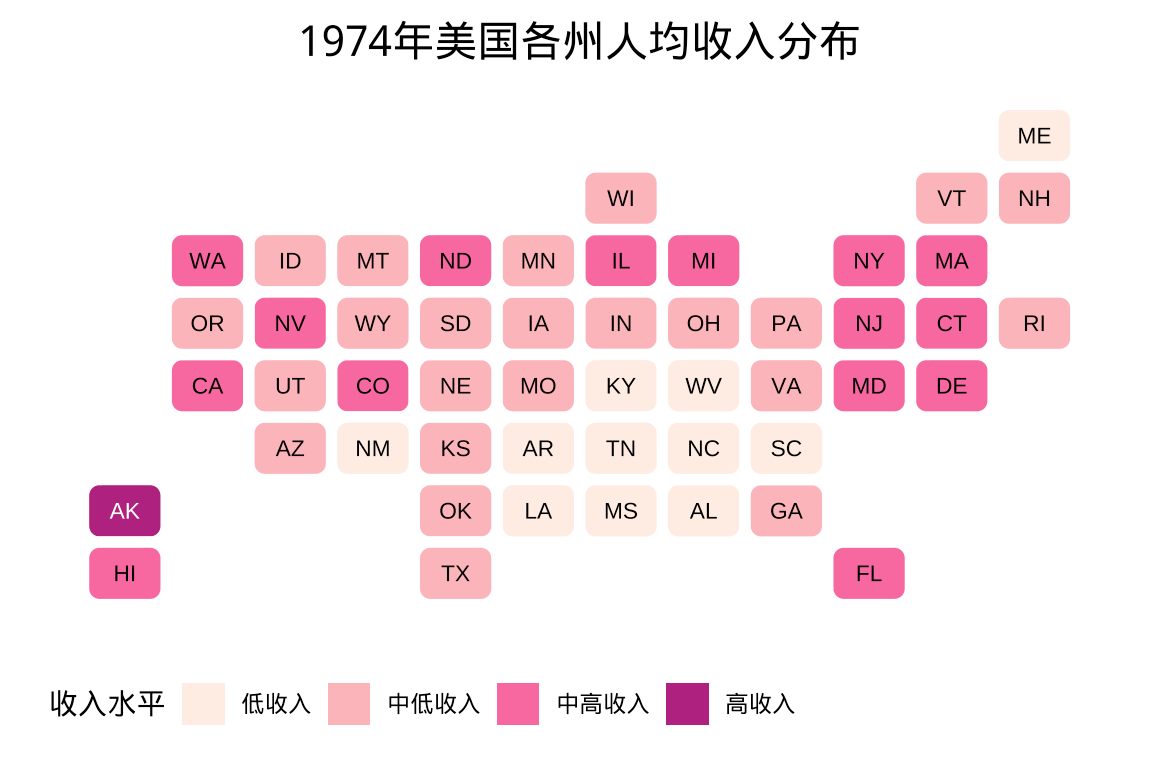
图 3.2: 1974 年美国各州人均收入分布
在 ggplot2 包分面函数 facet_grid() 的基础上,根据美国各州的相对位置, geofacet 包提供函数 facet_geo() 支持更加丰富的信息展示。下图展示美国各州的失业率分布,每个下方块代表一个州各个郡县的失业率分布。 geofacet 包内置的地图不包含 Puerto Rico(波多黎各)地区,因此该地区的失业率数据无法显示。
library(maps)
# 失业率数据
data(unemp)
# 州、郡县名称及编码
fips_codes <- tidycensus::fips_codes
fips_codes$fips <- as.integer(paste0(fips_codes$state_code, fips_codes$county_code))
unemp_df <- merge(unemp, fips_codes, by = "fips")
library(geofacet)
ggplot(unemp_df, aes(x = unemp)) +
geom_histogram(aes(fill = after_stat(count)),
binwidth = 1, show.legend = FALSE
) +
scale_fill_viridis_c(option = "plasma") +
facet_geo(~state) +
theme_bw() +
labs(x = "失业率", y = "郡县数量")
#> Some values in the specified facet_geo column 'state' do not
#> match the 'code' column of the specified grid and will be
#> removed: PR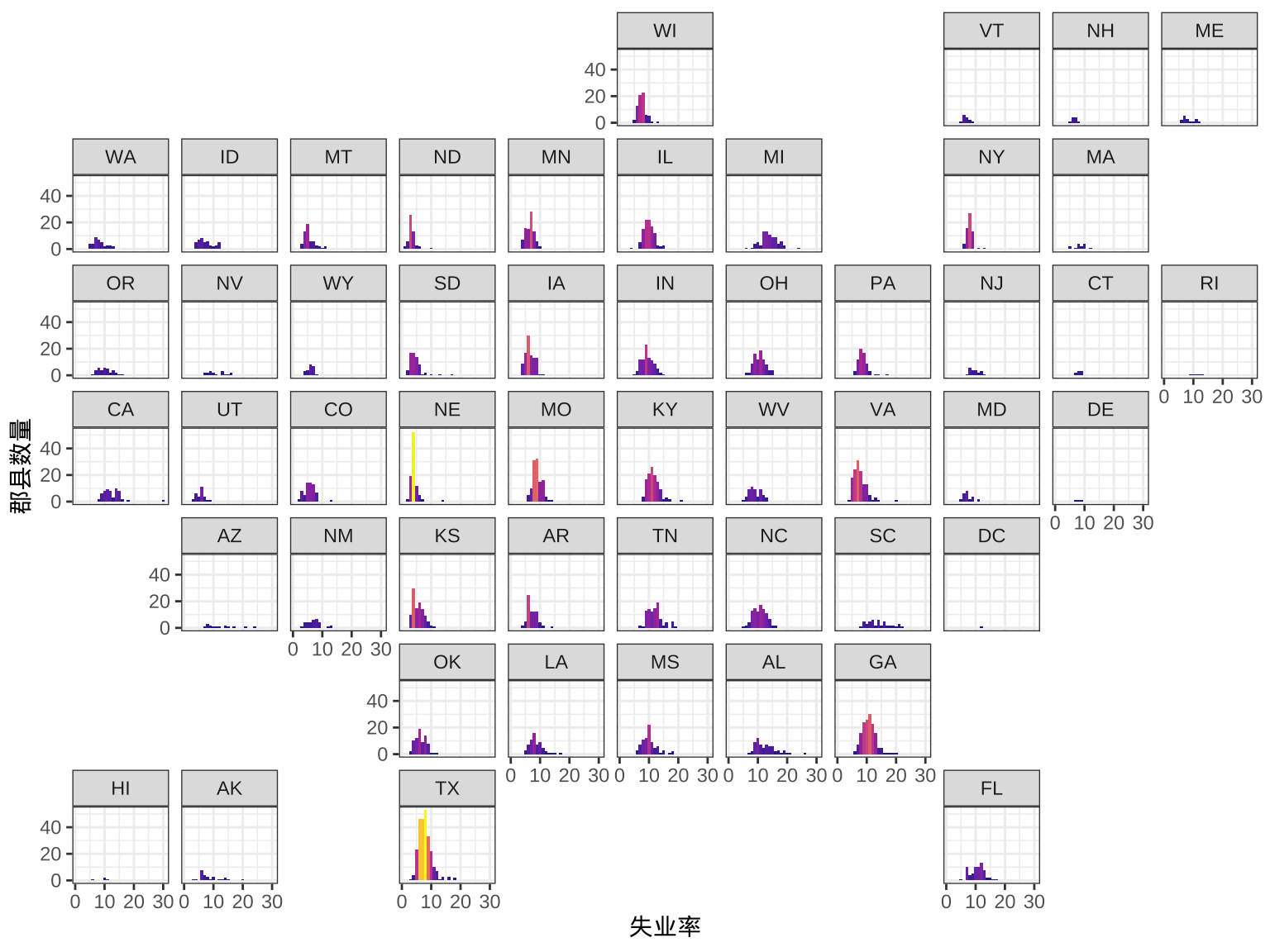
图 3.3: 2009 年美国各州失业率分布
以直方图表示连续数据的分布,这相当于聚合了美国各郡的失业率数据,失业率还可以是更细粒度的数据。
library(maps)
# 准备地图数据
us_state_map <- readRDS(file = "data/us-state-map-2010.rds")
# 2010 年的地图数据
us_county_map <- readRDS(file = "data/us-county-map-2010.rds")
# GEOID 是地理区域唯一标识
us_county_map$GEOID <- as.integer(paste0(us_county_map$STATEFP, us_county_map$COUNTYFP))
# 将失业率数据和地图数据合并
us_county_data <- merge(
x = us_county_map, y = unemp,
by.x = "GEOID", by.y = "fips", all.x = TRUE
)准备好数据后,就可以绘制美国各郡县失业率的分布,如图所示。
ggplot() +
geom_sf(
data = us_county_data, aes(fill = unemp),
colour = "grey80", linewidth = 0.05
) +
geom_sf(
data = us_state_map,
colour = "grey80", fill = NA, linewidth = 0.1
) +
scale_fill_viridis_c(
option = "plasma", na.value = "white"
) +
theme_void() +
labs(
fill = "失业率", caption = "数据源:美国人口调查局"
)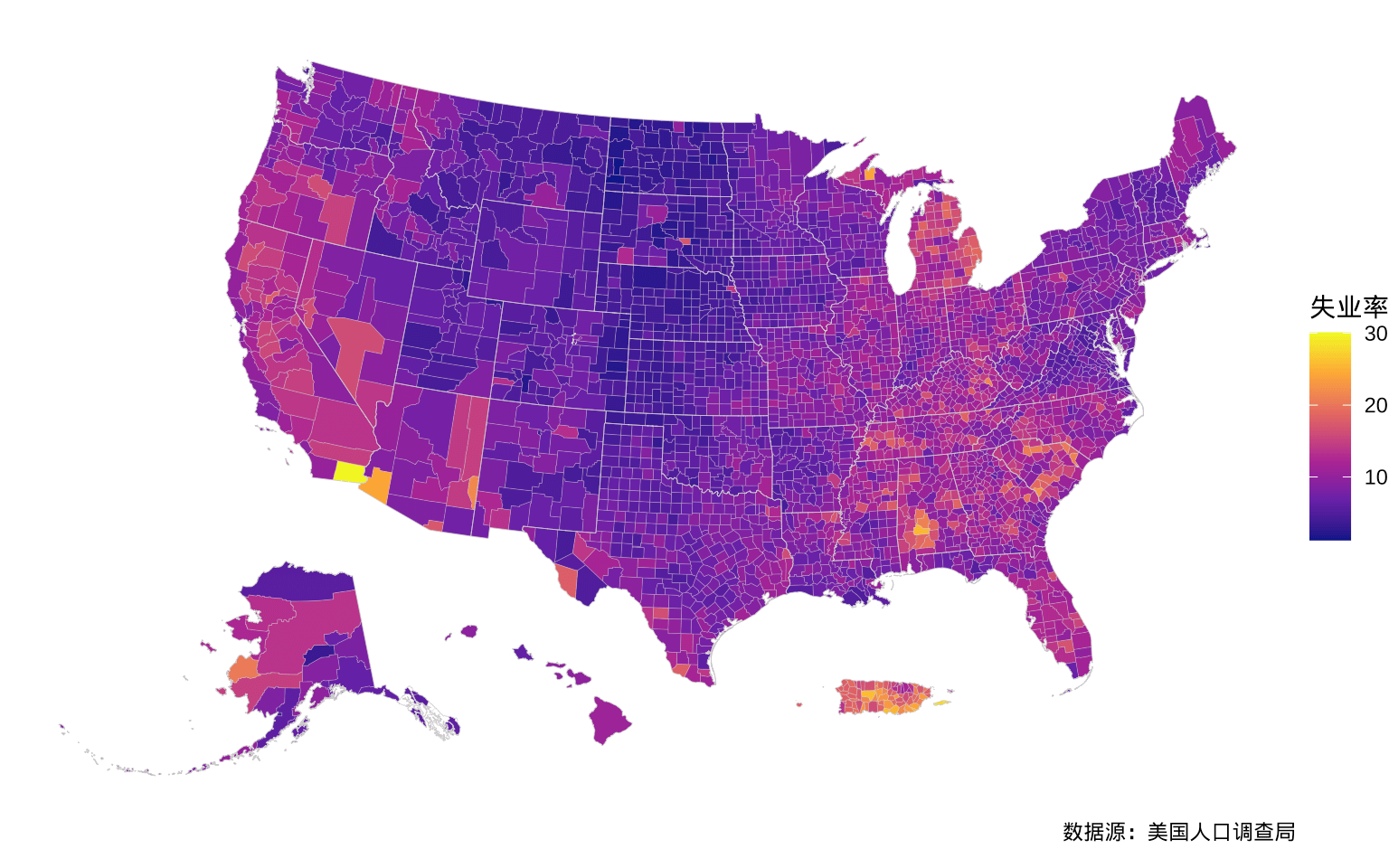
图 3.4: 2009 年美国各郡县失业率分布
通过 tigris 包可以下载历年美国人口调查局发布的数据,但是 2009 年及以前的地图数据缺失,因此,笔者下载了 2010 年的地图数据,它与失业率数据最近。
# 下载美国各郡县的多边形边界地图数据
us_county_map <- tigris::counties(cb = TRUE, year = 2010, resolution = "20m", class = "sf")
# 移动离岸的州和领地
## 郡县地图
us_county_map <- tigris::shift_geometry(us_county_map, geoid_column = "STATE", position = "below")
# 州地图
us_state_map <- tigris::states(cb = TRUE, year = 2010, resolution = "20m", class = "sf")
us_state_map <- tigris::shift_geometry(us_state_map, geoid_column = "STATE", position = "below")经过数据检查,发现失业率数据仅有三个郡县未关联上地图数据。在真实的数据探查中,往往因为业务过程复杂,数据链路长,人员更迭等一系列原因,导致数据存在一定的缺失。只要能够确定缺失的原因,缺失比例,不影响最终结论的可靠性,那么数据就是可用的。
4 热力分布图
本节基于大家熟悉的 quakes 数据集,地震的位置是随机的,难以预测的,quakes 属于空间点过程数据,描述斐济及其周边地震活动规律。将震级分割成六个区间,并以明暗不同的颜色表示震级大小,接着,根据斐济及周边地区的位置,选择相应的坐标参考系,最后,用 ggplot2 深度定制出图 4.1,更加清晰、准确地反映了数据情况,目标区域位于南半球,横跨 180 度经线。
library(sf)
quakes_sf <- st_as_sf(quakes, coords = c("long", "lat"), crs = st_crs(4326))
# st_bbox 获取数据 quakes_sf 的边界
# 地理图层 geom_sf 支持通过 scale_x_continuous 设定刻度标签
# 也可以借助 st_graticule 构造经纬网数据,再添加一个地理图层 geom_sf
ggplot() +
geom_sf(
data = quakes_sf,
aes(size = mag, color = cut(depth, breaks = 150 * 0:5)),
alpha = 0.5
) +
geom_point() +
scale_x_continuous(breaks = c(
# 东经
seq(from = 165, to = 180, by = 5),
# 西经
seq(from = -180, to = -170, by = 5)
)) +
scale_size(range = c(0.25, 4.75)) +
scale_color_viridis_d(option = "C") +
coord_sf(
crs = 3460,
xlim = c(569061, 3008322),
ylim = c(1603260, 4665206)
) +
theme_minimal() +
labs(x = "经度", y = "纬度", color = "震深", size = "震级")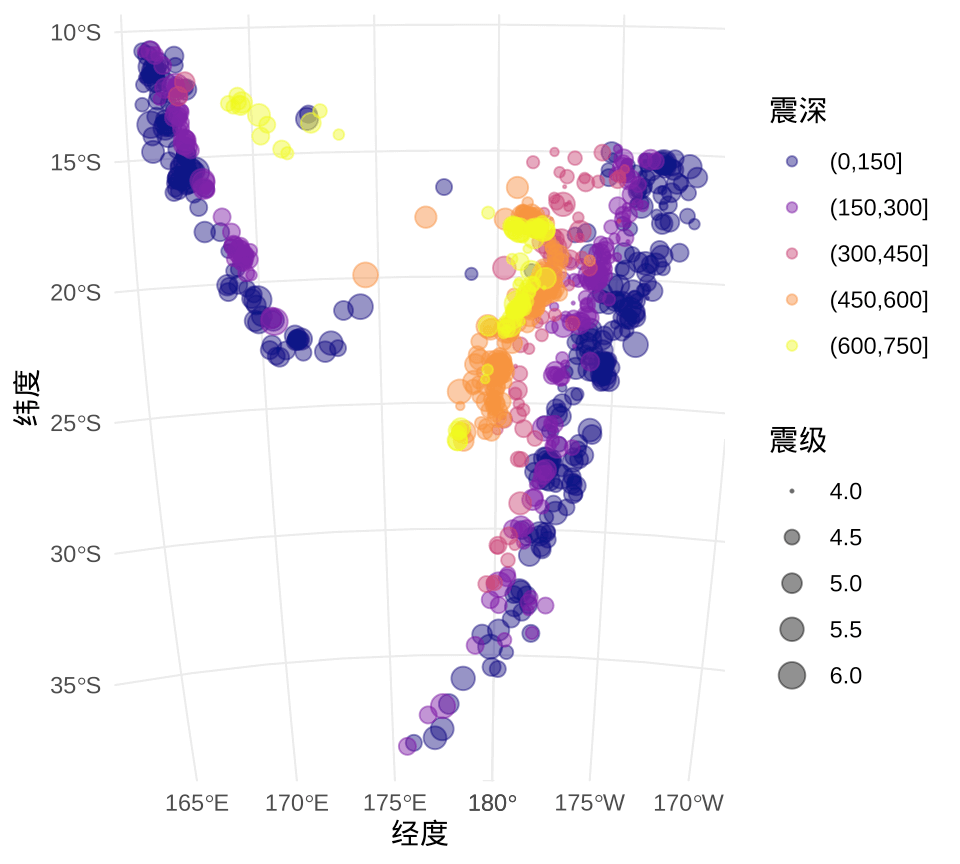
图 4.1: 太平洋岛国斐济及其周边的地震分布
有的地理区域处于板块交界处,地震频发,以至于 4.1 部分区域的散点覆盖严重,影响重点区域的观测。因此,将斐济及周边区域划分成 \(40 \times 80\) 的网格,统计每个小格子内散点的数量,即地震次数,再将地震次数映射给颜色。相比于 4.1,4.2 可以更加清晰地展示地震活跃度的空间分布。
# 目标区域划分成 40x80 的网格
quakes_grid_sf <- st_make_grid(quakes_sf, n = c(40, 80))
# 统计每个区域内包含的点的数量,也就是地震次数
quakes_grid_cnt <- st_sf(
count = lengths(st_intersects(quakes_grid_sf, quakes_sf)),
geometry = st_cast(quakes_grid_sf, "MULTIPOLYGON")
)
# 将多边形绘制出来,以地震次数填充颜色
ggplot() +
geom_sf(
data = quakes_grid_cnt[quakes_grid_cnt$count > 0, ],
aes(fill = count), linewidth = 0.01
) +
scale_fill_viridis_c(option = "C") +
scale_x_continuous(breaks = c(
# 东经
seq(from = 165, to = 180, by = 5),
# 西经
seq(from = -180, to = -170, by = 5)
)) +
coord_sf(
crs = 3460,
xlim = c(569061, 3008322),
ylim = c(1603260, 4665206)
) +
theme_minimal() +
labs(x = "经度", y = "纬度", fill = "频次")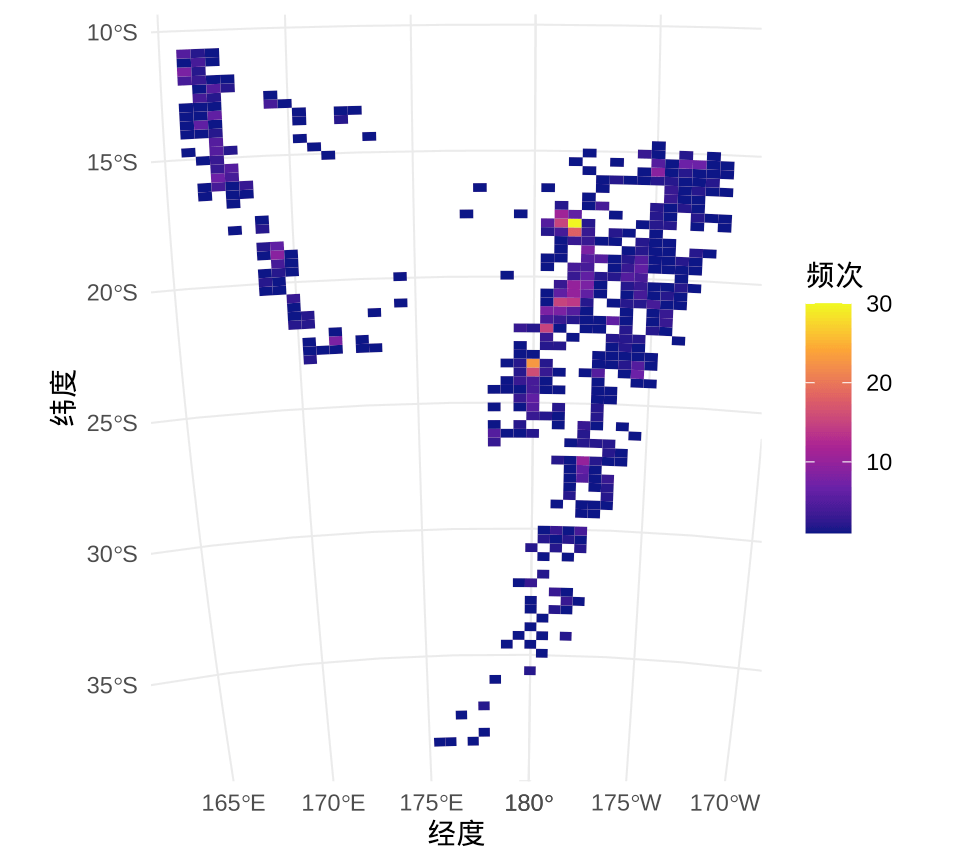
图 4.2: 斐济及其周边的地震活动
4.2 通过将连续空间离散化,再统计各个小网格中地震次数,而 4.3 将地震活动看作是一种随机事件,用非参数的方法 — 二维核密度估计方法计算各个位置发生地震活动的可能性。
## 基于 sf 对象构造
quakes_sf <- st_transform(quakes_sf, crs = 3460)
# 组合 POINT 构造 POLYGON
quakes_sfp <- st_cast(st_combine(st_geometry(quakes_sf)), "POLYGON")
# 构造 POLYGON 的凸包
quakes_sfp_hull <- st_convex_hull(st_geometry(quakes_sfp))
# 添加 buffer
quakes_sfp_buffer <- st_buffer(quakes_sfp_hull, dist = 100000)
# planar point pattern 表示 ppp
# sf 转化为 ppp 类型
quakes_ppp <- spatstat.geom::as.ppp(X = st_geometry(quakes_sf))
# 限制散点在给定的窗口边界内平滑
spatstat.geom::Window(quakes_ppp) <- spatstat.geom::as.owin(quakes_sfp_buffer)
# 高斯核密度估计 36*36 的网格
# dimyx 指定先 y 后 x
density_spatstat <- spatstat.explore::density.ppp(quakes_ppp,
dimyx = c(36, 36),
kernel = "gaussian")
# 转化为 stars 对象 栅格数据
density_stars <- stars::st_as_stars(density_spatstat)
# 设置坐标参考系
density_sf <- st_set_crs(st_as_sf(density_stars), 3460)
ggplot() +
geom_sf(data = density_sf, aes(fill = v), col = NA) +
geom_sf(data = st_boundary(quakes_sfp_hull), linewidth = 0.25) +
geom_sf(data = st_boundary(quakes_sfp_buffer), linewidth = 0.5) +
scale_fill_viridis_c(
option = "C", trans = "log10",
labels = scales::label_log(),
limits = c(1e-12, 1e-9)
) +
scale_x_continuous(breaks = c(
# 东经
seq(from = 165, to = 180, by = 5),
# 西经
seq(from = -180, to = -170, by = 5)
)) +
labs(x = "经度", y = "纬度", fill = "密度") +
theme_minimal()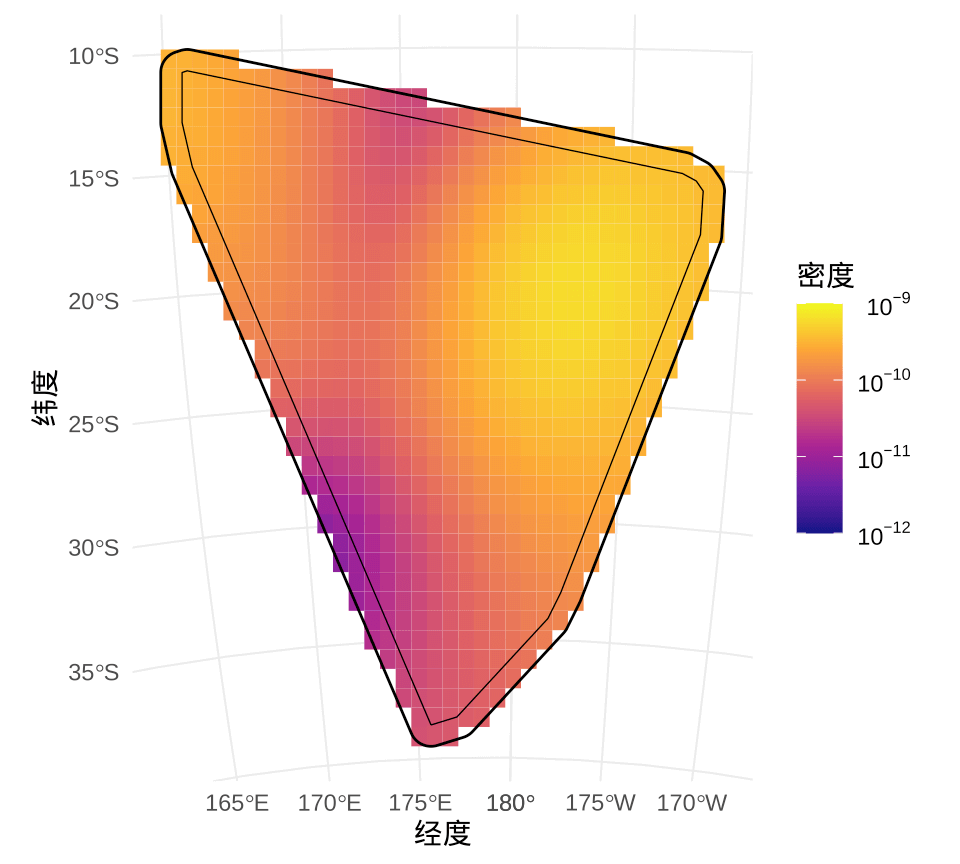
图 4.3: 斐济及其周边的地震活动
核密度估计方法在可视化中应用是相当广泛的,下面简单介绍 ggplot2 的核密度估计原理,做到知其然且知其所以然。上图是采用 spatstat.explore::density.ppp() 实现高斯核密度估计, SpatialKDE 包也可以。然后,在不规则的区域上插值,调用 interp::interp() 或 akima::bilinear() 在规则网格上插值,再调用 ggplot2 包函数 geom_contour() 和 geom_contour_filled() 实现可视化。
5 地形轮廓图
地形轮廓图用于描述地形地势,则无论山洼、山谷,还是高山、高原,抑或是断崖、峡谷、平原,都一目了然。如 5.1 所示,奥克兰 Maunga Whau 火山地形图,图中火山划分为 87 行 61 列的小格子,小格子的长宽都是 10 米,记录格子所处位置的高度,收集整理后形成 volcano 数据集,此所谓的栅格数据。Base R 内置的 volcano 数据集是一个 matrix 类型数据对象。Base R 提供函数 filled.contour() 绘制二维栅格图形,如图所示。
filled.contour(volcano,
x = seq(1, nrow(volcano), length.out = nrow(volcano)),
y = seq(1, ncol(volcano), length.out = ncol(volcano)),
color.palette = hcl.colors,
plot.title = title(
main = "奥克兰火山堆地形图",
xlab = "南北方向", ylab = "东西方向",
family = "Noto Serif CJK SC"
),
plot.axes = {
axis(side = 1, at = 10 * 1:8)
axis(side = 2, at = 10 * 1:6)
},
key.title = title(main = "高度", family = "Noto Serif CJK SC"),
key.axes = axis(side = 4, at = 90 + 20 * 0:5)
)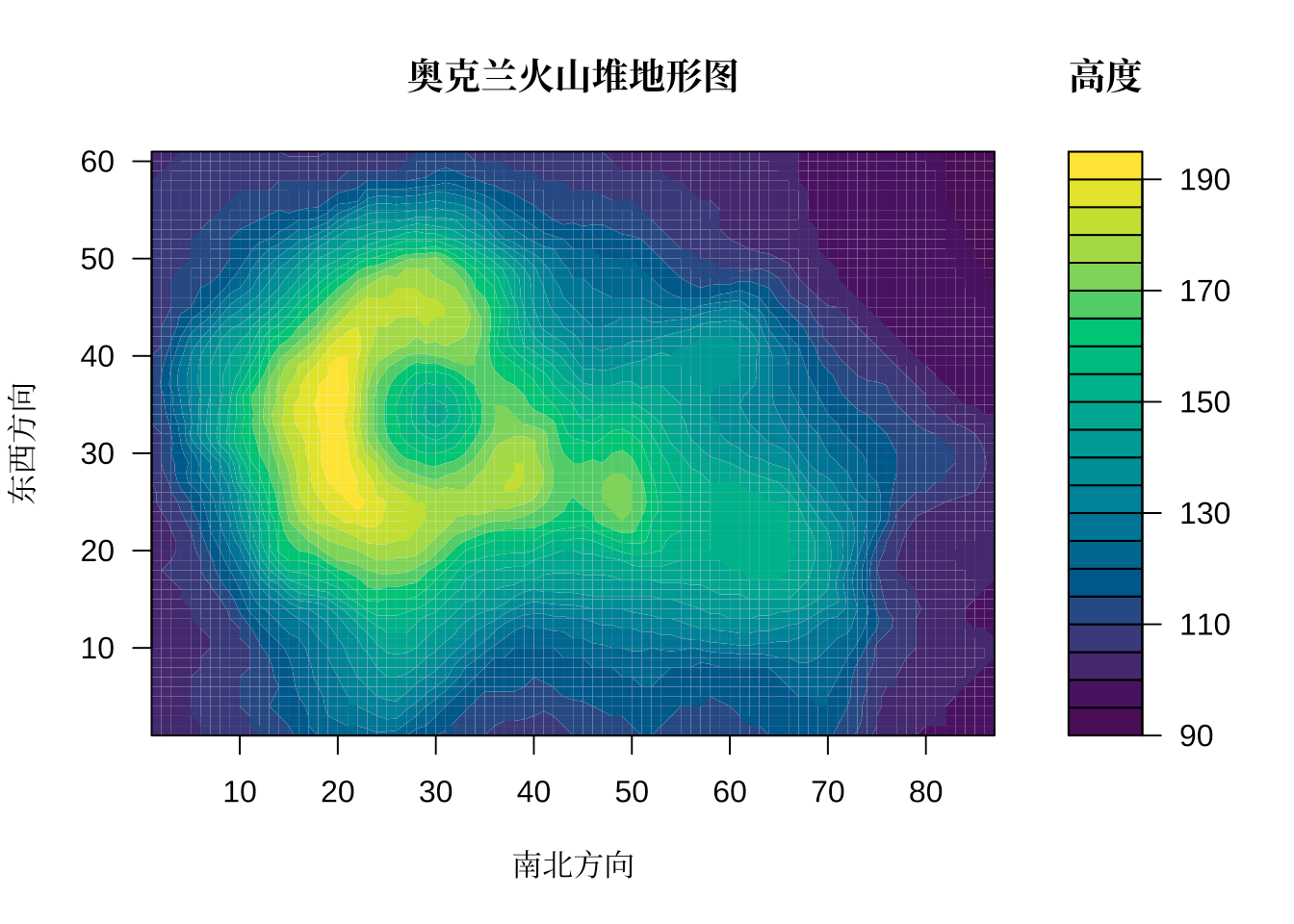
图 5.1: 奥克兰火山地形图
lattice 包提供函数 levelplot() 绘制类似的栅格图形。
library(lattice)
levelplot(volcano,
col.regions = hcl.colors,
at = 80 + 10 * 0:12,
scales = list(
draw = TRUE,
# 去掉图形上边、右边多余的刻度线
x = list(alternating = 1, tck = c(1, 0)),
y = list(alternating = 1, tck = c(1, 0))
),
# 减少三维图形的边空
lattice.options = list(
layout.widths = list(
left.padding = list(x = 0, units = "inches"),
right.padding = list(x = 0, units = "inches")
),
layout.heights = list(
bottom.padding = list(x = 0, units = "inches"),
top.padding = list(x = 0, units = "inches")
)
),
xlab = "南北方向", ylab = "东西方向"
)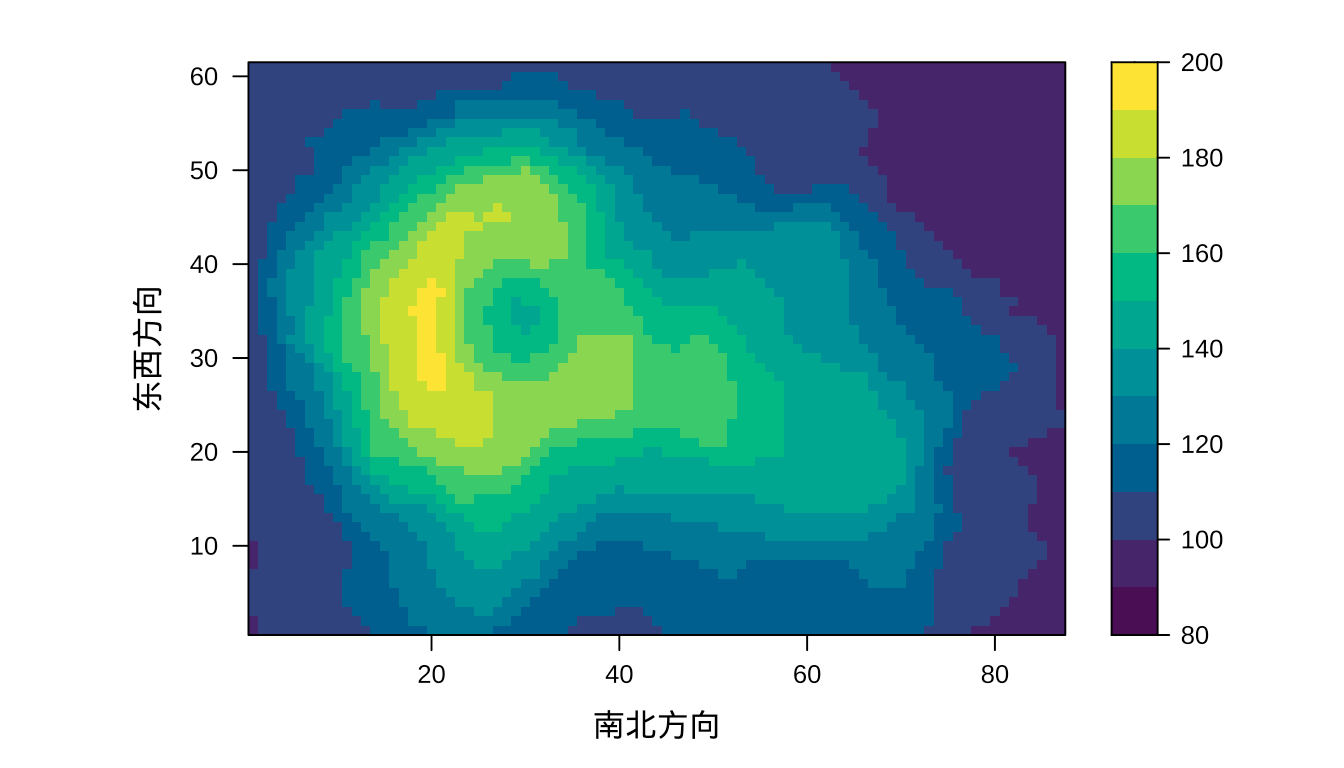
图 5.2: 奥克兰火山地形图
ggplot2 包提供瓦片图层函数 geom_tile() 来可视化栅格数据,而函数 geom_contour() 可以根据海拔绘制等高线。
volcano_df <- expand.grid(x = 1:nrow(volcano), y = 1:ncol(volcano))
volcano_df$z <- as.vector(volcano)
ggplot(volcano_df) +
geom_tile(aes(x = x, y = y, fill = z)) +
geom_contour(aes(x = x, y = y, z = z), color = "gray20") +
scale_fill_viridis_c() +
coord_fixed(expand = FALSE) +
theme_classic() +
labs(x = "南北方向", y = "东西方向", fill = "高度")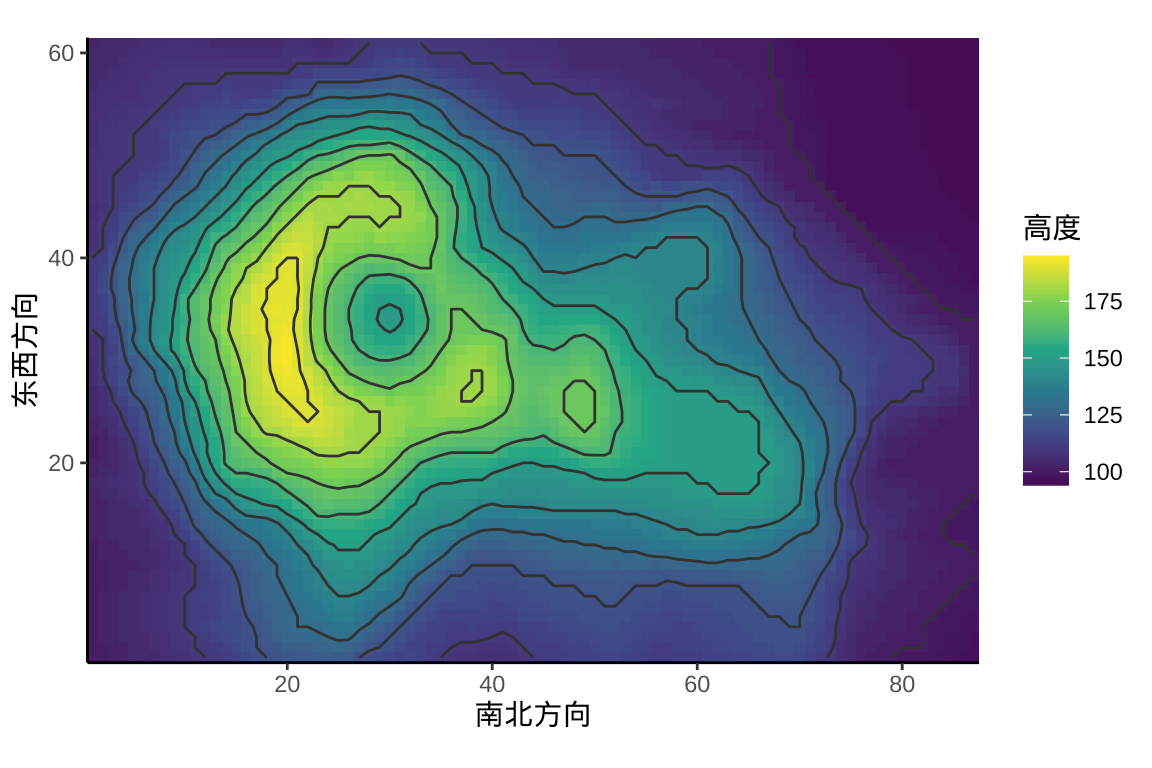
图 5.3: 奥克兰火山地形图
6 三维地形图
而 rayshader 包提供函数 plot_gg() 可以将 ggplot2 绘图对象转化为 3D 对象。对于栅格化的地形数据,函数 sphere_shade() 可以提供很好的阴影特效,更多案例见 https://www.rayshader.com/。
library(rayshader)
volcano |>
sphere_shade(texture = "imhof1") |>
plot_map()
图 6.1: 奥克兰火山地形图
三维透视图亦可展示地形图,用 lattice 包绘制火山地形图。
wireframe(volcano,
drape = TRUE, colorkey = FALSE, shade = TRUE,
xlab = list("南北方向", rot = 20),
ylab = list("东西方向", rot = -50),
zlab = list("高度", rot = 90),
# 减少三维图形的边空
lattice.options = list(
layout.widths = list(
left.padding = list(x = -.6, units = "inches"),
right.padding = list(x = -1.0, units = "inches")
),
layout.heights = list(
bottom.padding = list(x = -.8, units = "inches"),
top.padding = list(x = -1.0, units = "inches")
)
),
# 设置坐标轴字体大小
par.settings = list(
axis.line = list(col = "transparent"),
fontsize = list(text = 12, points = 10)
),
# z 轴标签旋转 90 度
scales = list(
arrows = FALSE, col = "black",
z = list(rot = 90)
),
screen = list(z = 30, x = -65, y = 0)
)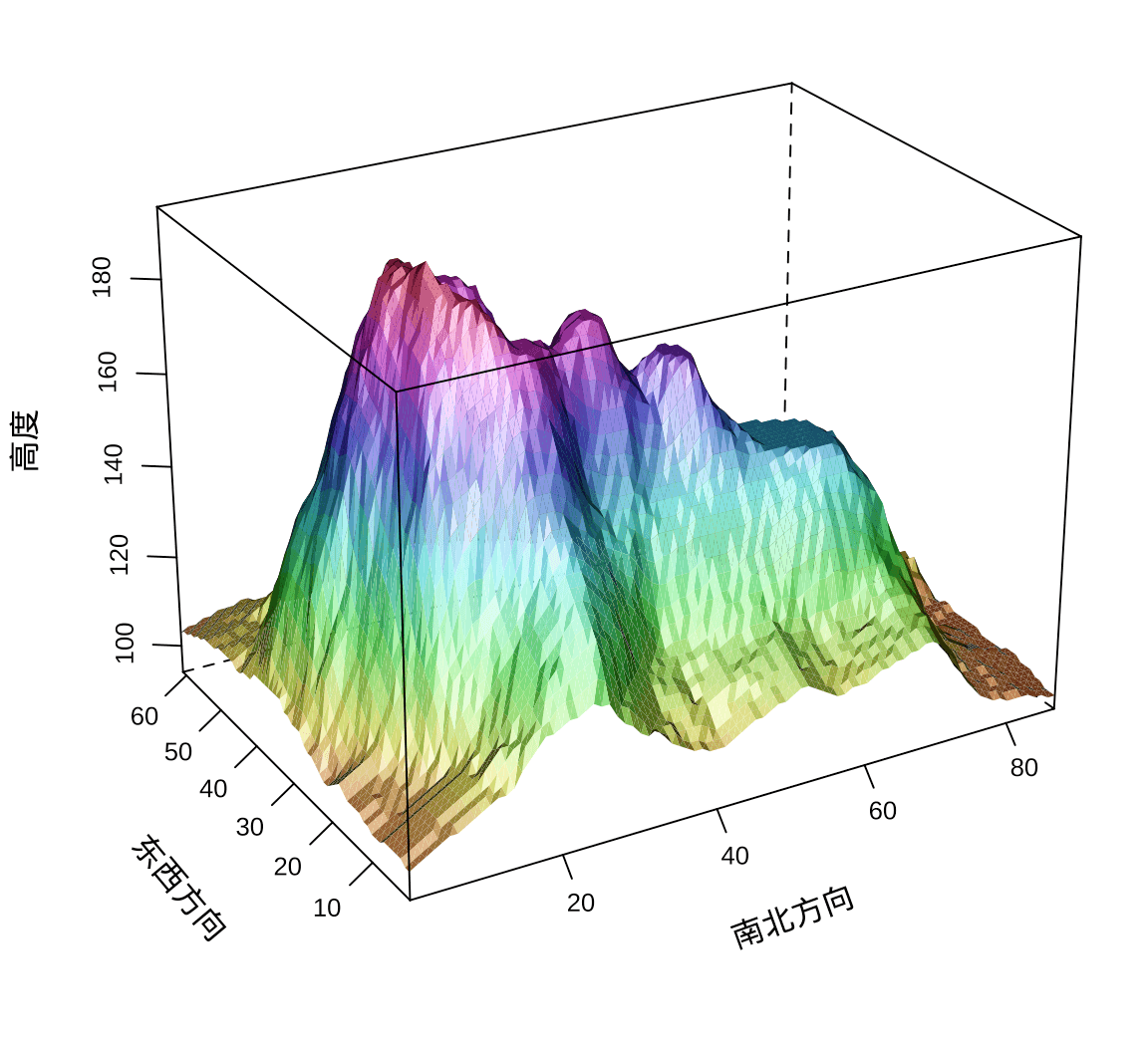
图 6.2: lattice 包绘制地形图
静态的三维图形限制用户只能从一个视角观察,因视角和透视的关系,存在遮挡和视觉错位的情况,比如火山地形因坡面遮挡了火山口及其周围地势。调整观察角度,经过探索设置 screen = list(z = -45, x = -50, y = 0),重新绘图,见下图,火山口及其周围地势一目了然。
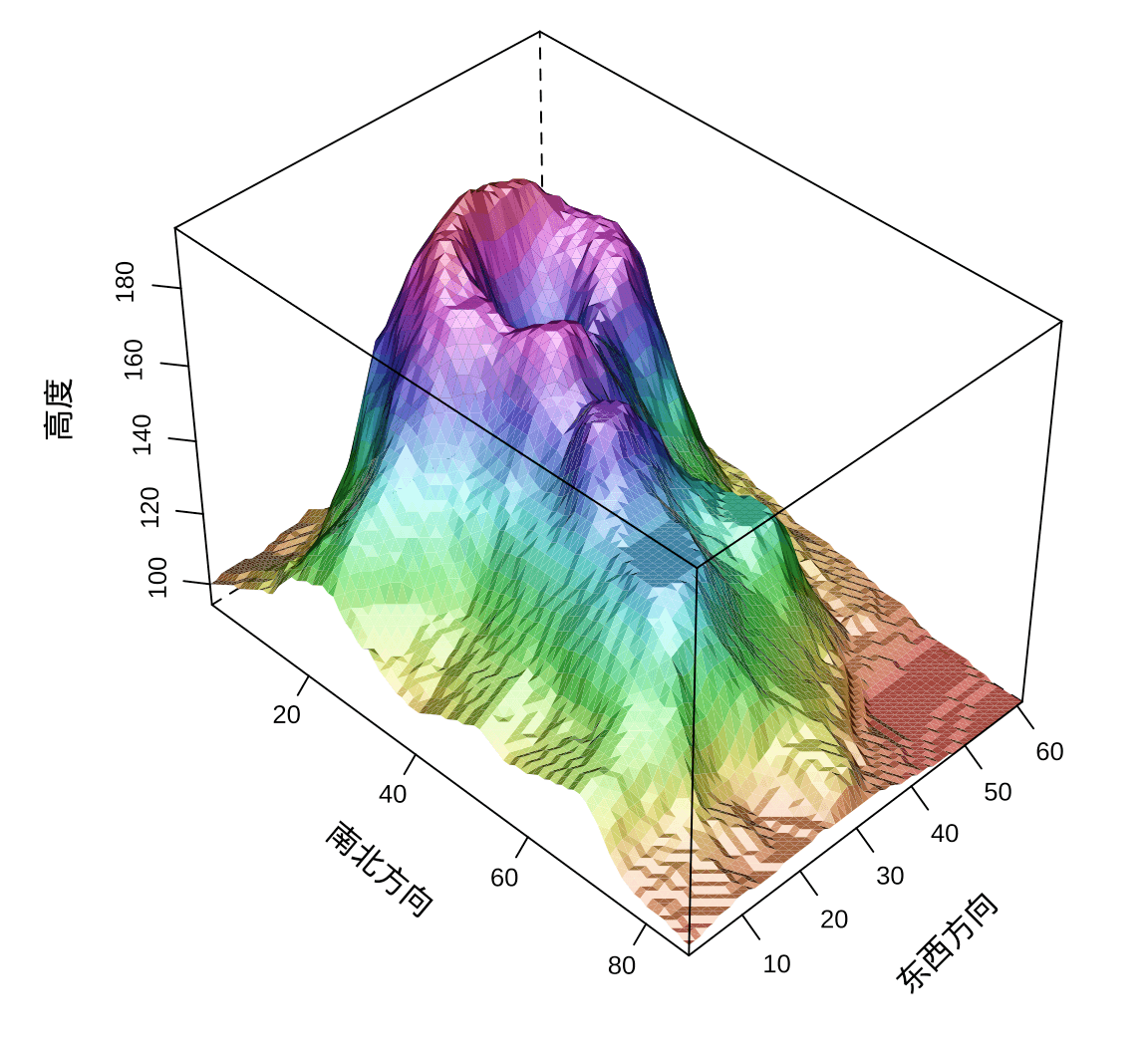
图 6.3: lattice 包绘制地形图
而 plotly 包可以绘制交互的三维透视图来展示地形,通过拖拽图形,可以从任意视角切入观察火山口及山体的任意位置,还可以拉近看局部细节。
plotly::plot_ly(z = ~volcano) |>
plotly::add_surface(colorbar = list(title = "高度")) |>
plotly::layout(scene = list(
xaxis = list(title = "南北方向"),
yaxis = list(title = "东西方向"),
zaxis = list(title = "高度")
))图 6.4: plotly 绘制地形图
类似地,rgl 包绘制的三维散点图亦可展示数据的空间分布。
library(rgl)
#> This build of rgl does not include OpenGL functions. Use
#> rglwidget() to display results, e.g. via options(rgl.printRglwidget = TRUE).
view3d(
theta = 0, phi = -45, fov = 30,
zoom = 1, interactive = TRUE
)
# 将连续型数据向量转化为颜色向量
colorize_numeric <- function(x) {
scales::col_numeric(palette = "viridis", domain = range(x))(x)
}
# 在数据集 quakes 上添加新的数据 color
volcano_df <- within(volcano_df, {
color <- colorize_numeric(z)
})
# 绘制图形
with(volcano_df, {
plot3d(x = x, y = y, z = z, col = color,
xlab = "南北方向", ylab = "东西方向",
zlab = "高度")
})图 6.5: rgl 绘制地形图
Base R 提供函数 persp() 绘制三维透视图。
z <- 2 * volcano
x <- 10 * (1:nrow(z)) # 10 米间距 (S to N)
y <- 10 * (1:ncol(z)) # 10 米间距 (E to W)
nrz <- nrow(z)
ncz <- ncol(z)
nbcol <- 100
color <- hcl.colors(nbcol)
zfacet <- z[-1, -1] + z[-1, -ncz] + z[-nrz, -1] + z[-nrz, -ncz]
# 颜色编码
facetcol <- cut(zfacet, nbcol)
persp(x, y, z,
theta = 135, phi = 30, col = color[facetcol],
expand = .5, shade = 0.25, border = NA, box = FALSE
)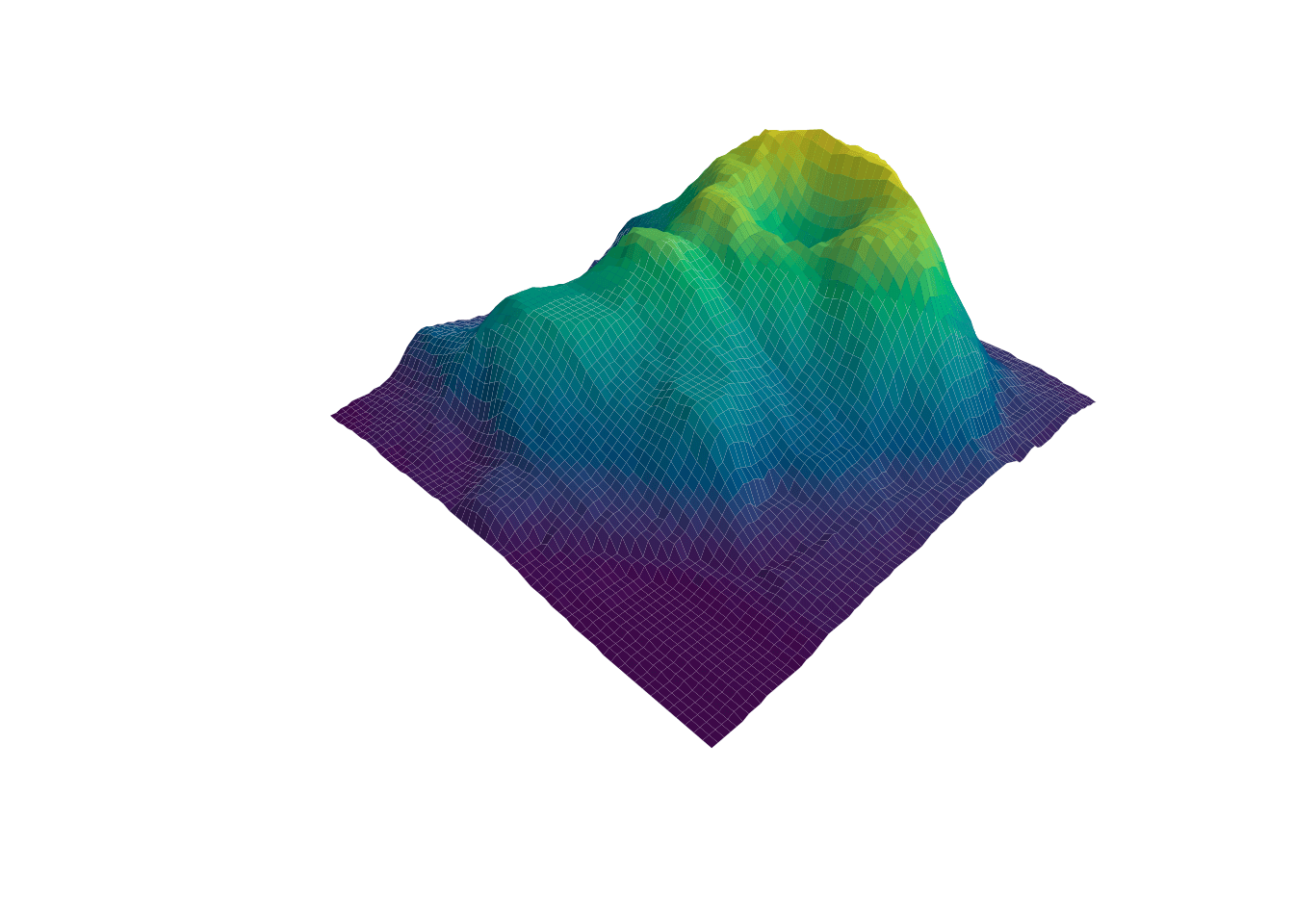
图 6.6: persp 函数绘制地形图
rgl 包提供函数 persp3d() 绘制交互式的真三维透视图形。
# 三维透视图
zlim <- range(z)
zlen <- zlim[2] - zlim[1] + 1
colorlut <- hcl.colors(zlen) # height color lookup table
col <- colorlut[ z - zlim[1] + 1 ] # assign colors to heights for each point
persp3d(x = x, y = y, z = z, col = col,
xlab = "南北方向", ylab = "东西方向", zlab = "高度")图 6.7: persp3d 函数绘制地形图
另一个函数 surface3d() 也可以绘制三维曲面图。
surface3d(x, y, z, color = col, back = "lines")图 6.8: surface3d 函数绘制地形图