就展示数据而言,本博已介绍数以十计的图形,如此丰富,就单一目的而言,也有多种可选的图形。可见,仅仅掌握 ggplot2 这套工具是远远不够的,还需要了解数据背景,探索、分析数据,获得数据洞见,只有结合这些,才知道选择最合适的图形,进而准确地传递信息,数据才能释放出应有的价值。
1 防止误差线图
举例来说,如图 1.1 所示,图中从左往右依次是误差线图、箱线图,它们基于同一份数据,采用不同的图形展示数据的分布情况。在一些期刊杂志上, 1.1 非常受欢迎,而实际上它所表达的信息非常有限,严重的情况下,甚至会产生误导。
数据来自中国国家统计局 2021 年发布的统计年鉴,是分城市、镇和乡村的各省、自治区、直辖市的男女比例数据。 一般来说,各地区的性别比例不可能出现严重失调,比如男的是女的一倍,一个省要是出现如此失调的现象是非常罕见的。而图 1.1 的纵轴给人感觉还有性别比为 50% 甚至 30% 的情况,纯属误导。相比而言,箱线图 1.1 就好很多,既把整体情况展示出来了,又将一些性别比例离群的突出出来了,就整个图形来说,城市、镇和乡村的比较也突出出来了,占据了图的主要位置。
library(data.table)
province_sex_ratio <- readRDS(file = "data/china-sex-ratio-2020.rds")
province_sex_ratio <- as.data.table(province_sex_ratio)
library(ggplot2)
province_sex_ratio[, .(mean_len = mean(`性别比(女=100)`), sd_len = sd(`性别比(女=100)`)), by = "区域"] |>
ggplot(aes(x = `区域`, y = mean_len)) +
geom_col(
position = position_dodge(0.4), width = 0.4, fill = "gray"
) +
geom_errorbar(aes(ymin = mean_len - sd_len, ymax = mean_len + sd_len),
position = position_dodge(0.4), width = 0.2
) +
theme_classic() +
labs(y = "性别比(女=100)")
ggplot(data = province_sex_ratio, aes(x = `区域`, y = `性别比(女=100)`)) +
geom_boxplot() +
theme_classic()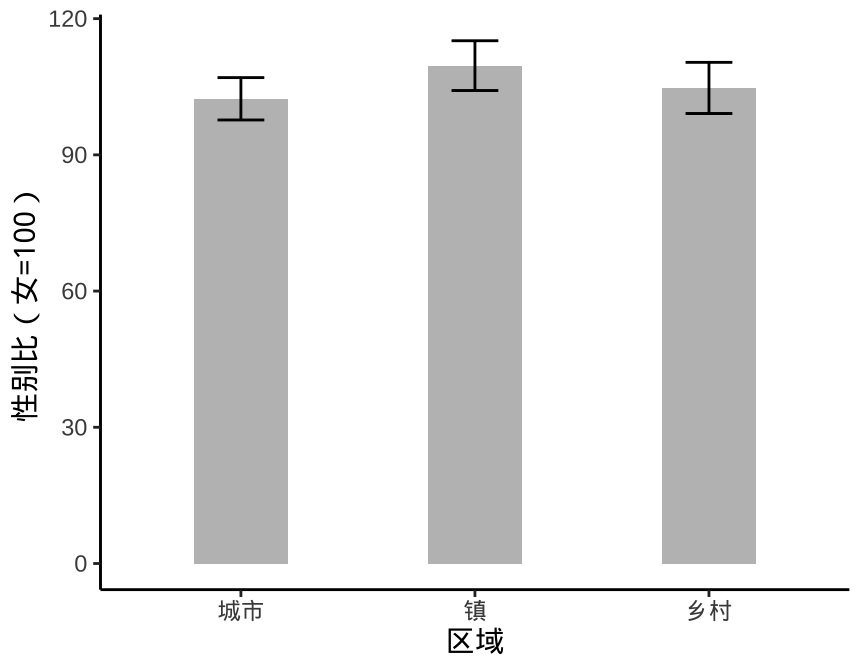
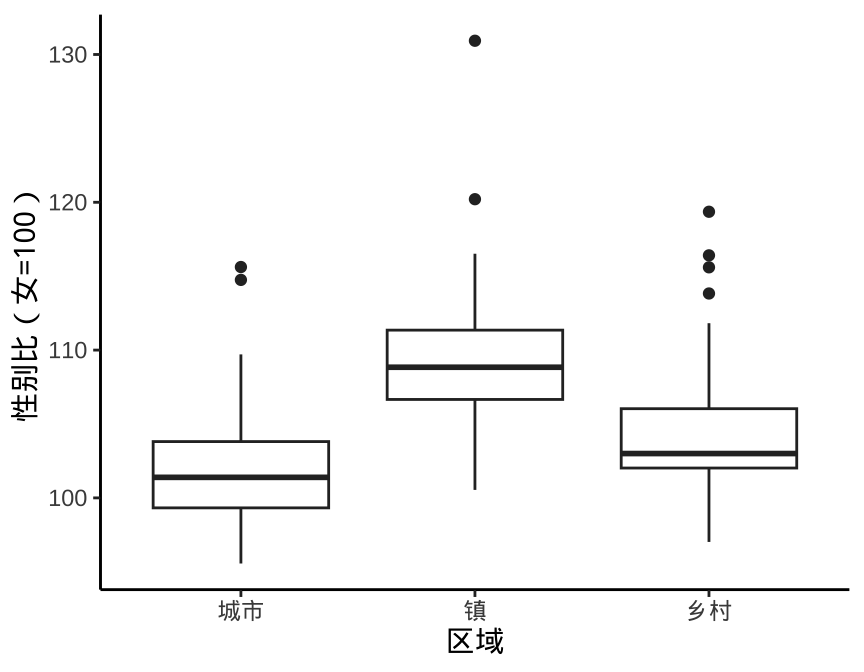
图 1.1: 防止误差线图
2 展示原始数据
在数据量很大的情况下,借助箱线图、提琴图可以非常方便地展示数据分布,而在数据量很小的情况下,借助散点图可以快速看出原始的数据信息。如果散点存在聚集,还可以添加水平的随机抖动,如图 2.1 所示。
ggplot(data = province_sex_ratio, aes(x = `区域`, y = `性别比(女=100)`)) +
geom_point() +
theme_classic()
ggplot(data = province_sex_ratio, aes(x = `区域`, y = `性别比(女=100)`)) +
geom_jitter(width = 0.25) +
theme_classic()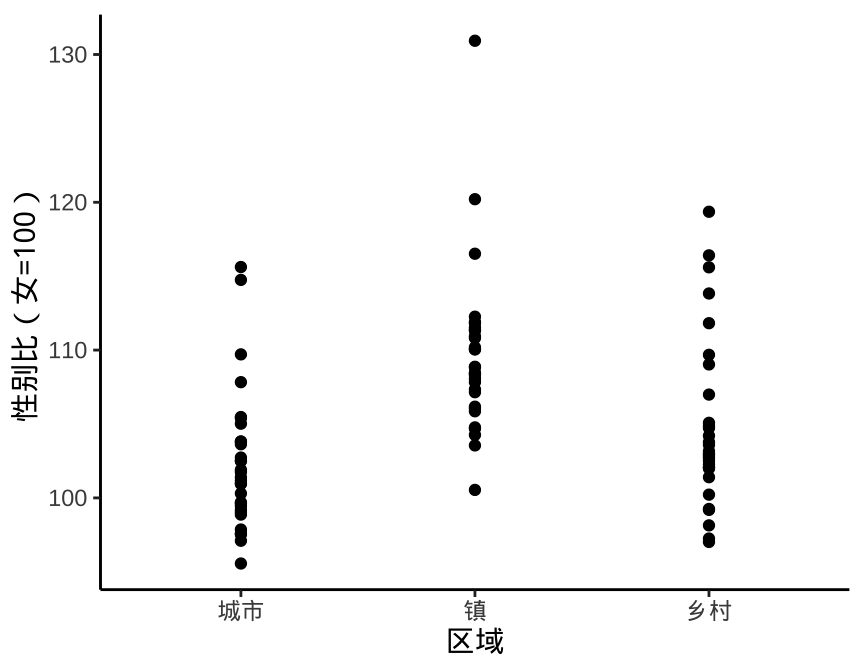
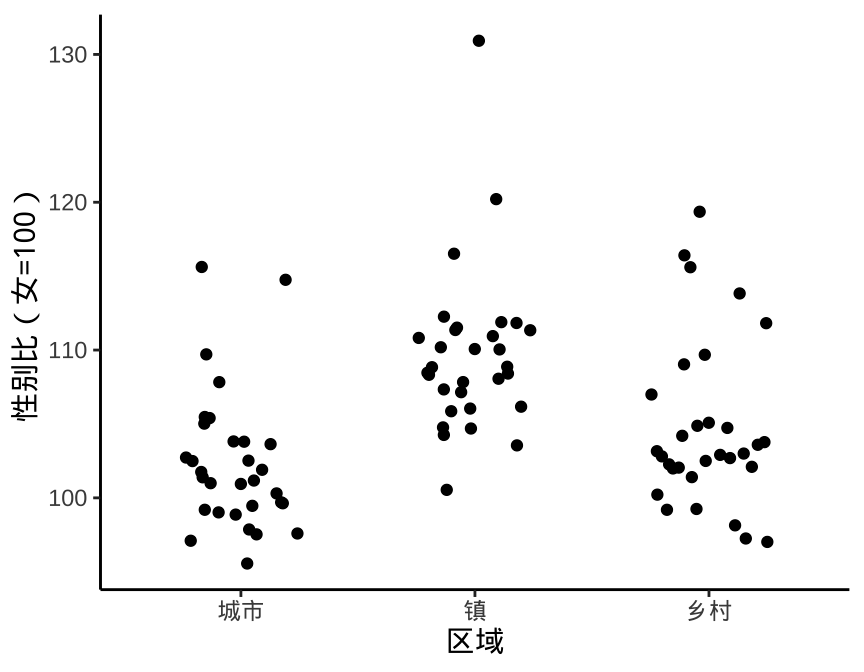
图 2.1: 展示原始数据
3 善用尺度变换
在过去 25 年里,R 语言的维护和开发工作由一个核心团队负责,期间团队陆续加入新人,有的截止到 2022 年,还一直在持续维护和开发,实为不易。下图将他们筛选出来,并将他们提交的代码量做年度趋势图。
svn_trunk_log <- readRDS(file = "data/svn-trunk-log-2022.rds")
svn_trunk_log$year <- as.integer(format(svn_trunk_log$stamp, "%Y"))
trunk_year_author <- aggregate(data = svn_trunk_log, revision ~ year + author, FUN = length)
library(geomtextpath)
trunk_year_author_sub <- trunk_year_author[trunk_year_author$author %in% trunk_year_author[trunk_year_author$year == 2022, "author"], ]
ggplot(data = trunk_year_author_sub, aes(x = year, y = revision)) +
geom_textline(aes(color = author, label = author), show.legend = F) +
theme_classic() +
labs(x = "年份", y = "代码提交量")
ggplot(data = trunk_year_author_sub, aes(x = year, y = revision)) +
geom_textline(aes(color = author, label = author), show.legend = F) +
scale_y_log10() +
theme_classic() +
labs(x = "年份", y = "代码提交量(取对数)")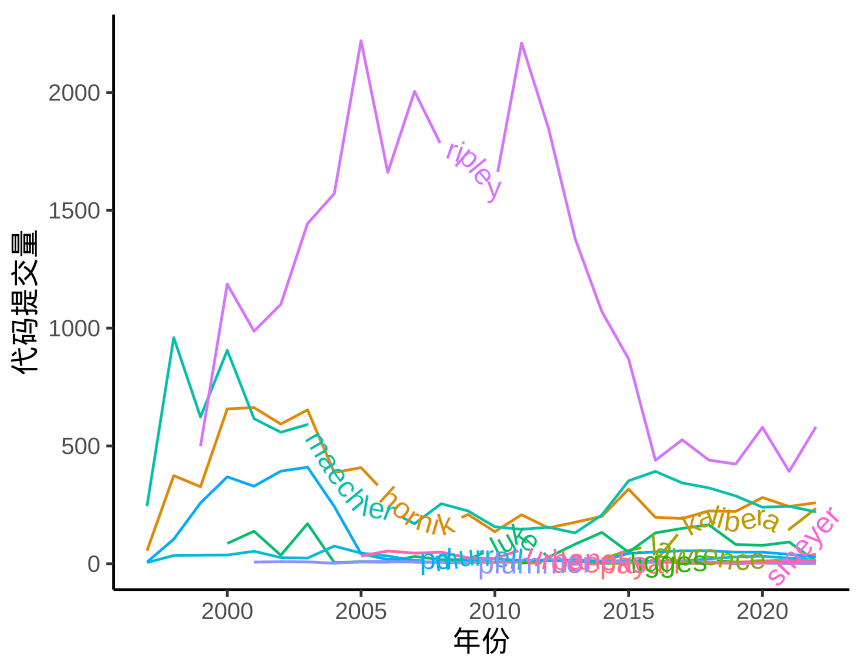
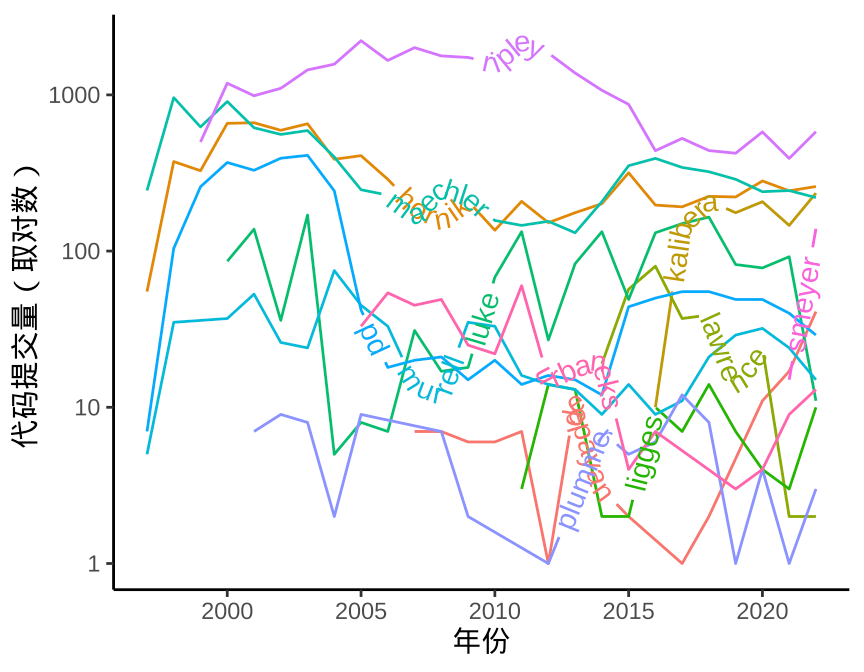
图 3.1: 对数变换的效果
图 3.1 的左子图可以看出,只有 ripley(Brian Ripley)、maechler(Martin Maechler)、hornik(Kurt Hornik) 和 kalibera(Tomas Kalibera) 明显较多,尤其是 Brian Ripley,相对而言,一些开发者的代码提交次数就很少,趋势线挤在一起,无法区分。通过对数变换,可以将相近的曲线分离,放大细节。当然,是否需要采用对数变换取决于图形目的,当想重点突出 Brian Ripley 等四人的贡献时,就不需要对数变换。
考虑到折线相互缠绕带来的不便,而栅格图不仅可以避免折线相互缠绕的现象,还可以更好地刻画时间节点,如开发者何时开始贡献代码,何时不再维护代码,哪些又一直活跃着,通过图 3.2 ,这些情况一目了然。图中代码提交量是根据贡献者按月统计的,图例刻度同样使用了对数变换,以便展现层次感。
svn_trunk_log$date <- as.Date(format(svn_trunk_log$stamp, "%Y-%m-01"))
trunk_year_author <- aggregate(data = svn_trunk_log, revision ~ date + author, FUN = length)
ggplot(data = trunk_year_author, aes(x = date, y = author)) +
geom_tile(aes(fill = revision)) +
scale_fill_viridis_c(trans = "log10") +
coord_cartesian(expand = FALSE) +
theme_classic() +
labs(x = "月份", y = "贡献者", fill = "代码提交量")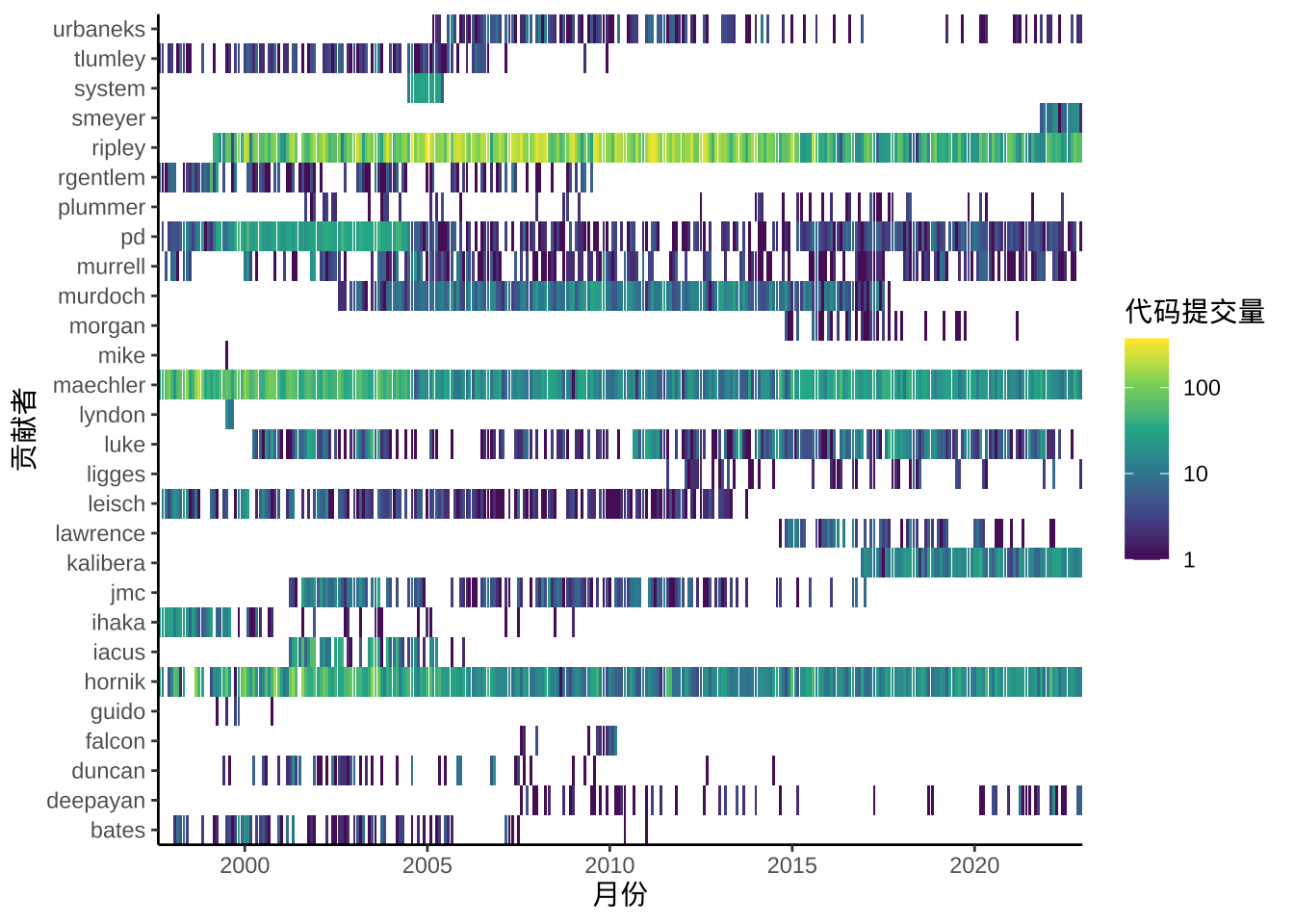
图 3.2: 开发者贡献代码的趋势
4 适当添加注释
在图 2.1 的基础上,我们想了解哪些离群的点都代表哪些地方,这就需要添加注释。下 图4.1 的左子图在散点周围添加了地区名称,由于数据的非均匀分布,重叠文本有很多。而且,图中想要重点突出的是离群的地区,而不是将所有点都注释上。在图中,注释可以看作是一种强调,处处强调也就无所谓强调,强调的要求是有起伏对比。因此,图 4.1 的右子图,只对离群的散点添加了注释,对离群值的定义可根据具体数据情况而定,此处从简。
ggplot(data = province_sex_ratio, aes(x = `区域`, y = `性别比(女=100)`)) +
geom_point() +
geom_text(aes(label = `地区`)) +
theme_classic()
outlier_filter <- function(x) {
x < (quantile(x, probs = 0.25) - 1.5 * IQR(x)) | x > (quantile(x, probs = 0.75) + 1.5 * IQR(x))
}
ggplot(data = province_sex_ratio, aes(x = `区域`, y = `性别比(女=100)`)) +
geom_jitter(width = 0.25) +
geom_text(aes(label = `地区`),
data = function(x) subset(x, subset = outlier_filter(`性别比(女=100)`))
) +
theme_classic()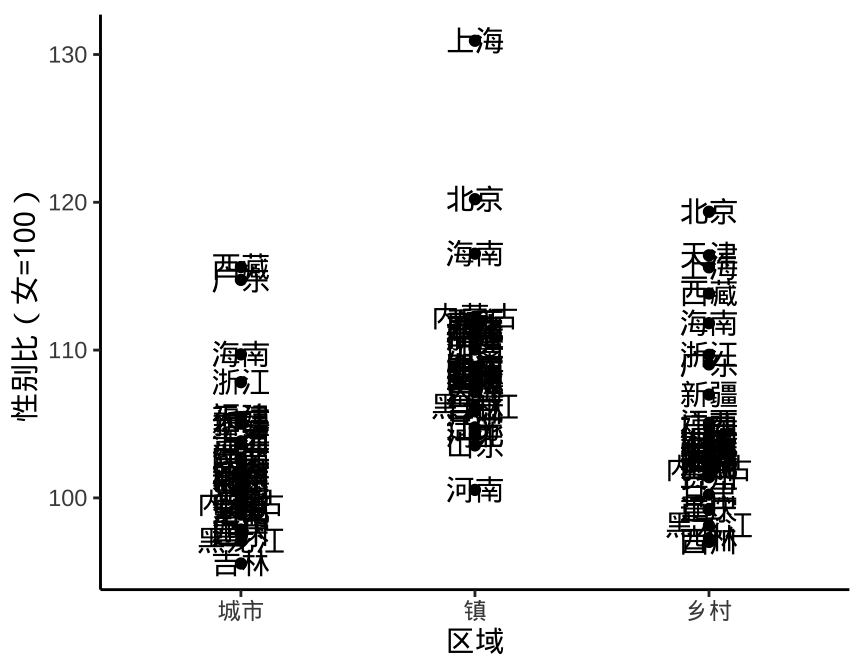
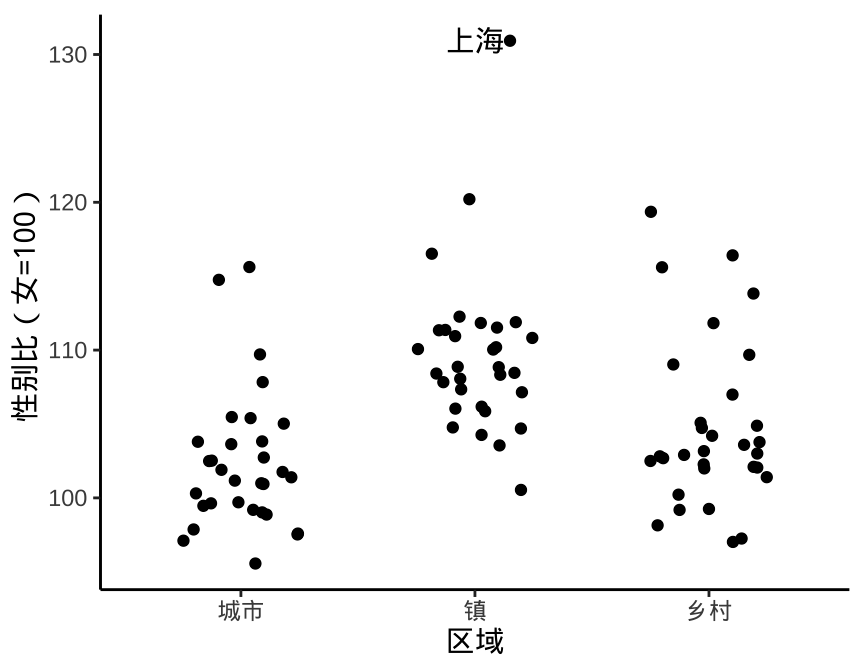
图 4.1: 适当添加注释
5 结合数据背景
结合数据背景绘图具有很大的灵活性,添加简单、清晰的辅助信息的目的是增加可读性,方式上可以通过参考线,刻度单位等体现出来。一般地,女性的寿命比男性的普遍要长一些,高龄女性远多于男性,之前分年龄段展示性别比数据时,也说明了这一点。人口学家认为新生儿正常的人口比约为 104,在人口统计学上,一般正常范围在 102 至 105 之间,亚洲一些国家重男轻女思想根深蒂固,往往远高于此区间。因此,下图 5.1 左子图将参考线设为性别比 100 是不合适的,而应该结合人口统计数据的背景,设置为 104。
p <- ggplot(data = province_sex_ratio, aes(x = `区域`, y = `性别比(女=100)`)) +
geom_jitter(width = 0.25) +
geom_text(aes(label = `地区`),
data = function(x) subset(x, subset = outlier_filter(`性别比(女=100)`))
) +
theme_classic()
# 共用图形对象
set.seed(2022) # 设置随机数种子保持抖动图一致
p + geom_hline(yintercept = 100, linewidth = 0.8, lty = 2, color = "gray")
set.seed(2022)
p + geom_hline(yintercept = 104, linewidth = 0.8, lty = 2, color = "gray")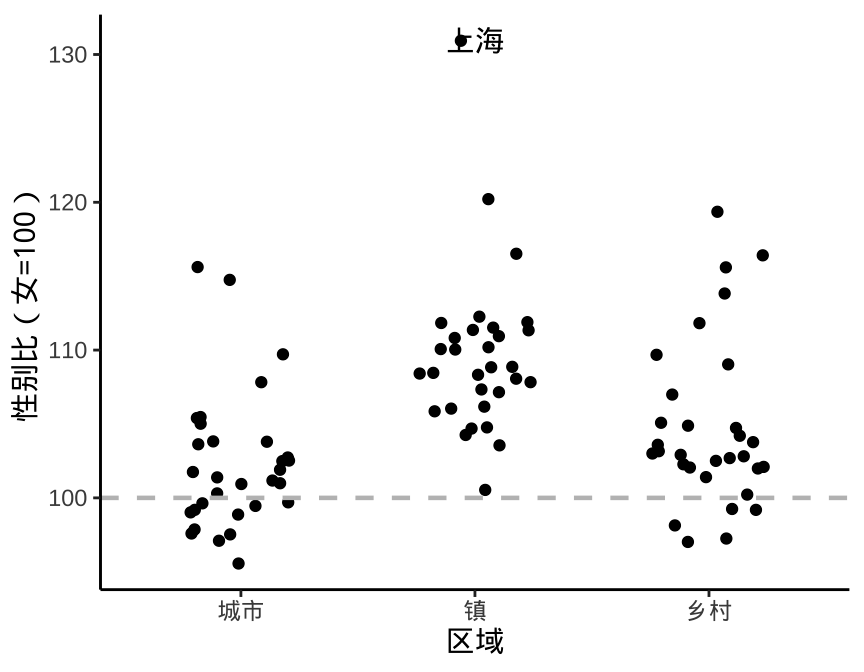
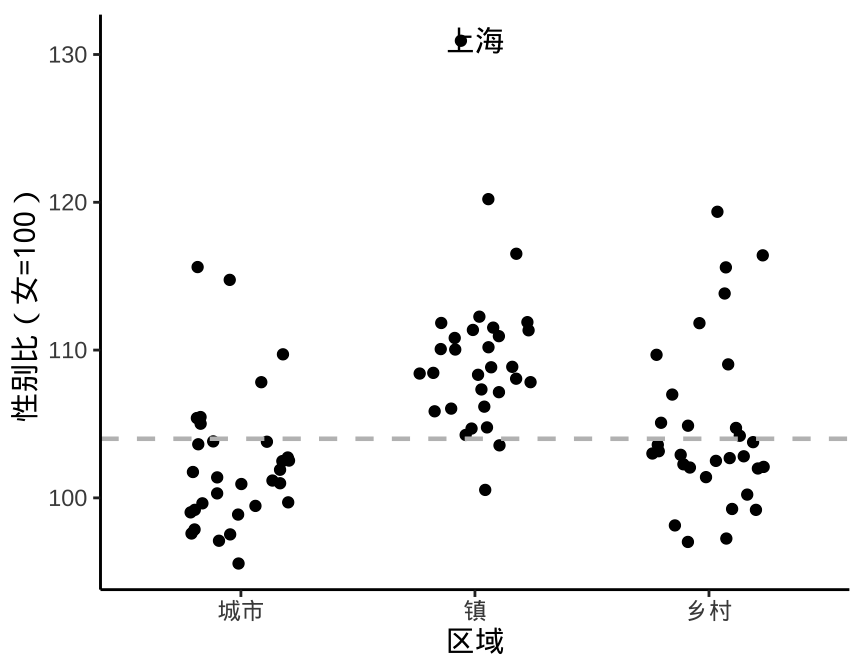
图 5.1: 结合数据背景添加辅助参考信息
由上图也不难看出,城市里女性占比更多,说明女性往城里跑,而小镇青年留下的大多是男性,农村老太太远多于老大爷。城市里,大龄女青年很多,小镇里大龄男青年很多,适龄区间的男女性别比在空间区域上严重失衡,也是造成新生儿出生率低的原因之一。
6 简单胜过复杂
简单准确地传达数据洞见比使用各种特效、技巧有效得多。下图 6.1 左、右两幅子图构成鲜明的对比,为了表示中国城市、镇和农村的性别比差异。右图额外添加了一系列复杂的元素 — 绘图区域设置橘黄色背景,根据区域给不同的柱子配色,添加灰色绘图主题,添加图形的主、副标题和说明。左图化繁为简,直截了当,将读者注意力快速吸引到不同柱子的高度上,没有花里胡哨的东西分散宝贵的注意力。
aggregate(data = province_sex_ratio, `性别比(女=100)` ~ 区域, FUN = mean) |>
ggplot(aes(x = `区域`, y = `性别比(女=100)`)) +
geom_bar(stat = "identity", fill = "gray", width = 0.5) +
geom_hline(yintercept = 104, linewidth = 0.8, lty = 2, color = "gray") +
scale_y_continuous(breaks = c(0, 30, 60, 90, 104), labels = c(0, 30, 60, 90, 104)) +
theme_classic()
aggregate(data = province_sex_ratio, `性别比(女=100)` ~ 区域, FUN = mean) |>
ggplot(aes(x = `区域`, y = `性别比(女=100)`)) +
geom_bar(stat = "identity", aes(fill = `区域`), width = 0.5) +
geom_hline(yintercept = 104, linewidth = 0.8, lty = 2, color = "gray") +
scale_fill_brewer(palette = "Set1") +
theme_gray() +
labs(title = "中国的城市、镇、乡村性别比", subtitle = "2020 年",
caption = "数据来源:国家统计局统计年鉴") +
theme(plot.background = element_rect(fill = "orange"))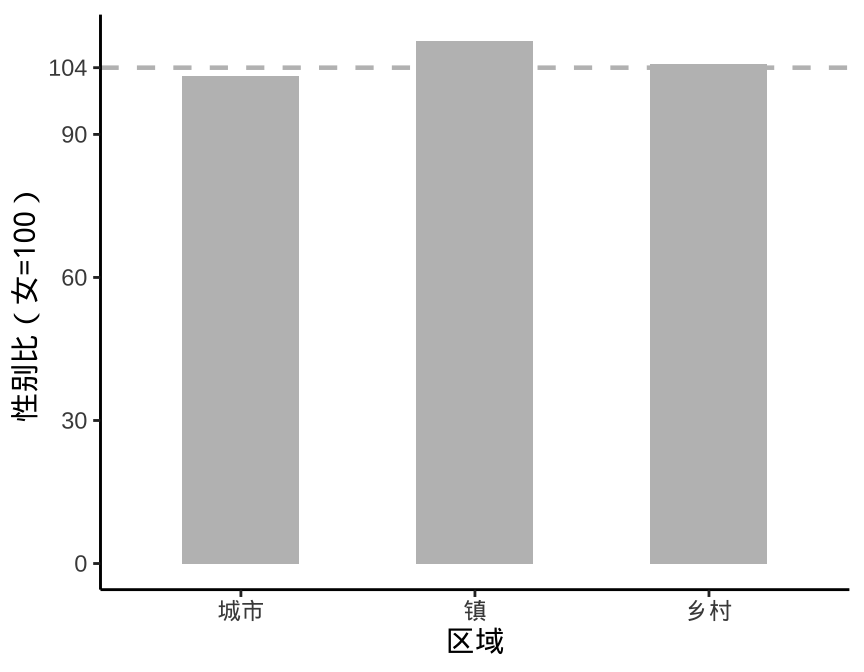
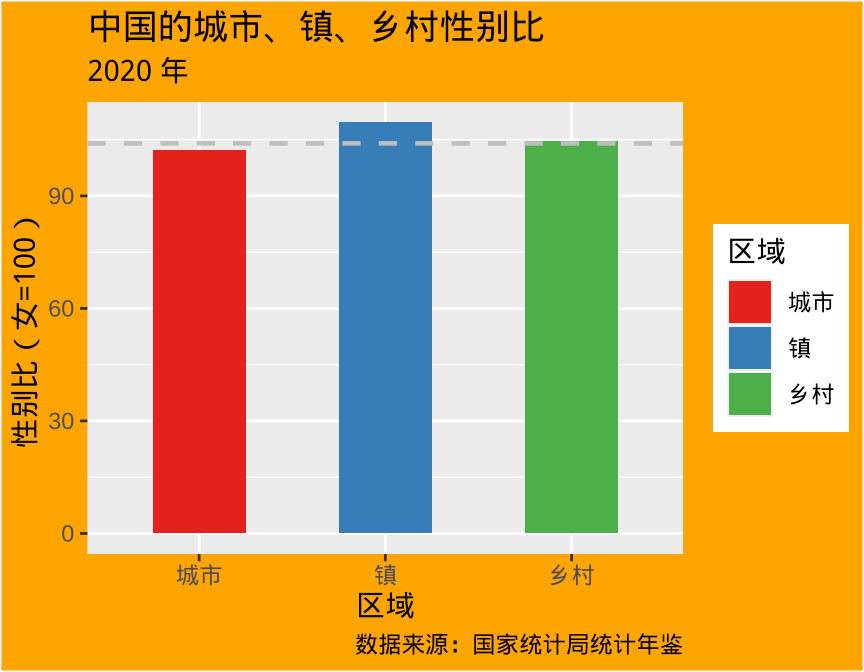
图 6.1: 简单胜过复杂
7 慎用三维图形
三维图形是很常见的,在数据可视化方面,三维图形的视觉效果好在直观,像饼图一样深入人心。在科学可视化中的仿真建模和应用统计中的函数型数据分析中常常用到,这些应用领域有一个共同的特点,就是表达确定性的趋势。相比于二维平面图形,静态的三维立体图形增加了一个维度,可以同时表达更多的数据,而且升维之后给人很酷、很高级的感觉,比较吸引眼球,R 语言有不少扩展包可以制作 3D 三维图形。
- graphics 包提供函数
persp()绘制三维透视图,基于 graphics 包, scatterplot3d 包(Ligges and Mächler 2003) 主要绘制三维散点图,而 plot3D 包(Soetaert 2021) 提供更加丰富的三维图形,曲面图、柱状图、分片图等。 - lattice 包 (Sarkar 2008) 提供函数
wireframe()绘制三维透视图,函数cloud()绘制三维散点图。 - rayshader 包(Morgan-Wall 2021)支持构建和渲染复杂的三维场景和数据可视化。
三维图形虽然很酷,但也因为数据之间的覆盖遮挡容易产生误导,所以需要慎用。为了保持准确直观的优点,避免透视产生的数据模糊,一个缓减的办法是使用交互的三维图形,用户可以随意旋转、缩放原始图形,观察任何一个角落。R 语言社区也有很多扩展包绘制交互的三维图形。
- rgl 包(Murdoch and Adler 2022)基于 OpenGL 技术,在 MacOS 系统上借助 XQuartz 设备渲染三维图形,也可以基于 WebGL 技术由浏览器渲染三维图形。plot3Drgl 包(Soetaert 2022)集成了 plot3D 包和 rgl 包的优势,扩展了 plot3D 包的功能,支持绘制基于 rgl 的交互图形。barplot3d 包(Wardell 2019)基于 rgl 包用于绘制三维柱(条)形图。
- plotly 包(Sievert 2020)基于 WebGL 技术由浏览器渲染三维图形,支持启用 GPU 渲染大规模数据。 echarts4r 包(Coene 2022)也基于 WebGL 技术,绘图功能类似 plotly 包。
- misc3d 包 (Feng and Tierney 2008) 基于 tcltk 包制作三维空间中的图形。
下面以美国历年男性死亡率数据为例,用不同的 R 包绘制静态的和交互的三维图形,以便读者观察效果,应用到具体的数据展示中。
# 导入数据
usa_mortality <- readRDS(file = "data/usa-mortality-2020.rds")
# 将连续型数据向量转化为颜色向量
colorize_numeric <- function(x) {
scales::col_numeric(palette = "viridis", domain = range(x))(x)
}
# 添加颜色
usa_mortality <- within(usa_mortality, {
color <- colorize_numeric(log10(Male))
})图7.1 展示 1933-2020 年美国男性死亡率的变化趋势,是用 lattice 包的 wireframe() 函数绘制的。
# tol_rainbow <- colorRamp(pals::tol.rainbow())
tol_rainbow <- colorRamp(viridisLite::viridis(25))
# 默认的调色板 hsv 数学原理,可视化图形,使用示例
# trellis.par.get("shade.colors")$palette
# function (irr, ref, height, saturation = 0.9)
# {
# hsv(h = height, s = 1 - saturation * (1 - (1 - ref)^0.5),
# v = irr)
# }
# https://stackoverflow.com/questions/50230598/
custom_palette <- function(irr, ref, height, ramp_fun = tol_rainbow) {
if (height != 1) {
## convert height to color using ramp_fun and map to HSV space
h.hsv <- rgb2hsv(t(ramp_fun(height)))
## reduce 'V' (brightness): multiply by irradiance
toReturn <- hsv(
h = h.hsv["h", ],
s = h.hsv["s", ],
v = 0.9 * h.hsv["v", ]
# v = irr * h.hsv["v", ]
)
} else {
toReturn <- "grey"
}
return(toReturn)
}
library(lattice)
wireframe(
data = usa_mortality, Male ~ Year * as.integer(Age),
shade = TRUE, drape = FALSE,
shade.colors.palette = custom_palette,
xlab = "年份", ylab = "年龄",
zlab = list("男性死亡率", rot = 90),
zlim = c(10^-4, 10^0.1),
scales = list(
arrows = FALSE, col = "black",
z = list(
log = 10, at = 10^(-4:0),
label = c(
expression(10^-4), expression(10^-3), expression(10^-2),
expression(10^-1), expression(10^0)
)
)
),
# 减少三维图形的边空
lattice.options = list(
layout.widths = list(
left.padding = list(x = -.6, units = "inches"),
right.padding = list(x = -1.0, units = "inches")
),
layout.heights = list(
bottom.padding = list(x = -.8, units = "inches"),
top.padding = list(x = -1.0, units = "inches")
)
),
par.settings = list(axis.line = list(col = "transparent")),
screen = list(z = -60, x = -70, y = 0)
)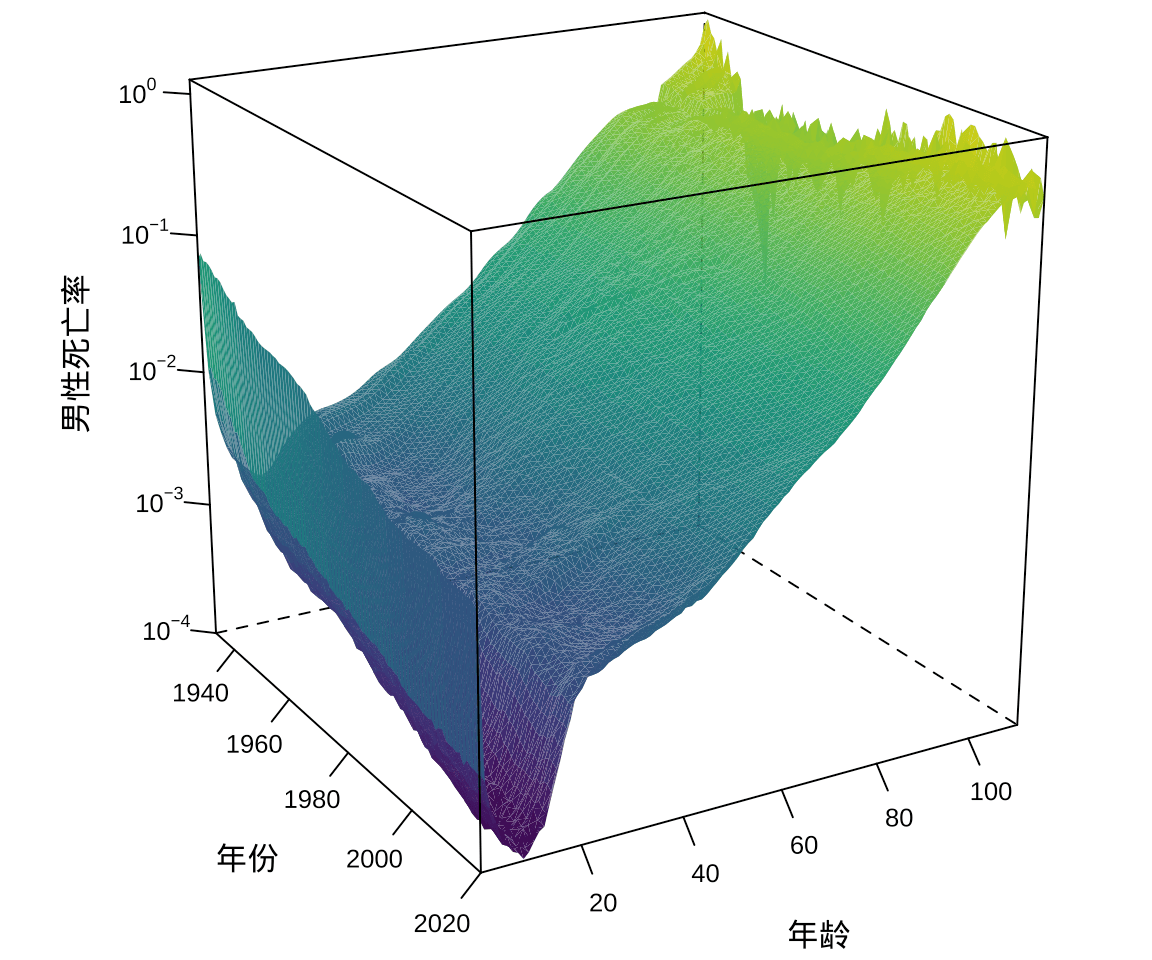
图 7.1: lattice 包制作三维透视图
图7.2 采用 scatterplot3d 包绘制静态的三维散点图。
library(scatterplot3d)
plt <- with(usa_mortality, {
scatterplot3d(
x = Year, y = Age, z = log10(Male),
color = color, # 给数据点上色
pch = 20, mar = c(3, 3, 0, 0.5) + 0.1,
xlab = "年份", ylab = "", zlab = "死亡率(对数)"
)
})
## 三维空间坐标转二维平面坐标
xy <- unlist(plt$xyz.convert(2040, 60, -4.5))
## 添加 y 轴标签
text(xy[1], xy[2], "\n年龄", srt = 45, pos = 2)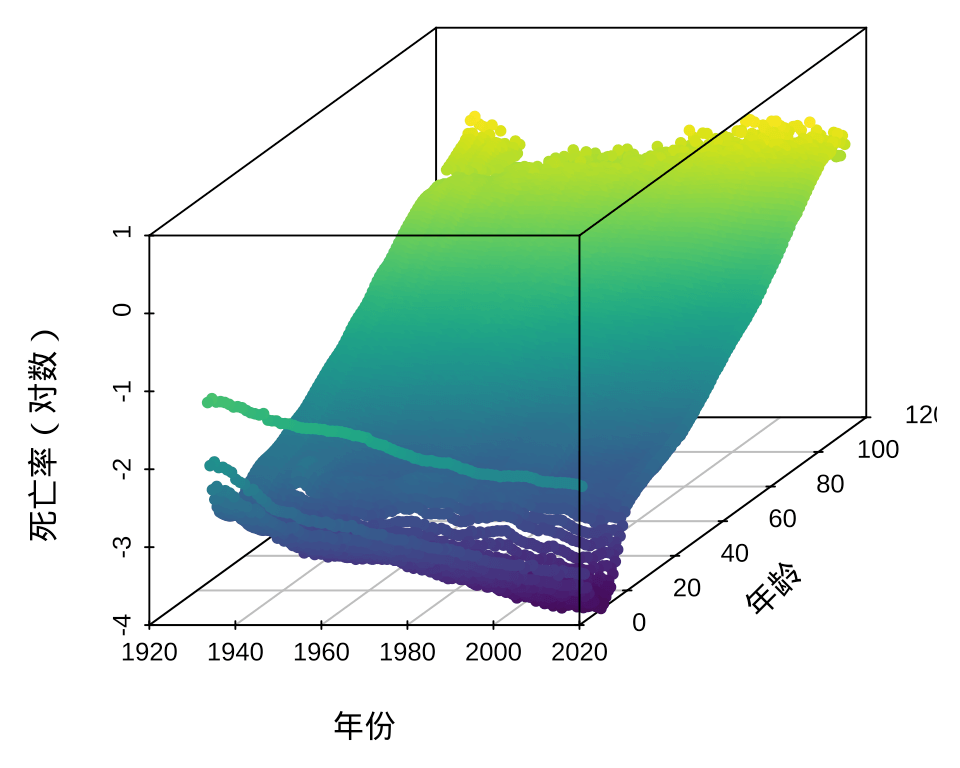
图 7.2: scatterplot3d 包制作三维散点图
图7.3 采用 plot3D 包分别绘制静态的三维散点图、柱状图、透视图、带状图。
# 数据重塑,长格式转宽格式
usa_mortality2 <- reshape(usa_mortality, direction = "wide",
idvar = "Year", drop = c("Female", "Total", "color"),
timevar = "Age", v.names = "Male", sep = "_"
)
# 数据类型转化为矩阵
usa_mortality2 <- as.matrix(usa_mortality2[, setdiff(colnames(usa_mortality2), "Year")])
# 绘制三维透视图形
library(plot3D)
op <- par(mar = c(1, 1.5, 0, 0), mfrow = c(2, 2))
scatter3D(
x = usa_mortality$Year, y = as.integer(usa_mortality$Age),
z = log10(usa_mortality$Male),
pch = 20, ticktype = "detailed", colkey = FALSE,
xlab = "\n年份", ylab = "\n年龄", zlab = "\n死亡率(对数)"
)
hist3D(
x = 1933:2020, y = 0:110, z = log10(usa_mortality2),
ticktype = "detailed", colkey = FALSE,
xlab = "\n年份", ylab = "\n年龄", zlab = "\n死亡率(对数)"
)
persp3D(
x = 1933:2020, y = 0:110, z = log10(usa_mortality2),
ticktype = "detailed", colkey = FALSE,
xlab = "\n年份", ylab = "\n年龄", zlab = "\n死亡率(对数)"
)
ribbon3D(
x = 1933:2020, y = 0:110, z = log10(usa_mortality2),
ticktype = "detailed", colkey = FALSE,
xlab = "\n年份", ylab = "\n年龄", zlab = "\n死亡率(对数)"
)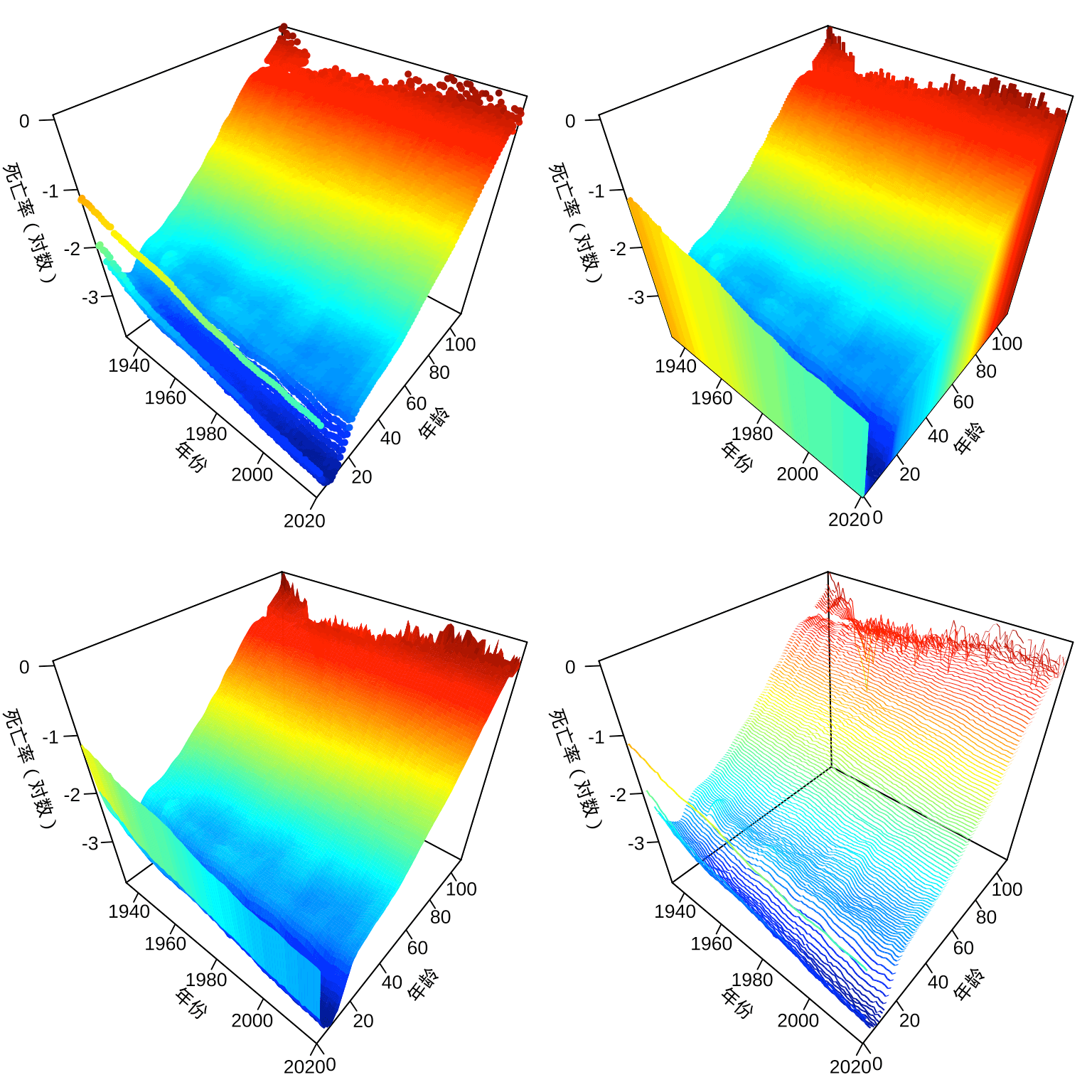
图 7.3: plot3D 包制作三维透视图
par(op)下图采用 rgl 包的函数 plot3d() 绘制交互的三维散点图。
library(rgl)
# 设置视角
view3d(
theta = 0, phi = -45, fov = 30,
zoom = 1, interactive = TRUE
)
# 绘制图形
plot3d(
log10(Male) ~ Age + Year, data = usa_mortality,
type = "p", col = color,
xlab = "年份", ylab = "年龄", zlab = "死亡率(对数)"
)图 7.4: rgl 包制作三维散点图

图 7.5: rgl 包制作三维散点图