本文以 R 包元数据中的描述字段作为语料,基于 tm 包 (Feinerer, Hornik, and Meyer 2008) 介绍文本分析中的基本概念和操作。我的专业背景不涉及生物信息,但是我会以 BioC 仓库(https://www.bioconductor.org/)而不是 CRAN 的R包元数据作为语料,一是了解一个陌生的领域,这令人兴奋,二是学习新的技术脱离熟悉的地方可以检查一下学习的效果,本文若有分析错误的地方,希望看到的朋友给提出来。
library(tm) # 文本语料库
## Loading required package: NLP
library(spacyr) # 词性标注1 数据获取
首先从 BioC 仓库下载获取 R 包元数据,存储到本地,后续就可以不连接网络了。加载数据后,去除重复的 R 包,筛选出 Package 和 Description 两个字段。
# bpdb <- tools:::BioC_package_db()
bpdb <- readRDS(file = "data/bioc-package-db-20250311.rds")
bpdb <- subset(bpdb,
subset = !duplicated(Package), select = c("Package", "Description")
)截至本文写作时间 2025-03-11 仓库 BioC 存放的 R 包有 3648 个,这就是本次示例中语料的规模了。下面是前几个 R 包的描述信息,这些 R 包默认是按照字母顺序排列的。
bpdb[1:6, ]## Package
## 1 a4
## 2 a4Base
## 3 a4Classif
## 4 a4Core
## 5 a4Preproc
## 6 a4Reporting
## Description
## 1 Umbrella package is available for the entire Automated\nAffymetrix Array Analysis suite of package.
## 2 Base utility functions are available for the Automated\nAffymetrix Array Analysis set of packages.
## 3 Functionalities for classification of Affymetrix\nmicroarray data, integrating within the Automated Affymetrix\nArray Analysis set of packages.
## 4 Utility functions for the Automated Affymetrix Array\nAnalysis set of packages.
## 5 Utility functions to pre-process data for the Automated\nAffymetrix Array Analysis set of packages.
## 6 Utility functions to facilitate the reporting of the\nAutomated Affymetrix Array Analysis Reporting set of packages.2 数据清理
在作为语料之前,先简单清洗一下,移除与文本无关的内容,比如链接、换行符、制表符、单双引号。
# 移除链接
bpdb$Description <- gsub(
pattern = "(<https:.*?>)|(<http:.*?>)|(<www.*?>)|(<doi:.*?>)|(<DOI:.*?>)|(<arXiv:.*?>)|(<bioRxiv:.*?>)",
x = bpdb$Description, replacement = ""
)
# 移除 \n \t \" \'
bpdb$Description <- gsub(pattern = "\n", x = bpdb$Description, replacement = " ", fixed = TRUE)
bpdb$Description <- gsub(pattern = "\t", x = bpdb$Description, replacement = " ", fixed = TRUE)
bpdb$Description <- gsub(pattern = "\"", x = bpdb$Description, replacement = " ", fixed = TRUE)
bpdb$Description <- gsub(pattern = "\'", x = bpdb$Description, replacement = " ", fixed = TRUE)3 词形还原
tm 包也支持提取词干 stemming 和词形还原 lemmatize 操作。不过,在这个例子里,我们只需要 lemmatize 操作。
tm 包自带的函数 stemCompletion() 需要一个词典或语料库来做还原 lemmatize 操作,不方便。SemNetCleaner 包的函数 singularize() 对名词效果不错。还原动词 (比如 applied, applies –> apply) 和副词 aux (was –> be) 使用 spacyr 包的函数 spacy_parse() ,该函数可以识别词性。
library(spacyr)先看一个例子,可以看到 spacyr 包解析文本的结果。结果是一个数据框,doc_id、sentence_id 和 token_id 分别对应文档、句子和 Token 的编号。Token 化 就是句子转化为词的过程,单个词叫 Token 。lemma 表示词形还原的结果,pos 表示词性。
# R 包 a4 的描述字段
x <- "Umbrella package is available for the entire Automated Affymetrix Array Analysis suite of package."
names(x) <- "a4"
spacy_parse(x)
## successfully initialized (spaCy Version: 3.7.2, language model: en_core_web_sm)
## doc_id sentence_id token_id token lemma pos entity
## 1 a4 1 1 Umbrella umbrella NOUN ORG_B
## 2 a4 1 2 package package NOUN
## 3 a4 1 3 is be AUX
## 4 a4 1 4 available available ADJ
## 5 a4 1 5 for for ADP
## 6 a4 1 6 the the DET
## 7 a4 1 7 entire entire ADJ
## 8 a4 1 8 Automated Automated PROPN ORG_B
## 9 a4 1 9 Affymetrix Affymetrix PROPN ORG_I
## 10 a4 1 10 Array Array PROPN ORG_I
## 11 a4 1 11 Analysis Analysis PROPN ORG_I
## 12 a4 1 12 suite suite NOUN
## 13 a4 1 13 of of ADP
## 14 a4 1 14 package package NOUN
## 15 a4 1 15 . . PUNCTspacyr 是 spaCy 的 R 语言接口(通过 reticulate 包引入的),实际解析效果要看其内部调用的 spacy 模块。本文使用的 spaCy 版本 3.7.2,对于英文环境还是不错的。下面解析全量的数据,简单起见就用 spacyr 包来做 lemmatize。
db <- bpdb$Description
names(db) <- bpdb$Package
db_parse <- spacy_parse(db)
# 恢复
db_parse <- aggregate(db_parse, lemma ~ doc_id, paste, collapse = " ", sep = "")
bpdb <- merge(bpdb, db_parse, by.x = "Package", by.y = "doc_id", all.x = TRUE, sort = FALSE)
head(bpdb)## Package
## 1 a4
## 2 a4Base
## 3 a4Classif
## 4 a4Core
## 5 a4Preproc
## 6 a4Reporting
## Description
## 1 Umbrella package is available for the entire Automated Affymetrix Array Analysis suite of package.
## 2 Base utility functions are available for the Automated Affymetrix Array Analysis set of packages.
## 3 Functionalities for classification of Affymetrix microarray data, integrating within the Automated Affymetrix Array Analysis set of packages.
## 4 Utility functions for the Automated Affymetrix Array Analysis set of packages.
## 5 Utility functions to pre-process data for the Automated Affymetrix Array Analysis set of packages.
## 6 Utility functions to facilitate the reporting of the Automated Affymetrix Array Analysis Reporting set of packages.
## lemma
## 1 umbrella package be available for the entire Automated Affymetrix Array Analysis suite of package .
## 2 base utility function be available for the Automated Affymetrix Array Analysis set of package .
## 3 functionality for classification of Affymetrix microarray datum , integrate within the Automated Affymetrix Array Analysis set of package .
## 4 utility function for the Automated Affymetrix Array Analysis set of package .
## 5 utility function to pre - process datum for the Automated Affymetrix Array Analysis set of package .
## 6 utility function to facilitate the reporting of the Automated Affymetrix Array Analysis report set of package .# 提取词干
# bpdb_desc <- tm_map(bpdb_desc, stemDocument, language = "english")
# 或者调用 SnowballC 包
# bpdb_desc <- tm_map(bpdb_desc, content_transformer(SnowballC::wordStem), language = "english")
# 词形还原
# bpdb_desc <- tm_map(bpdb_desc, SemNetCleaner::singularize)4 制作语料
清洗后的文本作为语料,3000 多个 R 包的描述字段,tm 包的函数 VCorpus() 和 VectorSource() 就是将字符串(文本)向量转化为语料的。
library(tm)
bpdb_desc <- VCorpus(x = VectorSource(bpdb$lemma))查看数据类型,这是一个比较复杂的数据结构 — tm 包定义的 "VCorpus" "Corpus" 类型,本质上还是一个列表,但是层层嵌套。
class(bpdb_desc)## [1] "VCorpus" "Corpus"is.list(bpdb_desc)## [1] TRUE查看列表中第一个元素,这个元素本身也是列表。
str(bpdb_desc[1])## Classes 'VCorpus', 'Corpus' hidden list of 3
## $ content:List of 1
## ..$ :List of 2
## .. ..$ content: chr "umbrella package be available for the entire Automated Affymetrix Array Analysis suite of package ."
## .. ..$ meta :List of 7
## .. .. ..$ author : chr(0)
## .. .. ..$ datetimestamp: POSIXlt[1:1], format: "2025-03-27 12:41:25"
## .. .. ..$ description : chr(0)
## .. .. ..$ heading : chr(0)
## .. .. ..$ id : chr "1"
## .. .. ..$ language : chr "en"
## .. .. ..$ origin : chr(0)
## .. .. ..- attr(*, "class")= chr "TextDocumentMeta"
## .. ..- attr(*, "class")= chr [1:2] "PlainTextDocument" "TextDocument"
## $ meta : list()
## ..- attr(*, "class")= chr "CorpusMeta"
## $ dmeta :'data.frame': 1 obs. of 0 variablesstr(bpdb_desc[[1]])## List of 2
## $ content: chr "umbrella package be available for the entire Automated Affymetrix Array Analysis suite of package ."
## $ meta :List of 7
## ..$ author : chr(0)
## ..$ datetimestamp: POSIXlt[1:1], format: "2025-03-27 12:41:25"
## ..$ description : chr(0)
## ..$ heading : chr(0)
## ..$ id : chr "1"
## ..$ language : chr "en"
## ..$ origin : chr(0)
## ..- attr(*, "class")= chr "TextDocumentMeta"
## - attr(*, "class")= chr [1:2] "PlainTextDocument" "TextDocument"str(bpdb_desc[[1]][[1]])## chr "umbrella package be available for the entire Automated Affymetrix Array Analysis suite of package ."查看文档的内容,tm 包提供自己的函数 inspect() 来查看语料信息。
inspect(bpdb_desc[[1]])## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 99
##
## umbrella package be available for the entire Automated Affymetrix Array Analysis suite of package .inspect(bpdb_desc[1])## <<VCorpus>>
## Metadata: corpus specific: 0, document level (indexed): 0
## Content: documents: 1
##
## [[1]]
## <<PlainTextDocument>>
## Metadata: 7
## Content: chars: 99语料库中的第一段文本的长度 98 个字符。不妨顺便统计一下语料库中文本长度的分布,如下。
hist(nchar(bpdb$Description))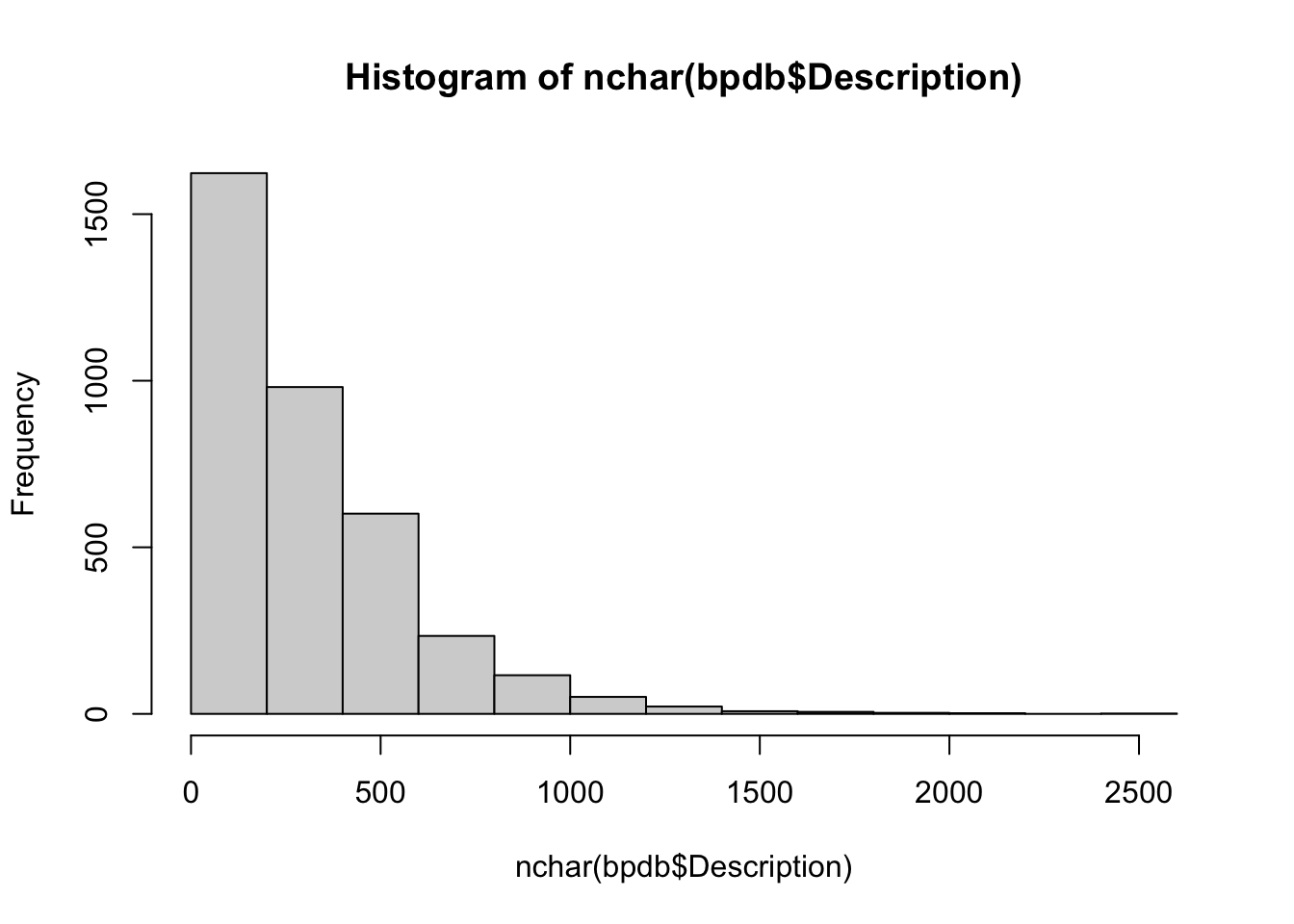
quantile(nchar(bpdb$Description))## 0% 25% 50% 75% 100%
## 20.0 110.0 242.5 433.0 2439.075% 的 R 包的描述信息不超过 500 个字符。
5 语料元数据
函数 VCorpus() 将文本向量制作成语料后,制作语料的过程信息就成了语料的元数据,比如制作语料时间等。下面查看语料的元数据。
meta(bpdb_desc)## data frame with 0 columns and 3648 rowsmeta(bpdb_desc[[1]])## author : character(0)
## datetimestamp: 2025-03-27 12:41:25.953104019165
## description : character(0)
## heading : character(0)
## id : 1
## language : en
## origin : character(0)在制作语料的过程中,可以添加一些元数据信息,比如语料的来源、创建者。元数据的管理由函数 DublinCore() 完成。
DublinCore(bpdb_desc[[1]], tag = "creator") <- "The Core CRAN Team"元数据中包含贡献者 contributor、 创建者 creator 和创建日期 date 等信息。
meta(bpdb_desc[[1]])## author : The Core CRAN Team
## datetimestamp: 2025-03-27 12:41:25.953104019165
## description : character(0)
## heading : character(0)
## id : 1
## language : en
## origin : character(0)元数据的 author 字段加上了 “The Core CRAN Team” 。
6 清理语料
我们的语料库 bpdb_desc 本质上是一个文本向量, tm 包有一个函数 tm_map() 可以向量化的操作,类似于 Base R 内置的 lapply() 函数 。如下一连串操作分别是转小写、移除多余空格、去除数字、去除标点。
# 转小写
bpdb_desc <- tm_map(bpdb_desc, content_transformer(tolower))
# 去除多余空白
bpdb_desc <- tm_map(bpdb_desc, stripWhitespace)
# 去除数字
bpdb_desc <- tm_map(bpdb_desc, removeNumbers)
# 去除标点,如逗号、括号等
bpdb_desc <- tm_map(bpdb_desc, removePunctuation)还可以去除一些停止词,哪些是停止词也可以自定义。
# 停止词去除
bpdb_desc <- tm_map(bpdb_desc, removeWords, words = stopwords("english"))
# 自定义的停止词
bpdb_desc <- tm_map(
bpdb_desc, removeWords,
words = c(
"et", "etc", "al", "i.e.", "e.g.", "package", "provide", "method",
"function", "approach", "reference", "implement", "contain", "include", "can", "file", "use"
)
)7 文档词矩阵
由语料库可以生成一个巨大的文档词矩阵,矩阵中的元素是词在文档中出现的次数(词频)。3648 个文档 9888 个词构成一个维度为 \(3648\times9888\) 的矩阵,非 0 元素 80479 个,0 元素 35990945 个,矩阵是非常稀疏的,稀疏性接近 100%(四舍五入的结果)。最长的一个词达到 76 字符。
dtm <- DocumentTermMatrix(bpdb_desc)
inspect(dtm)## <<DocumentTermMatrix (documents: 3648, terms: 9888)>>
## Non-/sparse entries: 80479/35990945
## Sparsity : 100%
## Maximal term length: 76
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs analysis annotation base cell datum expression gene sample seq sequence
## 1302 1 0 1 0 1 1 15 0 0 0
## 1695 1 2 3 0 0 0 0 0 0 6
## 178 2 0 1 13 2 5 5 1 1 3
## 1798 9 0 0 0 3 0 8 0 0 0
## 2052 3 0 0 0 3 2 11 0 0 0
## 2271 5 0 1 0 7 0 0 3 0 0
## 2542 1 0 4 0 6 4 6 0 0 0
## 2913 4 0 1 0 3 3 11 0 0 2
## 3024 0 2 0 0 0 0 0 2 0 0
## 3343 2 0 2 0 3 0 0 0 0 2每个 R 包的描述文本是一个文档,共有 3648 个文档,每段文本分词后,最终构成 9888 个词。
有了文档词矩阵,可以基于矩阵来操作,比如统计出来出现 500 次以上的词,找到与词 array 关联度 0.2 以上的词。
# 出现 500 次以上的词
findFreqTerms(dtm, 500)## [1] "analysis" "annotation" "base" "cell" "datum"
## [6] "expression" "gene" "model" "sample" "seq"
## [11] "sequence" "set"# 找到与词 array 关联度 0.2 以上的词
findAssocs(dtm, "array", 0.2)## $array
## affymetrix acme algorithms insensitive
## 0.35 0.30 0.30 0.30
## quite epic additon audience
## 0.30 0.28 0.25 0.25
## calculte horvathmethylchip infinium sarrays
## 0.25 0.25 0.25 0.25
## tango tranditional puma tiling
## 0.25 0.25 0.23 0.23
## ordinary showing
## 0.21 0.21findAssocs(dtm, "annotation", 0.2)## $annotation
## assemble repository public annotationdbi chip
## 0.45 0.44 0.42 0.29 0.29
## database regular affymetrix expose intend
## 0.28 0.27 0.25 0.24 0.20findAssocs(dtm, "gene", 0.2)## $gene
## expression set enrichment biological identify
## 0.46 0.35 0.33 0.27 0.25
## term driver analysis bear express
## 0.25 0.23 0.22 0.22 0.22
## gsea gseamine gseamining hierarchically leadind
## 0.22 0.22 0.22 0.22 0.22
## meaninful popularity reundandcy suppressor unfortunately
## 0.22 0.22 0.22 0.22 0.22
## wordcloud always answer reason
## 0.22 0.21 0.21 0.20所谓关联度即二者出现在同一个文档中的频率,即共现率。
# 参数 sparse 值越大保留的词越多
dtm2 <- removeSparseTerms(dtm, sparse = 0.9)
# 移除稀疏词后的文档词矩阵
inspect(dtm2)## <<DocumentTermMatrix (documents: 3648, terms: 14)>>
## Non-/sparse entries: 8292/42780
## Sparsity : 84%
## Maximal term length: 10
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs analysis annotation base cell datum expression gene sample seq sequence
## 1121 6 0 1 0 5 0 3 1 1 0
## 1258 0 1 1 0 1 5 8 4 1 0
## 1302 1 0 1 0 1 1 15 0 0 0
## 1749 2 0 0 6 0 3 8 0 3 1
## 178 2 0 1 13 2 5 5 1 1 3
## 2542 1 0 4 0 6 4 6 0 0 0
## 2913 4 0 1 0 3 3 11 0 0 2
## 2953 1 0 3 0 1 4 5 8 0 0
## 3040 5 0 1 5 1 3 2 0 2 0
## 3435 0 1 0 0 7 0 2 1 7 2原始的文档词矩阵非常稀疏,是因为有些词很少在文档中出现,移除那些给矩阵带来很大稀疏性的词,把这些词去掉并不会太影响与原来矩阵的相关性。
有了矩阵之后,各种统计分析手段,即矩阵的各种操作都可以招呼上来。
8 文本主题
都是属于生物信息这个大类,不妨考虑 3 个主题,具体多少个主题合适,留待下回分解(比较不同主题数量下 perplexity 的值来决定)。类似 CRAN 上的任务视图,BiocViews 是生物信息的任务视图,还有层次关系。
library(topicmodels)
BVEM <- LDA(dtm, k = 3, control = list(seed = 2025))找到每个文档最可能归属的主题。
BTopic <- topics(BVEM, 1)
head(BTopic, 10)## 1 2 3 4 5 6 7 8 9 10
## 1 1 1 1 1 2 2 2 3 3# 每个主题各有多少 R 包
table(BTopic)## BTopic
## 1 2 3
## 971 1253 1424# 1 号主题对应的 R 包
bpdb[which(BTopic == 1), c("Package", "Description")] |> head()## Package
## 1 a4
## 2 a4Base
## 3 a4Classif
## 4 a4Core
## 5 a4Preproc
## 14 ADaCGH2
## Description
## 1 Umbrella package is available for the entire Automated Affymetrix Array Analysis suite of package.
## 2 Base utility functions are available for the Automated Affymetrix Array Analysis set of packages.
## 3 Functionalities for classification of Affymetrix microarray data, integrating within the Automated Affymetrix Array Analysis set of packages.
## 4 Utility functions for the Automated Affymetrix Array Analysis set of packages.
## 5 Utility functions to pre-process data for the Automated Affymetrix Array Analysis set of packages.
## 14 Analysis and plotting of array CGH data. Allows usage of Circular Binary Segementation, wavelet-based smoothing (both as in Liu et al., and HaarSeg as in Ben-Yaacov and Eldar), HMM, GLAD, CGHseg. Most computations are parallelized (either via forking or with clusters, including MPI and sockets clusters) and use ff for storing data.每个主题下的 10 个 Top 词
BTerms <- terms(BVEM, 10)
BTerms[, 1:3]## Topic 1 Topic 2 Topic 3
## [1,] "datum" "datum" "gene"
## [2,] "annotation" "sequence" "datum"
## [3,] "object" "analysis" "analysis"
## [4,] "affymetrix" "design" "cell"
## [5,] "mask" "user" "expression"
## [6,] "genome" "platform" "model"
## [7,] "database" "read" "base"
## [8,] "chip" "plot" "sample"
## [9,] "store" "name" "seq"
## [10,] "public" "create" "set"