Everything is related to everything else, but near things are more related than distant things.
— The First Law of Geography, Waldo Tobler (1969)
1 高斯过程
高斯过程在概率论这门课程中是非常基础且重要的概念,它的应用非常广泛,在金融数据分析、空间数据分析、图像处理、自然语言处理等领域都有应用的身影。本文考虑二维的高斯过程,及其在空间数据分析中的应用。
1.1 高斯过程定义
先回顾一下高斯过程的定义,高斯过程是由均值函数和协方差函数(常称之为核函数)来定义的,高斯过程的一个具体实现是一组有限的随机变量(实际上,可以有无穷多个),其任意有限个随机变量的联合分布是多元正态分布。
值得注意,高斯过程用核函数来定义而不是类似多元正态分布的协方差矩阵。核函数是两个点之间距离的函数,这里涉及距离的定义,以及函数的具体形式。最常见的距离是欧氏空间的平方根距离,在空间数据分析中,遇到相距非常远的点之间的度量会用到球面距离(非欧氏空间)。在金融数据分析中,两个点之间的距离,可能是两个时间点之间的时间差。因此,所谓距离可能是时间上的,也可能是空间上的。
简单起见,下文都是欧氏距离,以 \(\|x_i - x_j \|_2\) 表示点 \(x_i\) 和点 \(x_j\) 之间的欧氏距离。本文仅考虑二维的情形,所以,点 \(x_i\) 和 \(x_j\) 都是二维平面上的点。关于距离的函数,它必是一个随距离的增加而单调递减的函数,也简单起见,考虑指数型函数。随机过程 \(\mathcal{S}\) 的一个实现 \(S(x), x\in A \subset \mathbb{R}^2\) 的自协方差函数如下:
\[ \mathsf{Cov}(S(x_i), S(x_j)) = \sigma^2 \exp\Big(- \frac{\|x_i - x_j \|_2}{\phi} \Big) \]
其中, \(\sigma^2\) 和 \(\phi\) 分别代表随机过程的尺度参数和长度参数。既然在每个位置上都对应一个服从高斯分布的随机变量,那么这个位置上除了已知方差 \(\sigma^2\) 还需要已知均值,均值在每个位置上都可以是不同的,简单起见,就都设定为 0。
值得注意,高斯过程所涉及的随机变量的数目可以是无穷的,只是随机变量 \(S(x_i)\) 和 \(S(x_j)\) 之间的相关性由如上的协方差函数确定。在实际应用场景中,不可能存在无穷的观测值,肯定是有限的,只是样本量有大有小罢了。在样本量很大时(大于 1000),计算会遇到一些困难,这是一般性的问题。在使用概率编程语言 Stan 时,会常常遇到瓶颈而且很明显1。
1.2 模拟高斯过程
还是简单起见,考虑一个只含一个协变量\(D\)和一个平稳高斯过程\(S(x)\)的泊松型高斯过程回归模型。协变量 \(D(x)\) 与位置有关的,但是,未知的回归参数 \(\beta\) 是与位置无关的。但是响应变量 \(Y(x)\) 是与位置有关的,且在每一个位置,它的观测值\(Y(x)\)服从强度为\(u(x)\lambda(x)\)的泊松分布。
\[ \begin{aligned} Y(x) &\sim \mathrm{Poisson}(u(x)\lambda(x)) \\ \log\big(\lambda(x)\big) &= D \beta + S(x) \end{aligned} \]
其中,随机过程 \(S(x)\) 服从零均值平稳高斯过程,漂移项 \(u(x)\) 是已知的,可观测的,常由人为因素决定。下面根据此模型生成数据,不妨先设置模型各参数的值,回归系数 \(\beta = 1\) ,尺度参数(方差) \(\sigma^2 = 0.25\) ,长度参数 \(\phi = 0.1\) 。观测值 \(Y\) (需要模拟的)来自平面上方形的规则网格上的格点,
生成模拟数据的代码如下:
# 网格划分
N <- 16
X <- expand.grid(x1 = 1:N / N, x2 = 1:N / N)
# 二维空间高斯过程超参数
sigma <- 0.5
phi <- 0.1
beta <- 1
# 设置随机数种子
set.seed(20222022)
# 协方差矩阵
R <- sigma^2 * exp(-as.matrix(dist(X)) / phi)
# 协变量是一维的随机变量
D <- rnorm(N^2, 0, 1)
# 协方差分解
V <- chol(R)
# 随机变量
eta <- rnorm(N * N, 0, 1)
# 漂移项
u <- rep(c(1, 2), each = N * N / 2)
# 强度
lambda <- u * exp(D * beta + V %*% eta)
# 响应变量
y <- rpois(N * N, lambda = lambda)
# 模拟数据
sim_dat <- cbind.data.frame(X, D, y, u)
# 查看数据
head(sim_dat)## x1 x2 D y u
## 1 0.0625 0.0625 0.7889 2 1
## 2 0.1250 0.0625 -0.3491 2 1
## 3 0.1875 0.0625 -1.2722 0 1
## 4 0.2500 0.0625 -1.3882 0 1
## 5 0.3125 0.0625 1.3764 7 1
## 6 0.3750 0.0625 -1.3328 0 1其中,x1 和 x2 表示网格中格点的坐标,\(D\) 表示对应位置的协变量的观测值,\(y\) 表示响应变量的值,\(u\) 是漂移项。
library(ggplot2)
ggplot(data = sim_dat, aes(x = x1, y = x2)) +
geom_tile(aes(fill = y)) +
scale_fill_distiller(palette = "Spectral") +
theme_minimal() +
labs(x = expression(x[1]), y = expression(x[2]))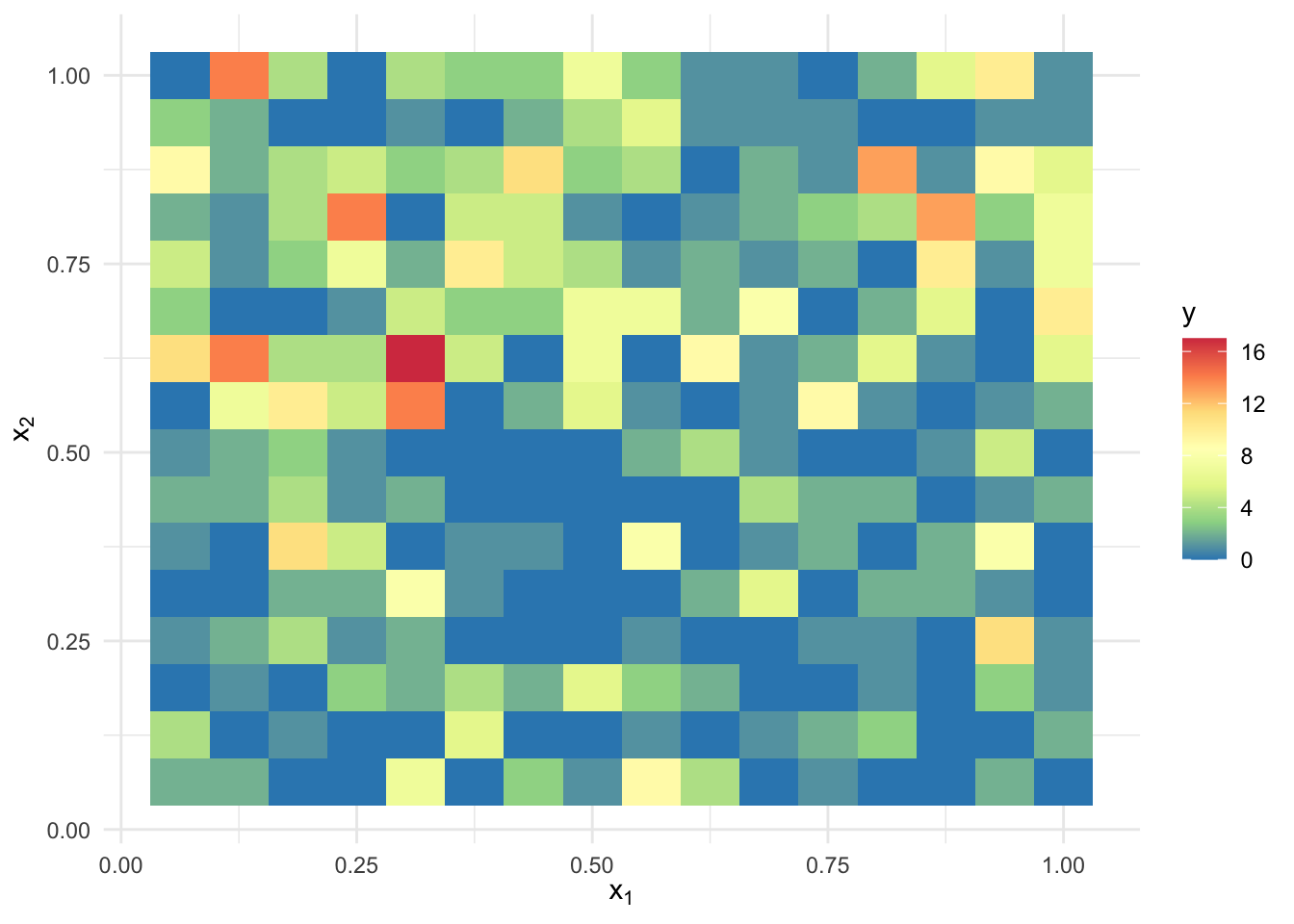
图 1.1: 模拟高斯过程回归模型
没有考虑位置因素的情况下,就是一个普通的广义线性回归模型,且仅含有一个协变量 D。
fit_poisson_glm <- glm(
data = sim_dat, y ~ D + 0,
family = poisson(link = "log"),
offset = log(u)
)
summary(fit_poisson_glm)##
## Call:
## glm(formula = y ~ D + 0, family = poisson(link = "log"), data = sim_dat,
## offset = log(u))
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## D 0.9168 0.0305 30 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 1039.20 on 256 degrees of freedom
## Residual deviance: 440.71 on 255 degrees of freedom
## AIC: 972.8
##
## Number of Fisher Scoring iterations: 4协变量 D 的回归系数为 0.9168 ,与预设的参数真值 1 相去不远。下面采用 spaMM [1] 包拟合该模拟数据集,估计模型的各个参数值。
library(spaMM)
fit_rongelap_spamm <- fitme(y ~ 0 + D + Matern(1 | x1 + x2) + offset(log(u)),
family = poisson(link = "log"), data = sim_dat,
fixed = list(nu = 0.5)
)
summary(fit_rongelap_spamm)## formula: y ~ 0 + D + Matern(1 | x1 + x2) + offset(log(u))
## Estimation of corrPars and lambda by ML (p_v approximation of logL).
## Estimation of fixed effects by ML (p_v approximation of logL).
## Estimation of lambda by 'outer' ML, maximizing logL.
## family: poisson( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## D 0.9111 0.05485 16.61
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Correlation parameters:
## 1.nu 1.rho
## 0.50 15.41
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## x1 + x2 : 0.2329
## # of obs: 256; # of groups: x1 + x2, 256
## ------------- Likelihood values -------------
## logLik
## logL (p_v(h)): -454.7回归系数的估计值为 \(\hat{\beta}=0.9111\) ,高斯过程的尺度参数的估计值为 \(\hat{\sigma^2}= 0.2329\) ,而长度参数的估计值为 \(\hat{\phi} = 1/15.41 = 0.0649\) 。
下面采用 glmmTMB [2] 包拟合该模拟数据集,估计模型的各个参数值。
library(glmmTMB)
# 根据位置坐标标准化
sim_dat$loc <- glmmTMB::numFactor(scale(sim_dat$x1), scale(sim_dat$x2))
# 根据位置自增 ID
sim_dat$ID <- factor(rep(1, nrow(sim_dat)))
# 拟合模型
fit_poisson_glmmtmb <- glmmTMB::glmmTMB(
formula = y ~ 0 + D + exp(loc + 0 | ID),
data = sim_dat, family = poisson(link = "log"),
offset = log(u)
)
fixef(fit_poisson_glmmtmb)##
## Conditional model:
## D
## 0.911我们发现,回归系数、随机过程的尺度参数、对数似然的值和 spaMM 包的输出结果几乎一样,但 glmmTMB 包不能给出随机过程的自协方差函数中长度参数 \(\phi\) 的估计。
2 应用
下面这个例子不同于模拟数据集,它来自真实的应用场景。
2.1 数据描述
数据集 rongelap 记录了朗格拉普岛的核污染状况,该数据集是科学家研究岛上在遭受核打击后的生态恢复情况时采集的。科学家在岛上划分了网格,在每个格点处放置仪器并持续一段时间,观测到放射性元素释放的粒子数,则该处的放射强度为单位时间内释放的粒子数,即观测到的粒子数除以对应的观测时间。各个采样点的位置及对应的核辐射强度见下图。
# 加载数据
rongelap <- readRDS(file = "data/rongelap.rds")
rongelap_coastline <- readRDS(file = "data/rongelap_coastline.rds")
library(rgl)
# 设置 Web GL 渲染
options(rgl.useNULL = TRUE)
options(rgl.printRglwidget = TRUE)
# https://stackoverflow.com/questions/22257196
# 设置用户观察视角
view_matrix <- matrix(
data =
c(
0.9369147, -0.3488074, 0.0229013, 0,
0.1040908, 0.3409360, 0.9343059, 0,
-0.3337006, -0.8729811, 0.3557355, 0,
0.0000000, 0.0000000, 0.0000000, 1
),
nrow = 4, byrow = T
)
view3d(
userMatrix = view_matrix,
fov = 30,
zoom = 0.75
)
# view3d(
# theta = 0, # 负值表示绕 y 轴(垂直轴)逆时针旋转的角度
# # phi = -45, # 负值表示绕 x 轴(水平轴)逆时针旋转的角度
# phi = -75, # 负值表示绕 x 轴(水平轴)逆时针旋转的角度
# fov = 30, #
# zoom = 0.75, # 缩放
# interactive = TRUE
# )
# 将连续型数据向量转化为颜色向量
colorize_numeric <- function(x) {
scales::col_numeric(palette = "viridis", domain = range(x))(x)
}
# 在数据集 quakes 上添加新的数据 color
rongelap_df <- within(rongelap, {
lambda <- counts / time
color <- colorize_numeric(lambda)
})
rongelap_coastline_df <- rongelap_coastline
rongelap_coastline_df$cZ <- 0
# 绘制图形
with(rongelap_df, {
plot3d(
x = cX, y = cY, z = lambda,
# col = color,
aspect = c(1.58, 1, 1),
type = "h", xlab = "横坐标(米)", ylab = "纵坐标(米)",
zlab = "辐射强度"
)
grid3d(side = "z")
points3d(x = cX, y = cY, z = lambda,
# col = color,
size = 5)
lines3d(x = rongelap_coastline_df$cX,
y = rongelap_coastline_df$cY,
z = rongelap_coastline_df$cZ)
})图 2.1: 采样点及核辐射强度分布
采样点及核辐射强度分布
图中横纵坐标的参考原点在岛的东北角,每条线段的高度代表辐射强度。可以观察到岛上有四个地方采样密集程度比其它地方高。
2.2 拟合模型
下面用两个采用不同方法的 R 包拟合这同一份数据,一来验证 brms 包的拟合情况(是否合理),二来在拟合速度和效果上与 glmmTMB 包形成比较。
2.2.1 glmmTMB
glmmTMB 包基于 TMB(Automatic Differentiation computation with Template Model Builder) [3] 框架,实现一种拉普拉斯近似算法来估计空间广义线性混合效应模型的参数。glmmTMB 包的核心函数是 glmmTMB(),其使用语法和函数 glm() 类似。不同之处对于位置及其相关性的描述,这里要先将位置坐标标准化且给每个位置分配一个唯一的 ID。值得注意,位置及其 ID 都是因子型数据。这里位置相关性选择指数型,函数 glmmTMB() 还支持梅隆型 mat 和高斯型 gau 等相关性结构。
library(glmmTMB)
# 根据位置坐标标准化
rongelap$loc <- glmmTMB::numFactor(scale(rongelap$cX), scale(rongelap$cY))
# 根据位置自增 ID
rongelap$ID <- factor(rep(1, nrow(rongelap)))
# 拟合模型
fit_rongelap_glmmtmb <- glmmTMB::glmmTMB(
formula = counts ~ 1 + exp(loc + 0 | ID),
data = rongelap, family = poisson(link = "log"),
offset = log(time)
)
# 输出拟合结果
# summary(fit_rongelap_glmmtmb)它返回一个 glmmTMB 类型的数据对象,提供的方法如下:
- 函数
summary()类似stats::summary.glm(),打印输出模型结果,如 AIC、BIC、对数似然值、随机效应的标准差和协方差矩阵,固定效应等。此处,随机效应的标准偏差为 0.544,方差为 \(0.544^2 = 0.2959\)。 - 函数
ranef()提取随机效应,这里是 157 维的,随机效应的协方差矩阵是 \(157 \times 157\) 维的,篇幅所限,此处略去。 - 函数
fixef()提取模型的固定效应,此处仅有截距,截距为 1.82007。 - 函数
logLik()提取模型的对数似然。 - 函数
residuals()提取模型的拟合残差。
# 对数似然
logLik(fit_rongelap_glmmtmb)## 'log Lik.' -1321 (df=3)# 固定效应,此处即截距
fixef(fit_rongelap_glmmtmb)##
## Conditional model:
## (Intercept)
## 1.833 参考文献
参考 Stan 的用户指南Stan User’s Guide↩︎