\[ \def\bm#1{{\boldsymbol #1}} \]
本文内容属于空间分析的范畴,空间分析的内容十分广泛,本文仅以一个模型和一个数据简略介绍。一个模型是空间广义线性混合效应模型,空间广义线性混合效应模型在流行病学、生态学、环境学等领域有广泛的应用,如预测某地区内的疟疾流行度分布,预测某地区 PM 2.5 污染物浓度分布等。一个数据来自生态学领域,数据集所含样本量不大,但每个样本收集成本不小,采集样本前也都有实验设计,数据采集的地点是预先设定的。下面将对真实数据分析和建模,任务是预测核辐射强度在朗格拉普岛上的分布。
1 数据说明
在第二次世界大战的吉尔伯特及马绍尔群岛战斗中,美国占领了马绍尔群岛。战后,美国在该群岛的比基尼环礁中陆续进行了许多氢弹核试验,对该群岛造成无法弥补的环境损害。位于南太平洋的朗格拉普环礁是马绍尔群岛的一部分,其中,朗格拉普岛是朗格拉普环礁的主岛,修建有机场,在太平洋战争中是重要的军事基地。朗格拉普岛距离核爆炸的位置较近,因而被放射性尘埃笼罩了,受到严重的核辐射影响,从度假胜地变成人间炼狱,居民出现上吐下泻、皮肤灼烧、脱发等症状。即便是 1985 年以后,那里仍然无人居住,居民担心核辐射对身体健康的影响。又几十年后,一批科学家来到该岛研究生态恢复情况,评估当地居民重返家园的可行性。实际上,该岛目前仍然不适合人类居住,只有经批准的科学研究人员才能登岛。
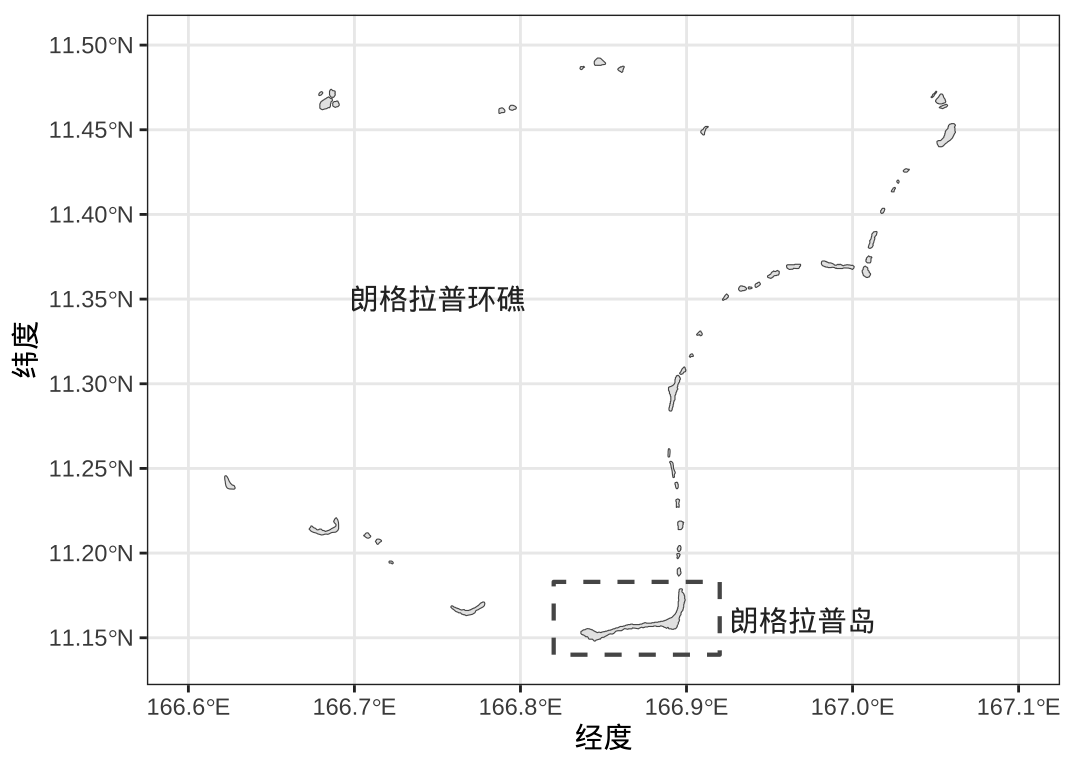
图 1.1: 朗格拉普环礁和朗格拉普岛
Ole F. Christensen 和 Paulo J. Ribeiro Jr 将 rongelap 数据集存放在 geoRglm[1] 包内,后来,geoRglm 不维护,已从 CRAN 移除了,笔者从他们主页下载了数据。数据集 rongelap 记录了 157 个测量点的伽马射线强度,即在时间间隔 time (秒)内放射的粒子数目 counts(个),测量点的横纵坐标分别为 cX (米)和 cY(米),下表展示部分朗格拉普岛核辐射检测数据及海岸线坐标数据。
| cX 横坐标 | cY 纵坐标 | counts 数目 | time 时间 |
|---|---|---|---|
| -6050 | -3270 | 75 | 300 |
| -6050 | -3165 | 371 | 300 |
| -5925 | -3320 | 1931 | 300 |
| -5925 | -3165 | 4357 | 300 |
| -5800 | -3350 | 2114 | 300 |
| -5800 | -3165 | 2318 | 300 |
| cX 横坐标 | cY 纵坐标 |
|---|---|
| -5509 | -3577 |
| -5545 | -3582 |
| -5562 | -3577 |
| -5581 | -3575 |
| -5600 | -3564 |
| -5606 | -3561 |
坐标原点在岛的东北,下图 1.2 第一个子图 右上角的位置。采样点的编号见下 图1.2第二个子图,基本上按照从下(南)到上(北),从左(西)到右(东)的顺序依次测量。
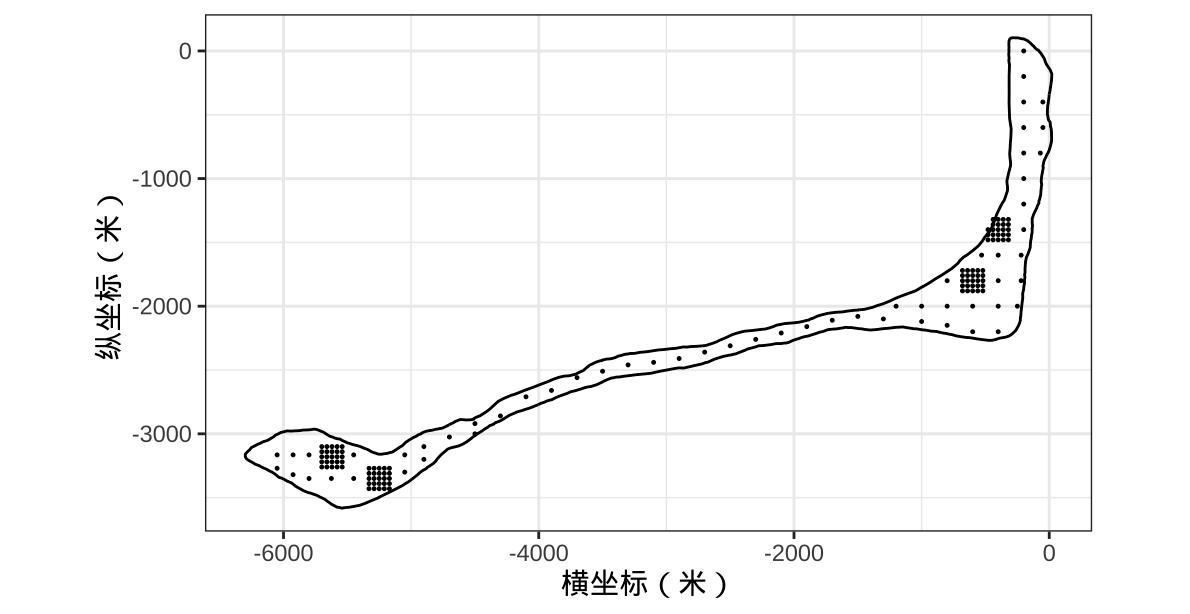
图 1.2: 采样点在岛上的分布
2 数据探索
朗格拉普岛呈月牙形,有数千米长,但仅几百米宽,十分狭长。采样点在岛上的分布如 图1.2 所示,主网格以约 200 米的间隔采样,在岛屿的东北和西南方各有两个密集采样区,每个网格采样区是 \(5 \times 5\) 方式排列的,上下左右间隔均为 40 米。朗格拉普岛上各个检测站点的核辐射强度如 图2.1 所示,越亮表示核辐射越强,四个检测区的采样阵列非常密集,通过局部放大展示了最左侧的一个检测区,它将作为后续模型比较的参照区域。
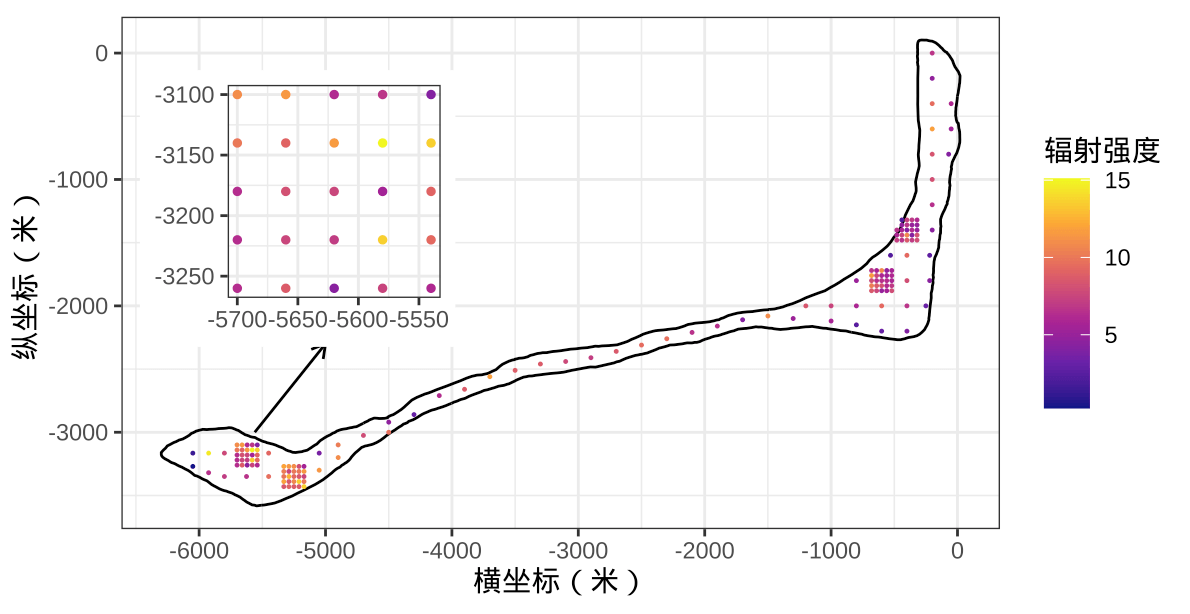
图 2.1: 岛上各采样点的核辐射强度
ggplot2 包只能在二维平面上展示数据,对于空间数据,立体图形更加符合数据产生背景。如 图2.2 所示,以三维图形展示朗格拉普岛上采样点的位置及检测到的辐射强度。lattice 包的函数 cloud() 可以绘制三维的散点图,将自定义的面板函数 panel.3dcoastline() 传递给参数 panel.3d.cloud 绘制岛屿海岸线。组合点和线两种绘图元素构造出射线,线的长短表示放射性的强弱,以射线表示粒子辐射现象更加贴切。
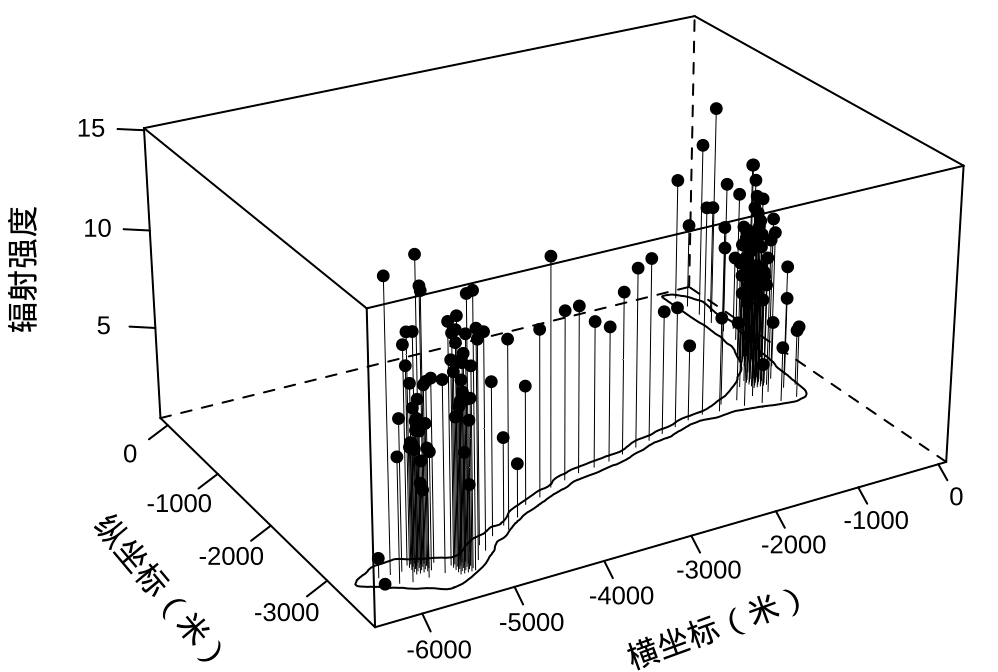
图 2.2: 岛上各采样点的辐射强度
3 数据建模
3.1 广义线性模型
核辐射是由放射元素衰变产生的,通常用单位时间释放出来的粒子数目表示辐射强度,因此,建立如下泊松型广义线性模型来拟合核辐射强度。
\[ \begin{aligned} \log(\lambda_i) &= \beta \\ y_i & \sim \mathrm{Poisson}(t_i\lambda_i) \end{aligned} \]
其中,\(\lambda_i\) 表示核辐射强度,\(\beta\) 表示未知的截距,\(y_i\) 表示观测到的粒子数目,\(t_i\) 表示相应的观测时间,\(i = 1,\ldots, 157\) 表示采样点的位置编号。R 软件内置的 stats 包有函数 glm() 可以拟合上述广义线性模型,代码如下。
fit_rongelap_poisson <- glm(counts ~ 1,
family = poisson(link = "log"), offset = log(time), data = rongelap
)
summary(fit_rongelap_poisson)##
## Call:
## glm(formula = counts ~ 1, family = poisson(link = "log"), data = rongelap,
## offset = log(time))
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.01395 0.00145 1385 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 61567 on 156 degrees of freedom
## Residual deviance: 61567 on 156 degrees of freedom
## AIC: 63089
##
## Number of Fisher Scoring iterations: 4当 family = poisson(link = "log") 时,响应变量只能是正整数,所以不能放 counts / time。泊松广义线性模型是对辐射强度建模,辐射强度与位置 cX 和 cY 有关。当响应变量为放射出来的粒子数目 counts 时,为了表示辐射强度,需要设置参数 offset,表示与放射粒子数目对应的时间间隔 time。联系函数是对数函数,因此时间间隔需要取对数。
从辐射强度的拟合残差的空间分布 图3.1 不难看出,颜色深和颜色浅的点分别聚集在一起,且与周围点的颜色呈现层次变化,拟合残差存在明显的空间相关性。如果将位置变量 cX 和 cY 加入广义线性模型,也会达到统计意义上的显著。
rongelap$poisson_residuals <- residuals(fit_rongelap_poisson)
ggplot(rongelap, aes(x = cX, y = cY)) +
geom_point(aes(colour = poisson_residuals / time), size = 0.2) +
scale_color_viridis_c(option = "C") +
theme_bw() +
labs(x = "横坐标(米)", y = "纵坐标(米)", color = "残差")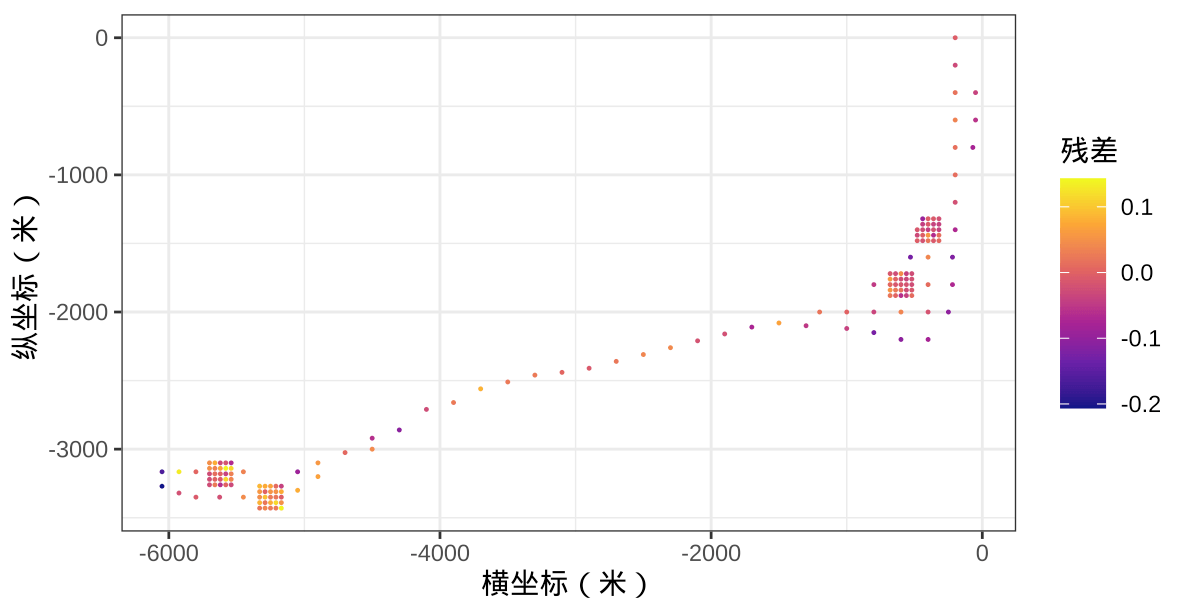
图 3.1: 残差的空间分布
从另外一个角度来思考,通过观察辐射强度的直方图,发现其分布形式与正态分布相似。实际上,辐射强度为非负值,所以应与特定参数下的伽马分布相似。
ggplot(data = rongelap, aes(x = counts / time)) +
geom_histogram(fill = "orange", color = "white", binwidth = 0.5) +
theme_bw() +
labs(x = "辐射强度", y = "频数")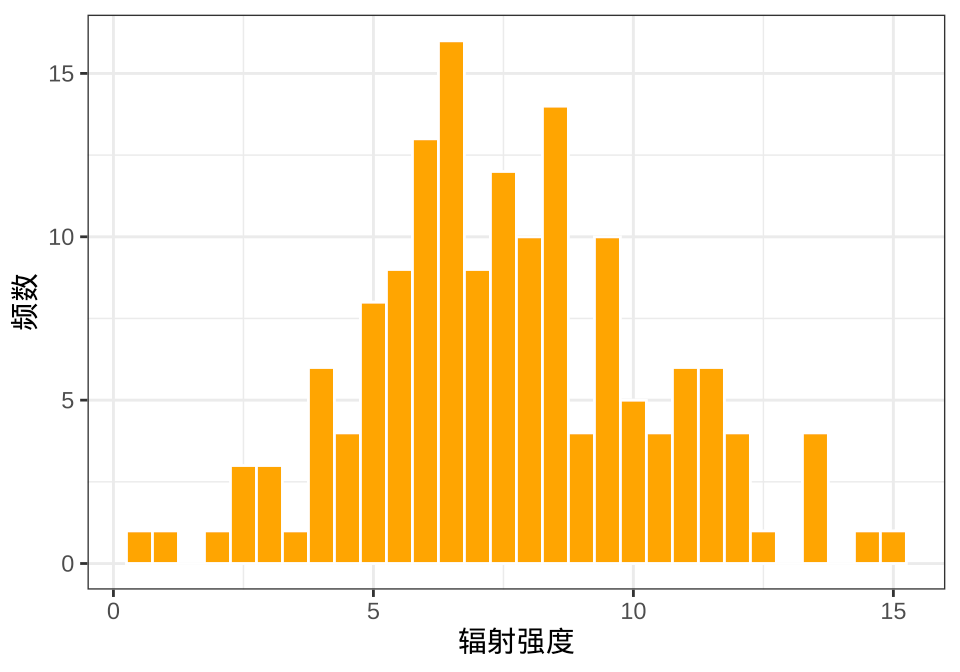
图 3.2: 辐射强度的直方图
形状参数为 \(\alpha\) 和尺度参数为 \(\sigma\) 的伽马分布的概率密度函数 \(f(x;\alpha, \sigma)\) 如下:
\[ f(x;\alpha,\sigma) = \frac{1}{\sigma^\alpha \Gamma(\alpha)}x^{\alpha - 1} \exp(- \frac{x}{\sigma}), \quad \alpha \geq 0, \sigma > 0 \]
其中,\(\Gamma(\cdot)\) 表示伽马函数,下 图3.3 展示两个伽马分布的概率密度函数,形状参数分别为 5 和 9,尺度参数均为 1,即伽马分布 \(f(x; 5, 1)\) 和 \(f(x; 9, 1)\) 。
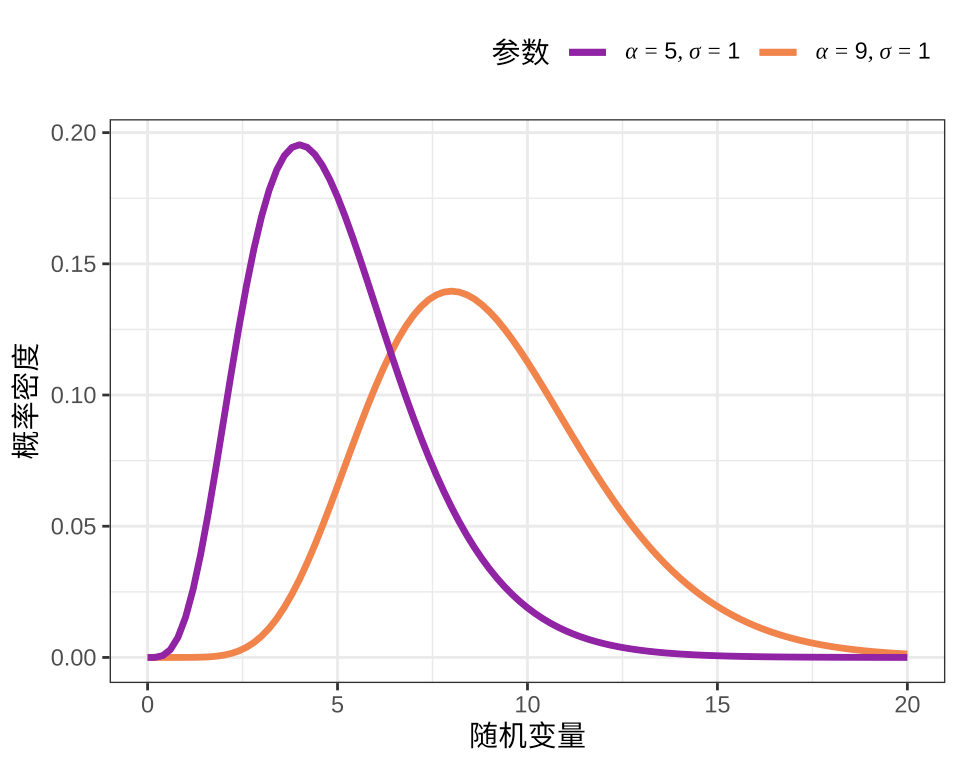
图 3.3: 伽马分布的概率密度函数
所以,可以使用响应变量服从伽马分布的广义线性模型来拟合数据。
fit_rongelap_gamma <- glm(counts / time ~ 1,
family = Gamma(link = "log"), data = rongelap
)
summary(fit_rongelap_gamma)##
## Call:
## glm(formula = counts/time ~ 1, family = Gamma(link = "log"),
## data = rongelap)
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.0286 0.0287 70.6 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for Gamma family taken to be 0.1297)
##
## Null deviance: 26.932 on 156 degrees of freedom
## Residual deviance: 26.932 on 156 degrees of freedom
## AIC: 787.3
##
## Number of Fisher Scoring iterations: 4对于计数数据,除了泊松分布,还可以用负二项分布来拟合数据。
library(MASS)
fit_rongelap_negbin <- glm.nb(
formula = counts ~ 1 + offset(log(time)),
data = rongelap, link = log
)
summary(fit_rongelap_negbin)##
## Call:
## glm.nb(formula = counts ~ 1 + offset(log(time)), data = rongelap,
## link = log, init.theta = 6.033764551)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.0286 0.0325 62.4 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for Negative Binomial(6.034) family taken to be 1)
##
## Null deviance: 161.66 on 156 degrees of freedom
## Residual deviance: 161.66 on 156 degrees of freedom
## AIC: 2639
##
## Number of Fisher Scoring iterations: 1
##
##
## Theta: 6.034
## Std. Err.: 0.666
##
## 2 x log-likelihood: -2635.054泊松分布、伽马分布和负二项分布的对数似然函数值如下:
logLik(fit_rongelap_poisson)## 'log Lik.' -31543 (df=1)logLik(fit_rongelap_gamma)## 'log Lik.' -391.7 (df=2)logLik(fit_rongelap_negbin)## 'log Lik.' -1318 (df=2)三个广义线性模型的 AIC 统计量如下:
AIC(fit_rongelap_poisson)## [1] 63089AIC(fit_rongelap_gamma)## [1] 787.3AIC(fit_rongelap_negbin)## [1] 2639负二项广义线性模型拟合效果好于泊松广义线性,伽马广义线性模型响应变量与之不同,无法与之比较,将作为后续模型比较的基础模型。
3.2 广义线性混合效应模型
图3.4 描述残差的分布,从第一个子图发现残差存在一定的线性趋势,岛屿的东南方,残差基本为正,而在岛屿的西北方,残差基本为负,说明有一定的异方差性。从第二子图发现残差在水平方向上的分布像个哑铃,说明异方差现象明显。从第三个子图发现残差在垂直方向上的分布像棵松树,也说明异方差现象明显。
ggplot(rongelap, aes(x = 1:157, y = poisson_residuals / time)) +
geom_point(size = 1) +
theme_bw() +
labs(x = "编号", y = "残差")
ggplot(rongelap, aes(x = cX, y = poisson_residuals / time)) +
geom_point(size = 1) +
theme_bw() +
labs(x = "横坐标", y = "残差")
ggplot(rongelap, aes(x = cY, y = poisson_residuals / time)) +
geom_point(size = 1) +
theme_bw() +
labs(x = "纵坐标", y = "残差")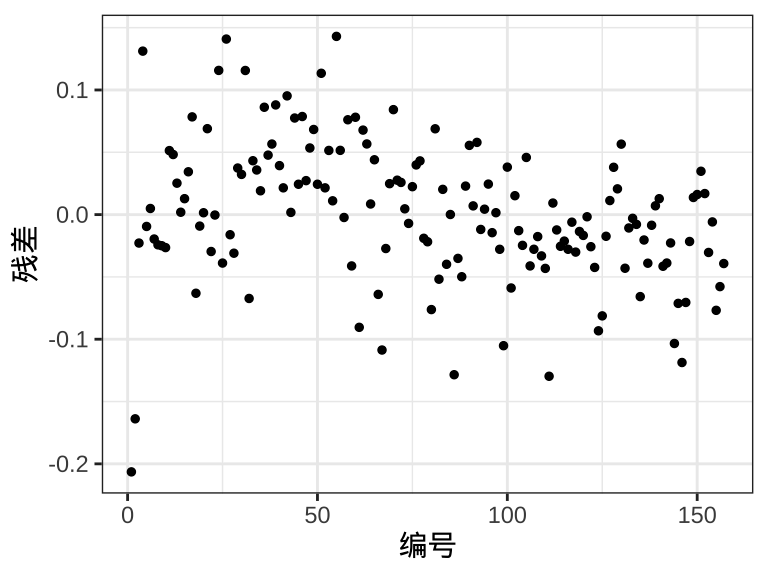
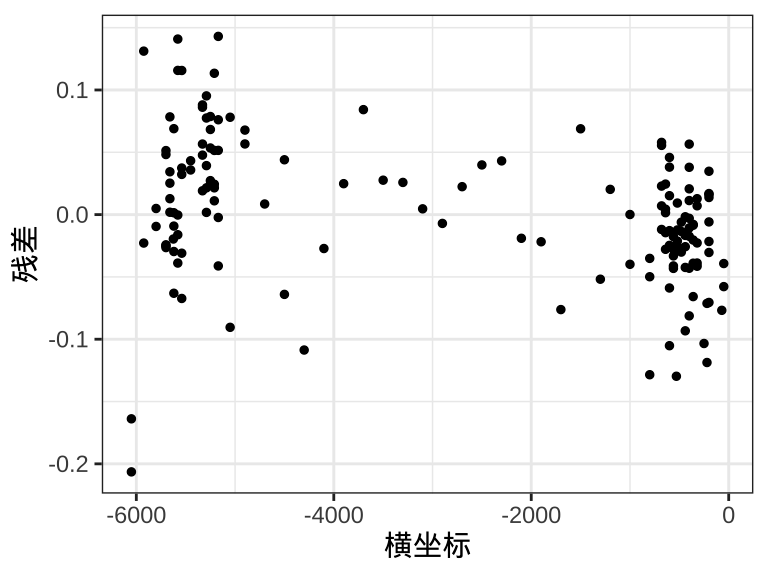
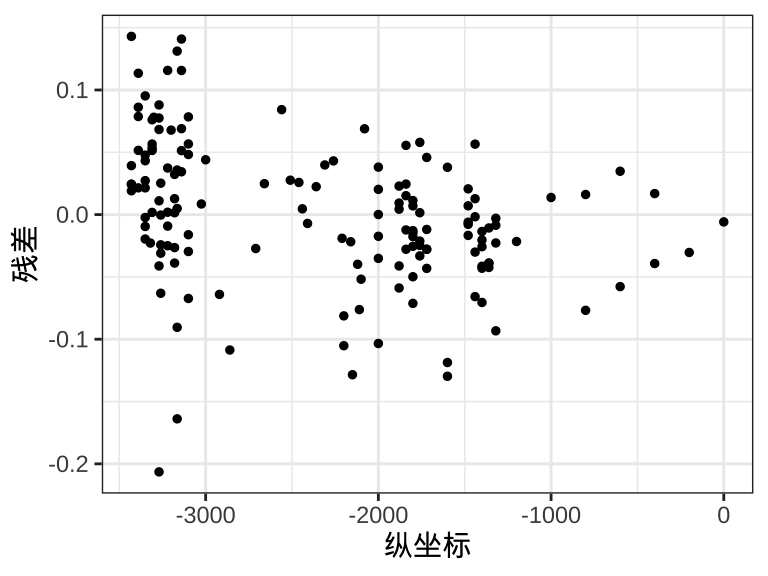
图 3.4: 残差分布图
既然异方差比较严重,给每个位置分配一个独立的方差是合理的,相当于添加一个随机效应。简单起见,假定异方差是相互独立的。
\[ \begin{aligned} \log(\lambda_i) &= \beta + Z_i \\ y_i & \sim \mathrm{Poisson}(t_i\lambda_i) \end{aligned} \]
其中,\(Z_i\) 相互独立同正态分布 \(\mathcal{N}(0,\tau^2)\) 。与之前类似,下面考虑响应变量为泊松分布、伽马分布和负二项分布的情况,采用 spaMM 包分别拟合上述模型。
library(spaMM)
fit_glmm_poisson <- fitme(
formula = counts ~ 1 + (1 | dummy) + offset(log(time)),
data = rongelap, family = poisson(link = "log")
)
summary(fit_glmm_poisson)## formula: counts ~ 1 + (1 | dummy) + offset(log(time))
## Estimation of lambda by ML (p_v approximation of logL).
## Estimation of fixed effects by ML (p_v approximation of logL).
## family: poisson( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 1.944 0.03767 51.61
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## dummy : 0.2223
## --- Coefficients for log(lambda):
## Group Term Estimate Cond.SE
## dummy (Intercept) -1.504 0.1131
## # of obs: 157; # of groups: dummy, 157
## ------------- Likelihood values -------------
## logLik
## logL (p_v(h)): -1337fit_glmm_gamma <- fitme(
formula = counts / time ~ 1 + (1 | dummy),
data = rongelap, family = Gamma(link = "log")
)
summary(fit_glmm_gamma)## formula: counts/time ~ 1 + (1 | dummy)
## Estimation of lambda and phi by ML (P_v approximation of logL).
## Estimation of fixed effects by ML (P_v approximation of logL).
## family: Gamma( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 2.029 0.03261 62.22
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## dummy : 3.369e-06
## --- Coefficients for log(lambda):
## Group Term Estimate Cond.SE
## dummy (Intercept) -12.6 22.07
## # of obs: 157; # of groups: dummy, 157
## --- Residual variation ( var = phi * mu^2 ) --
## Coefficients for log(phi) ~ 1 :
## Estimate Cond. SE
## (Intercept) -1.79 0.1113
## Estimate of phi: 0.1669
## ------------- Likelihood values -------------
## logLik
## logL (P_v(h)): -391.6fit_glmm_negbin2 <- fitme(
formula = counts ~ 1 + (1 | dummy) + offset(log(time)),
data = rongelap, family = negbin2(link = "log")
)
summary(fit_glmm_negbin2)## formula: counts ~ 1 + (1 | dummy) + offset(log(time))
## Estimation of fixed effects by ML (P_v approximation of logL).
## Estimation of lambda and NB_shape by 'outer' ML, maximizing logL.
## family: negbin2(shape=6.035)( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 2.029 0.03253 62.35
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## dummy : 6.385e-05
## # of obs: 157; # of groups: dummy, 157
## ------------- Likelihood values -------------
## logLik
## logL (P_v(h)): -1318截距项 (Intercept) 的点估计和区间估计分别如下:
# 点估计
fixef(fit_glmm_poisson)## (Intercept)
## 1.944fixef(fit_glmm_gamma)## (Intercept)
## 2.029fixef(fit_glmm_negbin2)## (Intercept)
## 2.029# 区间估计
confint(fit_glmm_poisson, parm = "(Intercept)")## lower (Intercept) upper (Intercept)
## 1.870 2.018confint(fit_glmm_gamma, parm = "(Intercept)")## lower (Intercept) upper (Intercept)
## 1.965 2.094confint(fit_glmm_negbin2, parm = "(Intercept)")## lower (Intercept) upper (Intercept)
## 1.965 2.094随机效应的方差 \(\tau^2\) 的点估计如下:
get_ranPars(fit_glmm_poisson)$lambda[[1]]## [1] 0.2223get_ranPars(fit_glmm_gamma)$lambda[[1]]## [1] 3.369e-06get_ranPars(fit_glmm_negbin2)$lambda[[1]]## [1] 6.385e-05对数似然函数值的计算如下:
logLik(fit_glmm_poisson)## p_v
## -1337logLik(fit_glmm_gamma)## P_v
## -391.6logLik(fit_glmm_negbin2)## P_v
## -1318对伽马分布和负二项分布,从广义线性模型到广义线性混合效应模型 ,提升可以忽略不计。而对泊松分布,提升十分明显。无论是广义线性模型还是广义线性混合效应模型,负二项分布比泊松分布的效果都好。
3.3 空间线性混合效应模型
从实际场景出发,也不难理解,位置信息是非常关键的。进一步,充分利用位置信息,精细建模是很有必要的。相邻位置的核辐射强度是相关的,离得近的比离得远的更相关。下面对辐射强度建模,假定随机效应之间存在相关性结构,去掉随机效应相互独立的假设,这更符合位置效应存在相互影响的实际情况。
\[ \log\big(\lambda(x_i)\big) = \beta + S(x_{i}) + Z_{i} \tag{3.1} \]
其中,\(\beta\) 表示截距,相当于平均水平,\(\lambda(x_i)\) 表示位置 \(x_i\) 处的辐射强度,\(S(x_{i})\) 表示位置 \(x_i\) 处的空间效应,\(S(x),x \in \mathcal{D} \subset{\mathbb{R}^2}\) 是二维平稳空间高斯过程 \(\mathcal{S}\) 的具体实现。 \(\mathcal{D}\) 表示研究区域,可以理解为朗格拉普岛,它是二维实平面 \(\mathbb{R}^2\) 的子集。 \(Z_i\) 之间相互独立同正态分布 \(\mathcal{N}(0,\tau^2)\) ,\(Z_i\) 表示非空间的随机效应,在空间统计中,常称之为块金效应,可以理解为测量误差、空间变差或背景辐射。值得注意,此时,块金效应和模型残差是合并在一起的。
3.3.1 自协方差函数
随机过程 \(S(x)\) 的自协方差函数常用的有指数型、幂二次指数型(高斯型)和梅隆型,形式如下:
\[ \begin{aligned} \mathsf{Cov}( S(x_i), S(x_j) ) &= \sigma^2 \exp\big( -\frac{\|x_i -x_j\|_{2}}{\phi} \big) \\ \mathsf{Cov}( S(x_i), S(x_j) ) &= \sigma^2 \exp\big( -\frac{\|x_i -x_j\|_{2}^{2}}{2\phi^2} \big) \\ \mathsf{Cov}( S(x_i), S(x_j) ) &= \sigma^2 \frac{2^{1 - \nu}}{\Gamma(\nu)} \left(\sqrt{2\nu}\frac{\|x_i -x_j\|_{2}}{\phi}\right)^{\nu} K_{\nu}\left(\sqrt{2\nu}\frac{\|x_i -x_j\|_{2}}{\phi}\right) \\ K_{\nu}(x) &= \int_{0}^{\infty}\exp(-x \cosh t) \cosh (\nu t) \mathrm{dt} \end{aligned} \tag{3.2} \]
其中,\(K_{\nu}\) 表示阶数为 \(\nu\) 的修正的第二类贝塞尔函数,\(\Gamma(\cdot)\) 表示伽马函数,当 \(\nu = 1/2\) ,梅隆型将简化为指数型,当 \(\nu = \infty\) 时,梅隆型将简化为幂二次指数型。固定 \(\sigma = 1\),自协方差函数图像如图 3.5 所示,不难看出,\(\nu\) 影响自协方差函数的平滑性,控制点与点之间相关性的变化,\(\nu\) 越大相关性越迅速地递减。\(\phi\) 控制自协方差函数的范围,\(\phi\) 越大相关性辐射距离越远。对模型来说,它们都是超参数。
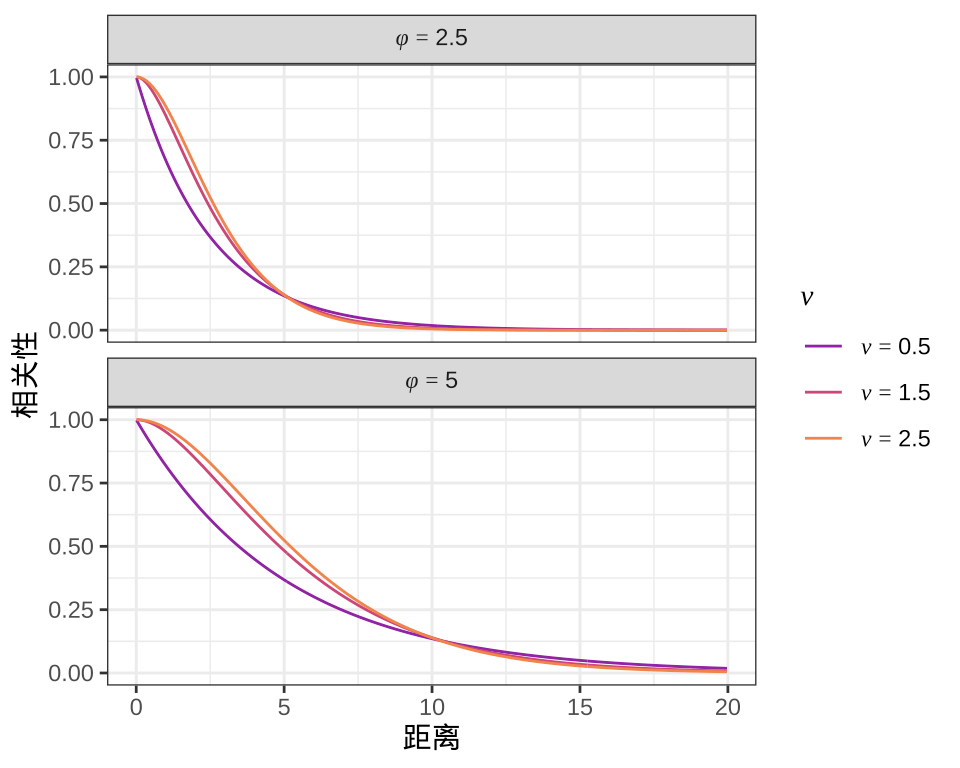
图 3.5: 梅隆型自协方差函数曲线
3.3.2 nlme 包的自相关函数
nlme 包中带块金效应的指数型自相关函数设定如下:
\[ \rho(u; \phi, \tau_{rel}^2 ) = \tau_{rel}^2 + (1 - \tau_{rel}^2) \big(1 - \exp(- \frac{u}{\phi}) \big) \]
为了方便参数估计,nlme 包对参数做了一些重参数化的操作。
\[ \begin{aligned} \tau_{rel}^2 &= \frac{\tau^2}{\tau^2 + \sigma^2} \\ \sigma_{tol}^2 &= \tau^2 + \sigma^2 \end{aligned} \tag{3.3} \]
当 \(u\) 趋于 0 时, \(\rho(u; \phi, \tau_{rel}^2 ) = \tau_{rel}^2\) 。另外,\(\phi\) 取值为正,\(\tau_{rel}^2\) 取值介于 0-1 之间,在默认设置下,\(\phi\) 的初始值为 \(0.1 \times \max_{i,j \in A} u_{ij}\),即所有点之间距离的最大值的 10%, \(\tau_{rel}^2\) 为 0.1 ,这只是作为参考,用户可根据实际情况调整。
下面以一个简单示例理解自相关函数 corExp() 的作用,令 \(\phi = 1.2, \tau_{rel}^2 = 0.2\),则由距离矩阵和自相关函数构造的自相关矩阵如下:
library(nlme)
spatDat <- data.frame(x = (1:4) / 4, y = (1:4) / 4)
cs3Exp <- corExp(c(1.2, 0.2), form = ~ x + y, nugget = TRUE)
cs3Exp <- Initialize(cs3Exp, spatDat)
corMatrix(cs3Exp)## [,1] [,2] [,3] [,4]
## [1,] 1.0000 0.5958 0.4438 0.3305
## [2,] 0.5958 1.0000 0.5958 0.4438
## [3,] 0.4438 0.5958 1.0000 0.5958
## [4,] 0.3305 0.4438 0.5958 1.0000自相关矩阵的初始化结果等价于如下矩阵:
diag(0.2, 4) + (1 - 0.2) * exp(-as.matrix(dist(spatDat)) / 1.2)## 1 2 3 4
## 1 1.0000 0.5958 0.4438 0.3305
## 2 0.5958 1.0000 0.5958 0.4438
## 3 0.4438 0.5958 1.0000 0.5958
## 4 0.3305 0.4438 0.5958 1.0000除了函数 corExp() ,nlme 包还有好些自相关函数,如高斯自相关函数 corGaus() ,线性自相关函数 corLin() ,有理自相关函数 corRatio() ,球型自相关函数 corSpher() 等。它们的作用与函数 corExp() 类似,使用方式也一样,如下是高斯型自相关函数的示例,其他的不再一一举例。
cs3Gaus <- corGaus(c(1.2, 0.2), form = ~ x + y, nugget = TRUE)
cs3Gaus <- Initialize(cs3Gaus, spatDat)
corMatrix(cs3Gaus)## [,1] [,2] [,3] [,4]
## [1,] 1.0000 0.7335 0.5653 0.3663
## [2,] 0.7335 1.0000 0.7335 0.5653
## [3,] 0.5653 0.7335 1.0000 0.7335
## [4,] 0.3663 0.5653 0.7335 1.0000# 等价于
diag(0.2, 4) + (1 - 0.2) * exp(-as.matrix(dist(spatDat))^2 / 1.2^2)## 1 2 3 4
## 1 1.0000 0.7335 0.5653 0.3663
## 2 0.7335 1.0000 0.7335 0.5653
## 3 0.5653 0.7335 1.0000 0.7335
## 4 0.3663 0.5653 0.7335 1.00003.3.3 nlme 包的拟合函数 gls()
nlme 包的函数 gls() 实现限制极大似然估计方法,可以拟合存在异方差的一般线性模型。所谓一般线性模型,即在简单线性模型的基础上,残差不再是独立同分布的,而是存在相关性。函数 gls() 可以拟合具有空间自相关性的残差结构。这种线性模型又可以看作是一种带空间自相关结构的线性混合效应模型,空间随机效应的结构可以看作异方差的结构。
fit_rongelap_gls <- gls(
log(counts / time) ~ 1, data = rongelap,
correlation = corExp(
value = c(200, 0.1), form = ~ cX + cY, nugget = TRUE
)
)
summary(fit_rongelap_gls)## Generalized least squares fit by REML
## Model: log(counts/time) ~ 1
## Data: rongelap
## AIC BIC logLik
## 184.4 196.6 -88.22
##
## Correlation Structure: Exponential spatial correlation
## Formula: ~cX + cY
## Parameter estimate(s):
## range nugget
## 169.7472 0.1092
##
## Coefficients:
## Value Std.Error t-value p-value
## (Intercept) 1.813 0.1088 16.66 0
##
## Standardized residuals:
## Min Q1 Med Q3 Max
## -5.57385 -0.06909 0.34610 0.73852 1.57152
##
## Residual standard error: 0.574
## Degrees of freedom: 157 total; 156 residualnlme 包给出截距项 \(\beta\) 、相对块金效应 \(\tau_{rel}^2\) 、范围参数 \(\phi\) 和残差标准差 \(\sigma_{tol}\) 的估计,
\[ \begin{aligned} \beta &= 1.812914, \quad \phi = 169.7472088 \\ \tau_{rel}^2 &= 0.1092496, \quad \sigma_{tol} = 0.5739672 \end{aligned} \]
根据前面的 (3.3) ,可以得到 \(\tau^2\) 和 \(\sigma^2\) 的估计。
\[ \begin{aligned} \tau^2 &= \tau^2_{rel} \times \sigma^2_{tol} = 0.1092496 \times 0.3294383 = 0.035991 \\ \sigma^2 &= \sigma^2_{tol} - \tau^2_{rel} \times \sigma^2_{tol} = 0.5739672^2 - 0.1092496 \times 0.3294383 = 0.2934473 \end{aligned} \]
nlme 包的另一个函数 lme() ,扩展了函数 gls() 的功能,支持添加额外的随机效应。下面在模型 (3.1) 的基础上添加一个变化的截距项,所有的采样位置归为一组,相当于添加一个随机项 \(\xi\) ,一般假定它服从均值为 0 方差为 \(\delta^2\) 的正态分布。这样下来,模型包含三块随机项,与空间位置关联的空间随机效应 \(S(x)\) ,与空间位置无关的块金效应 \(Z_i\),与分组变量 group 关联的随机效应 \(\xi\) 。
rongelap$group <- 1
fit_rongelap_lme <- lme(
log(counts / time) ~ 1, data = rongelap,
random = ~ 1 | group,
correlation = corExp(
value = c(200, 0.1), form = ~ cX + cY, nugget = TRUE
)
)
summary(fit_rongelap_lme)## Linear mixed-effects model fit by REML
## Data: rongelap
## AIC BIC logLik
## 186.4 201.7 -88.22
##
## Random effects:
## Formula: ~1 | group
## (Intercept) Residual
## StdDev: 0.1222 0.574
##
## Correlation Structure: Exponential spatial correlation
## Formula: ~cX + cY | group
## Parameter estimate(s):
## range nugget
## 169.7472 0.1092
## Fixed effects: log(counts/time) ~ 1
## Value Std.Error DF t-value p-value
## (Intercept) 1.813 0.1636 156 11.08 0
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -5.57385 -0.06909 0.34610 0.73852 1.57152
##
## Number of Observations: 157
## Number of Groups: 13.3.4 经验半变差函数图
接下来用经验半变差函数图检查空间相关性。为方便表述起见,令 \(T(x_i)\) 代表 (3.1) 等号右侧的部分,即表示线性预测(Linear Predictor)。
\[ T(x_i) = \beta + S(x_{i}) + Z_{i} \]
令 \(\gamma(u_{ij}) = \frac{1}{2}\mathsf{Var}\{T(x_i) - T(x_j)\}\) 表示半变差函数(Semivariogram),这里 \(u_{ij}\) 表示采样点 \(x_i\) 与 \(x_j\) 之间的距离。考虑到
\[ \gamma(u_{ij}) = \frac{1}{2}\mathsf{E}\big\{\big[T(x_i) - T(x_j)\big]^2\big\} = \tau^2 + \sigma^2\big(1-\rho(u_{ij})\big) \tag{3.4} \]
上式第一个等号右侧期望可以用样本代入来计算,称之为经验半变差函数,第二个等号右侧为理论半变差函数。为了便于计算,将距离做一定划分,尽量使得各个距离区间的样本点对的数目接近。此时,第 \(i\) 个距离区间上经验半变差函数值 \(\hat{\gamma}(h_i)\) 的计算公式如下:
\[ \hat{\gamma}(h_i) = \frac{1}{2N(h_i)}\sum_{j=1}^{N(h_i)}(T(x_i)-T(x_i+h'))^2, \ \ h_{i,0} \le h' < h_{i,1} \]
其中,\([h_{i,0},h_{i,1}]\) 表示第 \(i\) 个距离区间,\(N(h_i)\) 表示第 \(i\) 个距离区间内所有样本点对的数目,只要两个点之间的距离在这个区间内,就算是一对。rongelap 数据集包含 157 个采样点,两两配对,共有 \((157 - 1) \times 157 / 2 = 12246\) 对。
下面举个例子说明函数 Variogram() 的作用。假设模型参数已经估计出来了,为 \(\phi = 200, \tau_{rel}^2 = 0.1\) 。当距离为 40 时,半变差函数值为 0.2631423 。
0.1 + (1 - 0.1) * (1 - exp(- 40 / 200 ) )## [1] 0.2631将 rongelap 数据代入函数 Variogram() 计算半变差函数值。
cs <- corExp(value = c(200, 0.1), form = ~ cX + cY, nugget = TRUE)
cs <- Initialize(cs, rongelap)
comp_vario <- Variogram(cs)
head(comp_vario)## variog dist
## 1 0.2631 40.0
## 2 0.6266 176.0
## 3 0.8108 311.9
## 4 0.9041 447.9
## 5 0.9514 583.8
## 6 0.9754 719.8可以看到,当距离为 40 时,计算的结果与上面是一致的,也知道了函数 Variogram() 的作用。
模型的参数是 nlme 包的函数 gls() 估计出来的,返回一个 gls 类型的拟合对象。函数 Variogram() 是一个泛型函数,对于 gls 类型的对象,会自动调用相应的方法计算经验半变差函数值:
fit_rongelap_vario <- Variogram(fit_rongelap_gls,
form = ~ cX + cY, data = rongelap, resType = "response"
)
fit_rongelap_vario## variog dist n.pairs
## 1 0.07007 89.44 510
## 2 0.12720 144.22 601
## 3 0.17289 252.98 581
## 4 0.22385 368.78 622
## 5 0.26006 443.85 592
## 6 0.20694 521.54 616
## 7 0.41862 718.05 611
## 8 0.30181 1028.20 610
## 9 0.16718 1493.74 612
## 10 0.14684 2150.08 612
## 11 0.15149 2993.10 612
## 12 0.21048 3896.79 613
## 13 0.21373 4600.21 618
## 14 0.17302 4889.68 607
## 15 0.20205 5065.98 618
## 16 0.18620 5195.77 623
## 17 0.18614 5294.00 596
## 18 0.20561 5451.83 616
## 19 0.46457 5604.42 608
## 20 0.55063 5979.96 612为什么 fit_rongelap_vario 输出的 n.pairs 的总数是 12090?
结果显示,距离在 0-89.44272 米之间的坐标点有 510 对,经验半变差函数值为 0.07006716。距离在 89.44272-144.22205 米之间的坐标点有 601 对,经验半变差函数值为 0.12719889,依此类推。将距离和计算的经验半变差函数值绘制出来,即得到经验半变差图,如图3.6所示。刚开始,半变差值很小,之后随距离增加而增大,一直到达一个平台。半变差反比于空间相关性的程度,随着距离增加,空间相关性减弱。这说明数据中确含有空间相关性,模型中添加指数型自相关空间结构是合理的。
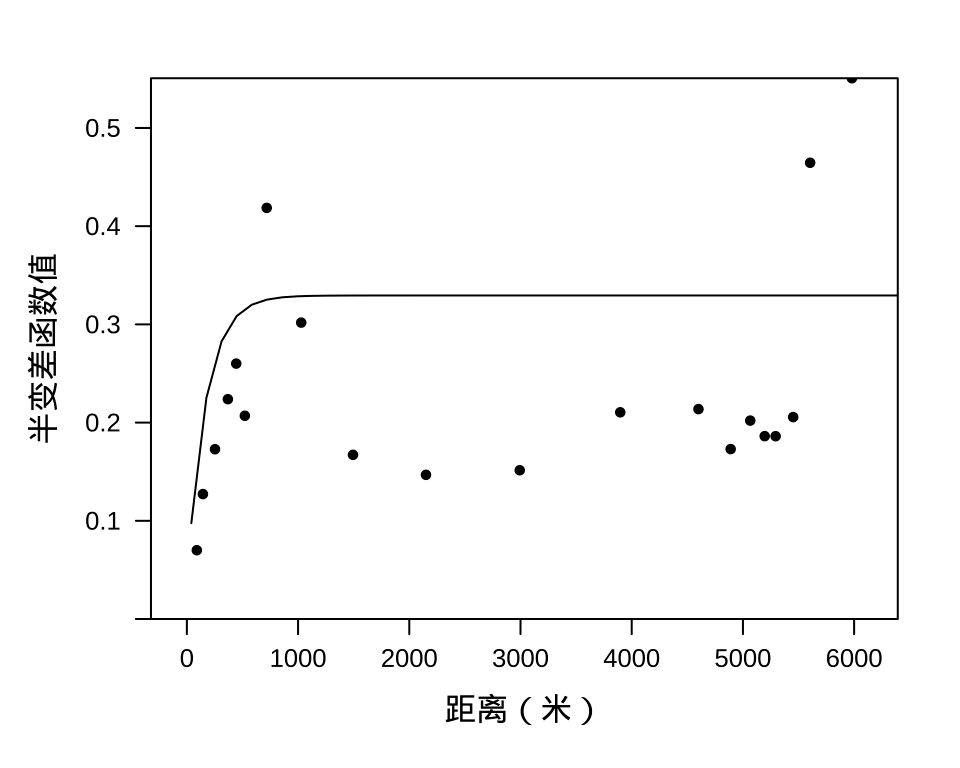
图 3.6: 残差的经验半变差图
如果空间相关性提取得很充分,则标准化残差的半变差图中的数据点应是围绕标准差 1 上下波动,无明显趋势,拟合线几乎是一条水平线,从 图3.7 来看,存在一些非均匀的波动,是采样点在空间的分布不均匀所致,岛屿狭长的中部地带采样点稀疏。如前所述,刻画空间相关性,除了指数型,还可以用其它自相关结构来拟合,留待读者练习。
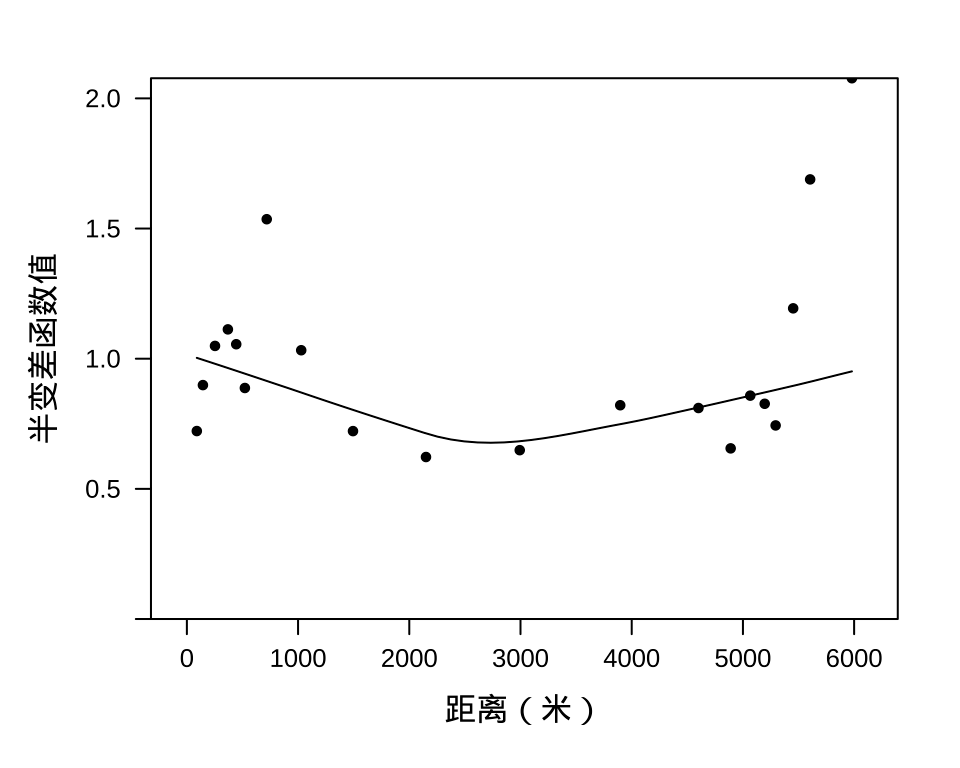
图 3.7: 标准化残差的经验半变差图
3.4 空间广义线性混合效应模型
简单的广义线性模型并没有考虑距离相关性,它认为各个观测点的数据是相互独立的。因此,考虑采用广义线性混合效应模型,在广义线性模型的基础上添加位置相关的随机效应,用以刻画未能直接观测到的潜在影响。 \({}^{137}\mathrm{Cs}\) 放出伽马射线,在 \(n=157\) 个采样点,分别以时间间隔 \(t_i\) 测量辐射量 \(y(x_i)\),建立泊松型空间广义线性混合效应模型。
\[ \begin{aligned} \log\{\lambda(x_i)\} & = \beta + S(x_{i}) + Z_{i} \\ y(x_{i}) &\sim \mathrm{Poisson}(t_i\lambda(x_i)) \end{aligned} \tag{3.5} \]
模型中,放射粒子数 \(y(x_{i})\) 作为响应变量服从均值为 \(t_i\lambda(x_i)\) 的泊松分布,其它模型成分的说明同前。
nlme 包不能拟合空间广义线性混合效应模型, spaMM 包可以,它的使用语法与前面介绍的函数 glm() 、 nlme 包都类似,函数 fitme() 可以拟合从线性模型到广义线性混合效应模型的一大类模型,且使用统一的语法,输出一个 HLfit 类型的数据对象。 spaMM 包的函数 Matern() 实现了梅隆型自协方差函数,指数型和幂二次指数型是它的特例。当固定 \(\nu = 0.5\) 时,梅隆型自协方差函数 Matern() 的形式退化为 \(\sigma^2\exp(- \alpha u)\) ,其中,\(\alpha\) 与范围参数关联,相当于前面出现的 \(1/\phi\) 。
library(spaMM)
fit_rongelap_spamm <- fitme(
formula = counts ~ 1 + Matern(1 | cX + cY) + offset(log(time)),
family = poisson(link = "log"), data = rongelap,
fixed = list(nu = 0.5)
)
summary(fit_rongelap_spamm)## formula: counts ~ 1 + Matern(1 | cX + cY) + offset(log(time))
## Estimation of corrPars and lambda by ML (p_v approximation of logL).
## Estimation of fixed effects by ML (p_v approximation of logL).
## Estimation of lambda by 'outer' ML, maximizing logL.
## family: poisson( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 1.831 0.08455 21.65
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Correlation parameters:
## 1.nu 1.rho
## 0.500000 0.009683
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## cX + cY : 0.2964
## # of obs: 157; # of groups: cX + cY, 157
## ------------- Likelihood values -------------
## logLik
## logL (p_v(h)): -1318从输出结果来看,模型固定效应的截距项 \(\beta\) 为 1.831,随机效应的方差 \(\sigma^2\) 为 0.2964,对比函数 Matern() 实现的指数型自协方差函数公式与 (3.2) ,将输出结果转化一下,则 \(\phi = 1 / 0.00968 = 103.3\) ,表示在这个模型的设定下,空间相关性的最大影响距离为 103.3 米。
函数 fitme() 默认使用极大似然估计模型参数,也可以使用限制极大似然来估计。
fit_rongelap_spamm2 <- fitme(
formula = counts ~ 1 + Matern(1 | cX + cY) + offset(log(time)),
family = poisson(link = "log"), data = rongelap,
fixed = list(nu = 0.5), method = "REML"
)
summary(fit_rongelap_spamm2)## formula: counts ~ 1 + Matern(1 | cX + cY) + offset(log(time))
## Estimation of corrPars and lambda by REML (p_bv approximation of restricted logL).
## Estimation of fixed effects by ML (p_v approximation of logL).
## Estimation of lambda by 'outer' REML, maximizing restricted logL.
## family: poisson( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 1.829 0.08797 20.78
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Correlation parameters:
## 1.nu 1.rho
## 0.500000 0.009212
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## cX + cY : 0.3069
## # of obs: 157; # of groups: cX + cY, 157
## ------------- Likelihood values -------------
## logLik
## logL (p_v(h)): -1318
## Re.logL (p_b,v(h)): -1320泊松分布的均值 \(\mathsf{E}\{y(x_i)\}=\mathrm{t}_i\lambda(x_i)\) 和方差 \(\mathsf{Var}\{y(x_i)\}\) 的值是一样的。如果假定它们不同,比如方差是关于均值的二次函数,可以用负二项分布来拟合数据,一般来说效果会更加好,对数似然函数值 logL 在变大。
fit_rongelap_spamm3 <- fitme(
formula = counts ~ 1 + Matern(1 | cX + cY) + offset(log(time)),
family = negbin2(link = "log"), data = rongelap,
fixed = list(nu = 0.5)
)
summary(fit_rongelap_spamm3)## formula: counts ~ 1 + Matern(1 | cX + cY) + offset(log(time))
## Estimation of corrPars, lambda and NB_shape by ML (P_v approximation of logL).
## Estimation of fixed effects by ML (P_v approximation of logL).
## Estimation of lambda and NB_shape by 'outer' ML, maximizing logL.
## family: negbin2(shape=6.035)( link = log )
## ------------ Fixed effects (beta) ------------
## Estimate Cond. SE t-value
## (Intercept) 2.029 0.03253 62.35
## --------------- Random effects ---------------
## Family: gaussian( link = identity )
## --- Correlation parameters:
## 1.nu 1.rho
## 0.5000 0.5003
## --- Variance parameters ('lambda'):
## lambda = var(u) for u ~ Gaussian;
## cX + cY : 6.385e-05
## # of obs: 157; # of groups: cX + cY, 157
## ------------- Likelihood values -------------
## logLik
## logL (P_v(h)): -13184 模型预测
接下来,预测给定的边界(海岸线)内任意位置的核辐射强度,展示全岛的核辐射强度分布。先从点构造多边形数据,再将多边形做网格划分,继而将网格中心点作为模型输入获得核辐射强度的预测值。
4.1 海岸线数据
海岸线上取一些点,点的数量越多,对海岸线的刻画越精确,这在转弯处体现得非常明显。海岸线的数据是以成对的坐标构成,导入 R 语言中,是以数据框的形式存储,为了方便后续的操作,引入空间数据操作的 sf 包[2],将核辐射数据和海岸线数据转化为 POINT 类型的空间点数据。
library(sf)
rongelap_sf <- st_as_sf(rongelap, coords = c("cX", "cY"), dim = "XY")
rongelap_coastline_sf <- st_as_sf(rongelap_coastline, coords = c("cX", "cY"), dim = "XY")sf 包提供了大量操作空间数据的函数,比如函数 st_bbox() 计算一组空间数据的矩形边界,获得左下和右上两个点的坐标 (xmin,ymin) 和(xmax,ymax),下面还会陆续涉及其它空间数据操作。
st_bbox(rongelap_coastline_sf)## xmin ymin xmax ymax
## -6299.31 -3582.25 20.38 103.54rongelap_coastline_sf 数据集是朗格拉普岛海岸线的采样点坐标,是一个 POINT 类型的数据,为了以海岸线为边界生成规则网格,首先连接点 POINT 构造多边形 POLYGON 对象。POINT 和 POLYGON 是 sf 包内建的基础的几何类型,其它复杂的空间类型是由它们衍生而来。函数 st_geometry 提取空间点数据中的几何元素,再用函数 st_combine 将点组合起来,最后用函数 st_cast 转换成 POLYGON 多边形类型。
rongelap_coastline_sfp <- st_cast(st_combine(st_geometry(rongelap_coastline_sf)), "POLYGON")图4.1 上下两个子图分别展示空间点集和多边形。上图是原始的采样点数据,下图是以点带线,串联 POINT 数据构造 POLYGON 数据后的多边形。后续的数据操作将围绕这个多边形展开。
# 点集
library(ggplot2)
ggplot(rongelap_coastline_sf) +
geom_sf(size = 0.5) +
theme_void()
# 多边形
ggplot(rongelap_coastline_sfp) +
geom_sf(fill = "white", linewidth = 0.5) +
theme_void()

图 4.1: 朗格拉普岛海岸线的表示
4.2 边界处理
为了确保覆盖整个岛,处理好边界问题,需要一点缓冲空间,就是说在给定的边界线外围再延伸一段距离,构造一个更大的多边形,这可以用函数 st_buffer() 实现,根据海岸线构造缓冲区,得到一个 POLYGON 类型的几何数据对象。考虑到朗格拉普岛的实际大小,缓冲距离选择 50 米。
rongelap_coastline_buffer <- st_buffer(rongelap_coastline_sfp, dist = 50)缓冲区构造出来的效果如图 4.2 所示,为了便于与海岸线对比,图中将采样点、海岸线和缓冲区都展示出来了。
ggplot() +
geom_sf(data = rongelap_sf, size = 0.2) +
geom_sf(data = rongelap_coastline_sfp, fill = NA, color = "gray30") +
geom_sf(data = rongelap_coastline_buffer, fill = NA, color = "black") +
theme_void()
图 4.2: 朗格拉普岛海岸线及其缓冲区
4.3 构造网格
接下来,利用函数 st_make_grid() 根据朗格拉普岛海岸缓冲线构造网格,朗格拉普岛是狭长的,因此,网格是 \(75\times 150\) 的,意味着水平方向 75 行,垂直方向 150 列。网格的疏密程度是可以调整的,网格越密,格点越多,核辐射强度分布越精确,计算也越耗时。
# 构造带边界约束的网格
rongelap_coastline_grid <- st_make_grid(rongelap_coastline_buffer, n = c(150, 75))函数 st_make_grid() 根据 rongelap_coastline_buffer 的矩形边界网格化,效果如图 4.4 所示,依次添加了网格、海岸线和缓冲区。实际上,网格只需要覆盖朗格拉普岛即可,岛外的部分是大海,不需要覆盖,根据现有数据和模型对岛外区域预测核辐射强度也没有意义,因此,在后续的操作中,岛外的网格都要去掉。函数 st_make_grid() 除了支持方形网格划分,还支持六边形网格划分。
ggplot() +
geom_sf(data = rongelap_coastline_grid, fill = NA, color = "gray") +
geom_sf(data = rongelap_coastline_sfp, fill = NA, color = "gray30") +
geom_sf(data = rongelap_coastline_buffer, fill = NA, color = "black") +
theme_void()
图 4.3: 朗格拉普岛规则化网格操作
接下来,调用 sf 包函数 st_intersects() 将小网格落在缓冲区和岛内的筛选出来,一共 1612 个小网格,再用函数 st_centroid() 计算这些网格的中心点坐标。函数 st_intersects() 的作用是对多边形和网格取交集,包含与边界线交叉的网格,默认返回值是一个稀疏矩阵,与索引函数 [.sf (这是 sf 包扩展 [ 函数的一个例子)搭配可以非常方便地过滤出目标网格。与之相关的函数 st_crosses() 可以获得与边界线交叉的网格。
# 将 sfc 类型转化为 sf 类型
rongelap_coastline_grid <- st_as_sf(rongelap_coastline_grid)
rongelap_coastline_buffer <- st_as_sf(rongelap_coastline_buffer)
rongelap_grid <- rongelap_coastline_grid[rongelap_coastline_buffer, op = st_intersects]
# 计算网格中心点坐标
rongelap_grid_centroid <- st_centroid(rongelap_grid)过滤出来的网格如图 4.4 所示,全岛网格化后,图中将朗格拉普岛海岸线、网格都展示出来了。网格的中心点将作为新的坐标数据,后续要在这些新的坐标点上预测核辐射强度。
ggplot() +
geom_sf(data = rongelap_coastline_sfp,
fill = NA, color = "gray30", linewidth = 0.5) +
geom_sf(data = rongelap_grid, fill = NA, color = "gray30") +
theme_void()
图 4.4: 朗格拉普岛规则网格划分结果
4.4 整理数据
函数 st_coordinates() 抽取网格中心点的坐标并用函数 as.data.frame() 转化为数据框类型,新数据的列名需要和训练数据保持一致,最后补充漂移项 time,以便输入模型中。漂移项并不影响核辐射强度,指定为 300 或 400 都可以。
rongelap_grid_df <- as.data.frame(st_coordinates(rongelap_grid_centroid))
colnames(rongelap_grid_df) <- c("cX", "cY")
rongelap_grid_df$time <- 1将数据输入 spaMM 包拟合的模型对象 fit_rongelap_spamm,并将模型返回的结果整理成数据框,再与采样点数据合并。predict() 是一个泛型函数,spaMM 包为模型对象提供了相应的预测方法。
# 预测值
rongelap_grid_pred <- predict(fit_rongelap_spamm,
newdata = rongelap_grid_df, type = "response"
)
rongelap_grid_df$pred_sp <- as.vector(rongelap_grid_pred)
# 线性预测的方差
rongelap_grid_var <- get_predVar(fit_rongelap_spamm,
newdata = rongelap_grid_df, variances = list(predVar = TRUE), which = "predVar"
)## Non-identity link: predVar is on linear-predictor scale.rongelap_grid_df$var_sp <- as.vector(rongelap_grid_var)在空间线性混合效应模型一节,截距 \(\beta\) ,方差 \(\sigma^2\) ,块金效应 \(\tau^2\) 和范围参数 \(\phi\) 都估计出来了。在此基础上,采用简单克里金插值方法预测,对于未采样观测的位置 \(x_0\),它的辐射强度的预测值 \(\hat{\lambda}(x_0)\) 及其预测方差 \(\mathsf{Var}\{\hat{\lambda}(x_0)\}\) 的计算公式如下。
\[ \begin{aligned} \hat{\lambda}(x_0) &= \beta + \bm{u}^{\top}(V + \tau^2I)^{-1}(\bm{\lambda} - \bm{1}\beta) \\ \mathsf{Var}\{\hat{\lambda}(x_0)\} &= \sigma^2 - \bm{u}^{\top}(V + \tau^2I)^{-1}\bm{u} \end{aligned} \]
其中,协方差矩阵 \(V\) 中第 \(i\) 行第 \(j\) 列的元素为 \(\mathsf{Cov}\{S(x_i),S(x_j)\}\) ,列向量 \(\bm{u}\) 的第 \(i\) 个元素为 \(\mathsf{Cov}\{S(x_i),S(x_0)\}\) 。
# 截距
beta <- 1.812914
# 范围参数
phi <- 169.7472088
# 方差
sigma_sq <- 0.2934473
# 块金效应
tau_sq <- 0.035991
# 自协方差函数
cov_fun <- function(h) sigma_sq * exp(-h / phi)
# 观测距离矩阵
m_obs <- cov_fun(st_distance(x = rongelap_sf)) + diag(tau_sq, 157)
# 预测距离矩阵
m_pred <- cov_fun(st_distance(x = rongelap_sf, y = rongelap_grid_centroid))
# 简单克里金插值 Simple Kriging
mean_sk <- beta + t(m_pred) %*% solve(m_obs, log(rongelap_sf$counts / rongelap_sf$time) - beta)
# 辐射强度预测值
rongelap_grid_df$pred_sk <- exp(mean_sk)
# 辐射强度预测方差
rongelap_grid_df$var_sk <- sigma_sq - diag(t(m_pred) %*% solve(m_obs, m_pred))4.5 展示结果
将预测结果以散点图的形式呈现到图上,见下 图4.5 ,由于散点非常多,紧挨在一起就连成片了。上子图是 nlme 包预测的结果,下子图是 spaMM 包预测的结果,前者图像看起来会稍微平滑一些。
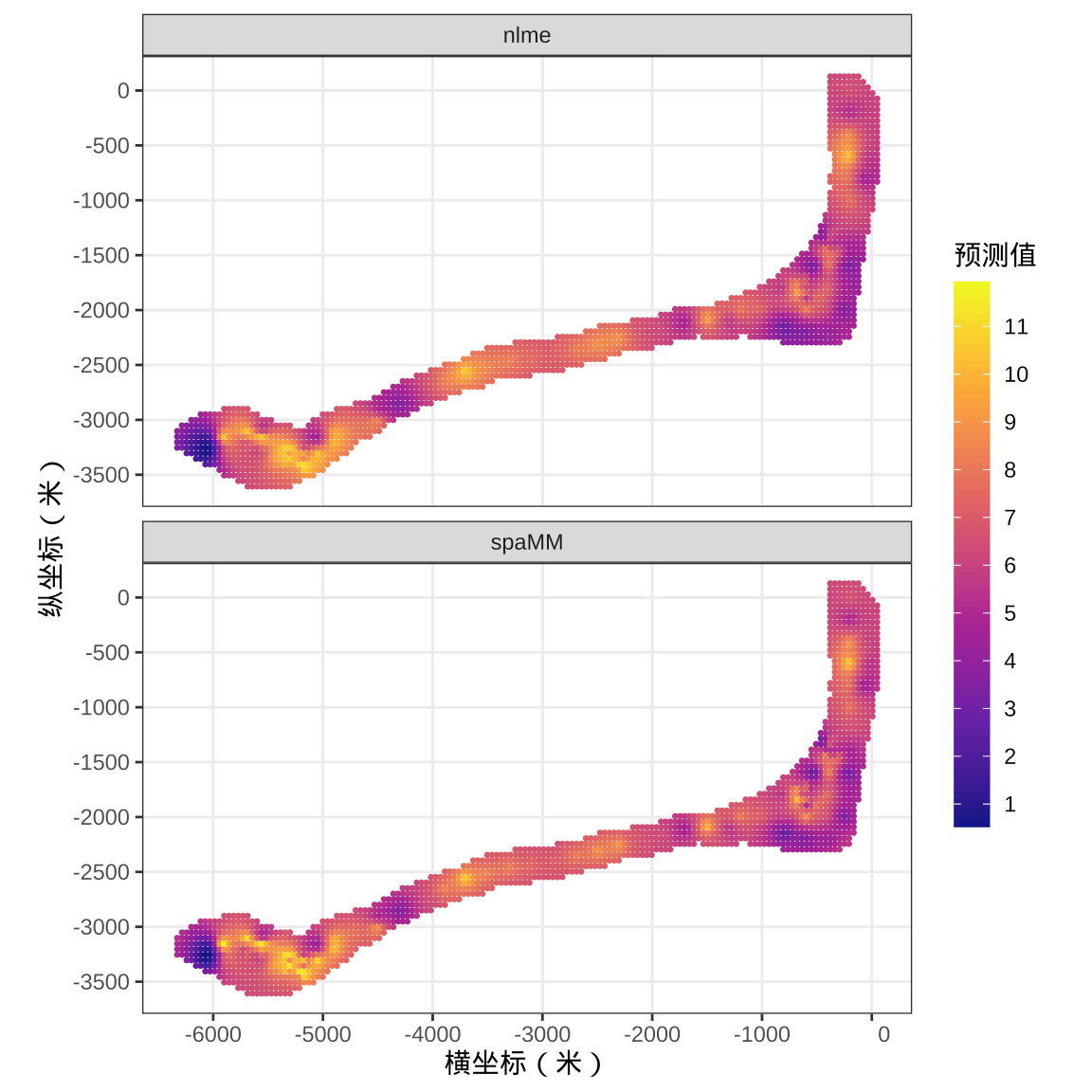
图 4.5: 朗格拉普岛核辐射强度的分布
从空间线性混合效应模型到空间广义线性混合效应模型的效果提升不多,差异不太明显。下图 4.6 展示核辐射强度预测方差的分布。越简单的模型,预测值的分布越平滑,越复杂的模型,捕捉到更多局部细节,因而,预测值的分布越曲折。
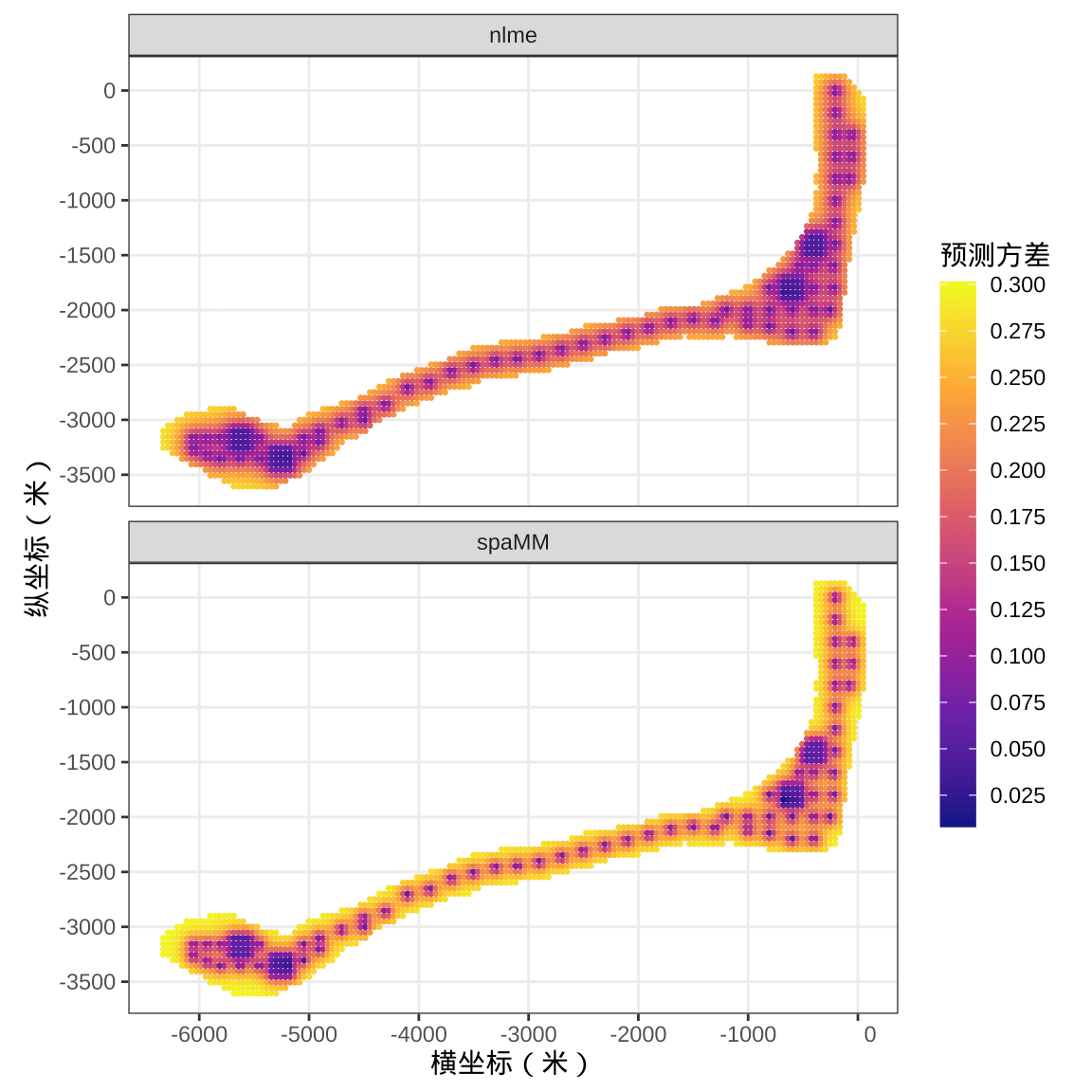
图 4.6: 核辐射强度预测方差的分布
考虑到核辐射在全岛的分布应当是连续性的,空间连续性也是这类模型的假设,接下来绘制热力图,先用 stars 包[3]将预测数据按原网格化的精度转化成栅格对象,裁减超出朗格拉普岛海岸线以外的内容。
library(abind)
library(stars)
rongelap_grid_sf <- st_as_sf(rongelap_grid_df, coords = c("cX", "cY"), dim = "XY")
rongelap_grid_stars <- st_rasterize(rongelap_grid_sf, nx = 150, ny = 75)
rongelap_stars <- st_crop(x = rongelap_grid_stars, y = rongelap_coastline_sfp)除了矢量栅格化函数 st_rasterize() 和栅格剪裁函数 st_crop() ,stars 包还提供栅格数据图层 geom_stars(),这可以和 ggplot2 内置的图层搭配使用。下图 4.7 是 ggplot2 包和 grid 包一起绘制的辐射强度的热力分布图,展示 spaMM 包的预测效果。图左侧一小一大两个虚线框是放大前后的部分区域,展示朗格拉普岛核辐射强度的局部变化。
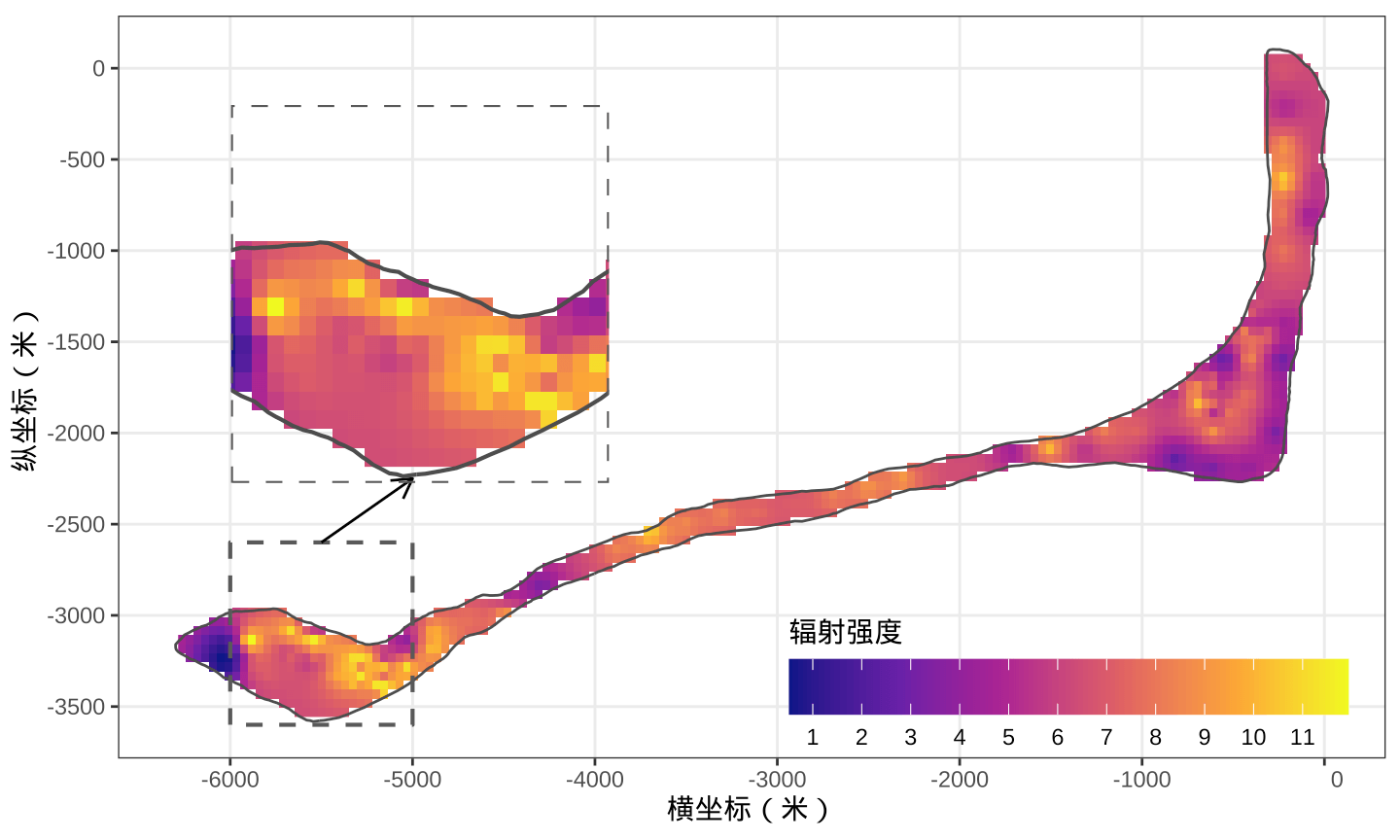
图 4.7: 朗格拉普岛核辐射强度的分布
美国当年是在比基尼环礁做的氢弹核试验,试验地与朗格拉普岛相距 100 多英里。核辐射羽流受大气、海洋环流等影响,漂流到朗格拉普岛。又受朗格拉普岛周围水文、地理环境影响,核辐射强度在全岛的分布是不均匀的,图中越亮的地方表示受到的核辐射越严重。
5 模型理论
5.1 广义最小二乘
nlme 包的函数 gls() 的名称 gls 是 Generalized Least Squares 广义最小二乘的意思。顾名思义,广义最小二乘是最小二乘的推广形式。当模型残差不满足独立同分布的条件,存在相关性或异方差,就需要广义最小二乘 (Generalized Least Squares ,简称 GLS)。在前面的 3.3 ,采用广义最小二乘估计 (3.1) 的参数,下面继续介绍其原理。线性模型的一般形式如下:
\[ \bm{y} = X\bm{\beta} + \bm{\epsilon} \]
其中,\(\bm{y}\) 是 \(n \times 1\) 的列向量,表示响应变量对应的观测数据。 \(X\) 是 \(n \times p\) 的矩阵,表示 \(p\) 维协变量对应的 \(n\) 次观测数据。\(\bm{\beta}\) 是 \(p \times 1\) 的列向量,表示待估的模型参数。 \(\bm{\epsilon}\) 是 \(n \times 1\) 的列向量,表示残差。
假定随机向量 \(\bm{\epsilon}\) 的期望为 \(\mathsf{E}\{\bm{\epsilon}|X\} = \bm{0}\),方差为 \(\mathsf{Var}\{\bm{\epsilon}|X\}=V\) ,且 \(X\) 与 \(\bm{\epsilon}\) 不相关,则有
\[ \mathsf{E}\{\bm{y}|X\} = X\bm{\beta}, \quad \mathsf{Var}\{\bm{y}|X\} = V. \]
现在的目标是找到一个 \(\bm{\beta}\) ,使得残差平方和最小,即求解如下无约束最优化问题。
\[ \begin{aligned} \min_{\bm{\beta}}\quad & \bm{\epsilon}^{\top}\bm{\epsilon} \end{aligned} \tag{5.1} \]
将 \(\bm{\epsilon}= \bm{y} - X\bm{\beta}\) 代入并展开,目标函数可进一步表达为如下形式。
\[ \begin{aligned} \bm{\epsilon}^{\top}\bm{\epsilon} &= (\bm{y} - X\bm{\beta})^{\top}(\bm{y} - X\bm{\beta}) \\ &=\bm{y}^{\top}\bm{y} - \bm{y}^{\top}X\bm{\beta} - (X\bm{\beta})^{\top}\bm{y} + (X\bm{\beta})^{\top}X\bm{\beta} \\ &=\bm{y}^{\top}\bm{y} - 2 \bm{y}^{\top}X\bm{\beta} + \bm{\beta}^{\top}X^{\top}X\bm{\beta} \end{aligned} \]
对 \(\bm{\beta}\) 求偏导,并令偏导等于 \(\bm{0}\)。
\[ -2X^{\top}\bm{y} + 2X^{\top}X\bm{\beta} = 0 \]
可得 \(\bm{\beta}\) 的最小二乘估计 \(\hat{\bm{\beta}}\) 。
\[ \hat{\bm{\beta}} = (X^{\top}X)^{-1}X^{\top}\bm{y}. \]
此时,\(\hat{\bm{\beta}}\) 的期望 \(\mathsf{E}\{\hat{\bm{\beta}}\} = \bm{\beta}\) ,即 \(\hat{\bm{\beta}}\) 是 \(\bm{\beta}\) 无偏的估计。\(\hat{\bm{\beta}}\) 的方差 \(\mathsf{Var}\{\hat{\bm{\beta}}\}\) 的计算如下:
\[ \begin{aligned} \mathsf{Var}\{\hat{\bm{\beta}}\} &= \mathsf{E}\{\hat{\bm{\beta}}^{\top}\hat{\bm{\beta}}\} - \mathsf{E}\{\hat{\bm{\beta}}^{\top}\}\mathsf{E}\{\hat{\bm{\beta}}\} \\ &= \mathsf{E}\{ [(X^{\top}X)^{-1}X^{\top}\bm{y}]^{\top} (X^{\top}X)^{-1}X^{\top}\bm{y} \} - \bm{\beta}^{\top}\bm{\beta} \\ &= \mathsf{E}\{ [(X^{\top}X)^{-1}X^{\top}(X\bm{\beta} + \bm{\epsilon})]^{\top} (X^{\top}X)^{-1}X^{\top}(X\bm{\beta} + \bm{\epsilon}) \} - \bm{\beta}^{\top}\bm{\beta} \\ &= \mathsf{E}\{ [\bm{\beta} + (X^{\top}X)^{-1}X^{\top}\bm{\epsilon}]^{\top} [\bm{\beta} + (X^{\top}X)^{-1}X^{\top}\bm{\epsilon}]\} - \bm{\beta}^{\top}\bm{\beta} \\ &= \mathsf{E}\{\bm{\epsilon}^{\top}X(X^{\top}X)^{-1}(X^{\top}X)^{-1}X^{\top}\bm{\epsilon}\} \\ &= \mathrm{tr}[X(X^{\top}X)^{-1}(X^{\top}X)^{-1}X^{\top}V]. \end{aligned} \]
当 \(\bm{\epsilon}\) 之间存在相关性时,需要广义最小二乘估计,即
\[ \hat{\bm{\beta}}_{gls} = (X^{\top}V^{-1}X)^{-1} X^{\top}V^{-1}\bm{y}. \]
当 \(\bm{\epsilon}\) 之间存在空间相关性时,\(V\) 含有参数 \(\sigma^2,\phi\) ,若模型带块金效应,则还含有参数 \(\tau^2\) 。可见,上式不足以估计模型的参数,且看后续 5.2 。
类似地,对于一次新的观测 \(\bm{x}_0\),它是一个 \(p \times 1\) 的列向量,现在的目标是找到一个 \(\hat{y}_0\) ,在满足无偏性的条件下,使得预测的均方误差 \(\mathsf{E}\{(\hat{y}_0 - y_0)^2\}\) 最小,也是预测方差 \(\mathsf{Var}\{\hat{y}_0 - y_0\}\) 最小,也是残差的方差 \(\mathsf{Var}\{\hat{\epsilon}_0\}\) 最小。不妨设 \(\hat{y}_0\) 是关于 \(\bm{y}\) 的线性组合,即 \(\hat{y}_0 = \bm{w}^{\top}\bm{y}\) ,此处,\(\bm{w}\) 是 \(n \times 1\) 维的权重向量。找 \(\hat{y}_0\) 的问题转为求解如下最优化问题。
\[ \begin{aligned} \min_{\bm{w}}\quad & \mathsf{Var}\{\hat{y}_0 - y_0\} \\ \text{s.t.} \quad & \mathsf{E}\{\hat{y}_0 - y_0\} = 0 \end{aligned} \tag{5.2} \]
对于无偏性的约束条件,有
\[ \mathsf{E}\{\hat{y}_0 - y_0\} = \mathsf{E}\{\bm{w}^{\top}(X\bm{\beta} + \bm{\epsilon}) - (\bm{x}_0^{\top}\bm{\beta} + \bm{\epsilon}_0)\} = \bm{w}^{\top}X\bm{\beta} - \bm{x}_0^{\top}\bm{\beta} = 0 \]
对于目标函数,有
\[ \begin{aligned} \mathsf{Var}\{\hat{y}_0 - y_0\} &= \mathsf{Var}\{\bm{w}^{\top}\bm{y} - \bm{x}_0^{\top}\bm{\beta}- \epsilon_0\} \\ &= \mathsf{Var}\{\bm{w}^{\top}(X\bm{\beta} + \bm{\epsilon}) - \bm{x}_0^{\top}\bm{\beta} - \epsilon_0\} \\ & = \mathsf{Var}\{\bm{w}^{\top}\bm{\epsilon} - \epsilon_0 \} \\ & = \mathsf{E}\{(\bm{w}^{\top}\bm{\epsilon} - \epsilon_0)^2\} - [\mathsf{E}\{(\bm{w}^{\top}\bm{\epsilon} - \epsilon_0)\}]^2 \\ & = \mathsf{E}\{(\bm{w}^{\top}\bm{\epsilon} - \epsilon_0)^2\} \\ & = \mathsf{E}\{(\bm{w}^{\top}\bm{\epsilon} - \epsilon_0)(\bm{w}^{\top}\bm{\epsilon} - \epsilon_0)^{\top}\} \\ & = \bm{w}^{\top}\mathsf{Cov}\{\bm{\epsilon},\bm{\epsilon}^{\top}\} \bm{w} - 2\mathsf{Cov}\{\epsilon_0, \bm{\epsilon}^{\top}\} \bm{w} + \mathsf{Cov}\{\epsilon_0, \epsilon_0 \} \\ & = \bm{w}^{\top}V_{11} \bm{w} - 2 V_{01} \bm{w} + V_{00} \end{aligned} \]
为方便叙述,作如下简记。
\[ V_{11} = \mathsf{Cov}\{\bm{\epsilon},\bm{\epsilon}^{\top}\}, V_{10} = \mathsf{Cov}\{\bm{\epsilon},\epsilon_0\}, V_{01} = \mathsf{Cov}\{\epsilon_0, \bm{\epsilon}^{\top}\}, V_{00} = \mathsf{Cov}\{\epsilon_0, \epsilon_0 \} \]
采用拉格朗日乘数法将约束优化问题 (5.2) 转为如下无约束优化问题
\[ \min_{\bm{w},\bm{\kappa}} \quad \bm{w}^{\top}V_{11} \bm{w} - 2 V_{01} \bm{w} + V_{00} + (\bm{x}_0^{\top} - \bm{w}^{\top}X) \bm{\kappa} \]
其中,\(\bm{\kappa}\) 是 \(p \times 1\) 维的拉格朗日乘子向量,对 \(\bm{w},\bm{\kappa}\) 分别求偏导,并令偏导等于 \(\bm{0}\) 。
\[ \begin{aligned} 2 V_{11} \bm{w} - 2 V_{10} - X\bm{\kappa} = \bm{0} \\ X^{\top}\bm{w} - \bm{x}_0 = \bm{0} \end{aligned} \]
第一个式子左乘 \(X^{\top}V_{11}^{-1}\) ,再将第二个式子代入第一个式子。
\[ 2 \underbrace{X^{\top}\bm{w}}_{\bm{x_0}} -2 X^{\top}V_{11}^{-1}V_{10} - X^{\top}V_{11}^{-1}X\bm{\kappa}= 0 \]
可得拉格朗日乘子向量 \(\bm{\kappa}\) ,再将 \(\bm{\kappa}\) 代入第一个式子,可得权重向量 \(\bm{w}\) 。
\[ \begin{aligned} \bm{\kappa} &= 2 (X^{\top}V_{11}^{-1}X)^{-1} (\bm{x_0} - X^{\top}V_{11}^{-1}V_{10}) \\ \bm{w} &= V_{11}^{-1} \big(V_{10} + X(X^{\top}V_{11}^{-1}X)^{-1}(\bm{x}_0 - X^{\top}V_{11}^{-1}V_{10})\big) . \end{aligned} \]
根据权重向量,可获得预测值 \(\hat{y}_0\) 以及预测方差 \(\mathsf{Var}\{\hat{y}_0\}\) 。
\[ \begin{aligned} \hat{y}_0 &= \bm{w}^{\top}\bm{y} \\ &= V_{01} V_{11}^{-1}\bm{y} + (\bm{x}_0^{\top} - V_{01}V_{11}^{-1}X) (X^{\top}V_{11}^{-1}X)^{-1} X^{\top}V_{11}^{-1}\bm{y} \\ &= \bm{x}_0^{\top}(X^{\top}V_{11}^{-1}X)^{-1} X^{\top}V_{11}^{-1}\bm{y} + V_{01} V_{11}^{-1}\big(\bm{y} - X(X^{\top}V_{11}^{-1}X)^{-1}X^{\top}V_{11}^{-1}\bm{y}\big)\\ &= \bm{x}_0^{\top} \hat{\bm{\beta}}_{gls} + V_{01} V_{11}^{-1}(\bm{y} - X\hat{\bm{\beta}}_{gls}) \end{aligned} \]
而 \(\mathsf{Var}\{\hat{y}_0\} = \mathrm{tr}[\bm{w}\bm{w}^{\top}V_{11}]\) 。
广义最小二乘估计参考课程 Stats 253: Analysis of Spatial and Temporal Data 的 lect5 。
5.2 限制极大似然
nlme 包的函数 gls() 提供极大似然(Maximum Likelihood,简称 ML)和限制极大似然(Restricted Maximum Likelihood,简称 REML)两种方法估计模型参数。
极大似然估计对残差的分布有要求,一般假定 \(\bm{\epsilon}\) 服从多元正态分布,即 \(\bm{\epsilon} \sim \mathrm{MVN}(\bm{0}, V_{\bm{\theta}})\) ,这里 \(V_{\bm{\theta}}\) 表示协方差阵与参数向量 \(\bm{\theta}\) 有关,\(\bm{\theta} = (\sigma^2, \phi, \tau^2)\) ,各个分量的含义同前。则关于参数 \((\bm{\beta}, \bm{\theta})\) 的似然函数如下:
\[ \mathcal{L}(\bm{\beta}, \bm{\theta}) = \frac{1}{(2\pi)^{n/2}(\det V_{\bm{\theta}})^{1/2}}\exp\Big\{-\frac{1}{2}(\bm{y} - X\bm{\beta})^{\top}V_{\bm{\theta}}^{-1}(\bm{y} - X\bm{\beta})\Big\} \]
在前面,已经获得参数 \(\bm{\beta}\) 的广义最小二乘估计 \(\hat{\bm{\beta}}(\bm{\theta})\) 。
\[ \hat{\bm{\beta}}(\bm{\theta}) = (X^{\top}V_{\bm{\theta}}^{-1}X)^{-1} X^{\top}V_{\bm{\theta}}^{-1}\bm{y} \]
将上式代入似然函数 \(\mathcal{L}(\bm{\beta}, \bm{\theta})\) ,意味着消去了参数向量 \(\bm{\beta}\) ,只剩下 \(\bm{\theta}\) 。
\[ \mathcal{L}(\bm{\theta}) = \frac{1}{(2\pi)^{n/2}(\det V_{\bm{\theta}})^{1/2}}\exp\Big\{-\frac{1}{2}\big(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})\big)^{\top}V_{\bm{\theta}}^{-1}\big(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})\big)\Big\} \]
为方便优化计算,进一步对似然函数取对数。
\[ \log \mathcal{L}(\bm{\theta}) = -\frac{n}{2}\log(2\pi) - \frac{1}{2}\log (\det V_{\bm{\theta}}) -\frac{1}{2}\big(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})\big)^{\top}V_{\bm{\theta}}^{-1}\big(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})\big) \]
现在主要关注上式右侧中包含的二次型,将 \(\hat{\bm{\beta}}(\bm{\theta})\) 代入。方便计算和书写起见,临时记 \(A = I - X(X^{\top}V_{\bm{\theta}}^{-1}X)^{-1}X^{\top}V_{\bm{\theta}}^{-1}\) ,这里 \(I\) 是 \(n\) 维单位矩阵。可得
\[ \log \mathcal{L}(\bm{\theta}) = -\frac{n}{2}\log(2\pi) - \frac{1}{2}\log (\det V_{\bm{\theta}}) -\frac{1}{2}\bm{y}^{\top}A^{\top}V_{\bm{\theta}}^{-1}A\bm{y} \]
为了进一步化简,下面计算 \(A^{\top}\) 和 \(A^2\) ,再将它们依次代入上述对数似然函数。
\[ \begin{aligned} AV_{\bm{\theta}} &= V_{\bm{\theta}} - X(X^{\top}V_{\bm{\theta}}^{-1}X)^{-1}X^{\top} \\ A^{\top} &= I -V_{\bm{\theta}}^{-1}(V_{\bm{\theta}} - AV_{\bm{\theta}}) =V_{\bm{\theta}}^{-1} AV_{\bm{\theta}} \\ A^2 &= A \end{aligned} \]
经过上述矩阵运算,\(\log \mathcal{L}(\bm{\theta})\) 化简为如下形式。
\[ \log \mathcal{L}(\bm{\theta}) = -\frac{n}{2}\log (2\pi) - \frac{1}{2}\log (\det V_{\bm{\theta}}) -\frac{1}{2}\bm{y}^{\top}V_{\bm{\theta}}^{-1}\big(I - X(X^{\top}V_{\bm{\theta}}^{-1}X)^{-1}X^{\top}V_{\bm{\theta}}^{-1}\big)\bm{y} \]
对数似然函数的形式还是很复杂,极大化这个对数似然函数,还需要两个关键步骤。
- 计算似然函数关于 \(\bm{\theta}\) 各个分量的偏导数。
- 求解一个非凸优化问题。
考虑到 \(\bm{\theta}\) 的维数不是很高,理论上,可以做暴力网格搜索,但时间花费可能很高,推荐采用一些启发式的全局优化算法。此外,初始值的选取也很重要, \(\bm{\beta}\) 的初值可用最小二乘估计代替,\(\sigma^2\) 的初值可用模型残差的方差代替,\(\tau^2\) 的初值可取 \(\sigma^2\) 的十分之一,\(\phi\) 的初值可取最大距离的十分之一。上述固定一部分参数,估计另一部分参数的过程,叫剖面极大似然(Profile Maximum Likelihood)。不难理解,剖面极大似然估计是个有偏的估计。它将全参数空间剖开,在剖面(超平面)上寻找剩余参数的极大似然估计。
极大似然估计参考课程 Stats 253: Analysis of Spatial and Temporal Data 的 lect4 。
介绍限制极大似然之前,先回顾一下线性模型的一般形式
\[ \bm{y} = X\bm{\beta} + \bm{\epsilon} \]
找一个 \(n\) 阶方阵 \(P\) 使得 \(PX\bm{\beta} = \bm{0}\) ,且 \(P\) 不依赖于 \(\bm{\beta}\),这样的矩阵 \(P\) 形式如下
\[ P = I - X(XX^{\top})^{-1}X^{\top} \]
不难发现,矩阵 \(P\) 具有性质 \(P^{\top} = P, P^2 = P\) ,即矩阵 \(P\) 是一个投影矩阵。线性模型的一般形式化为
\[ P\bm{y} = P \bm{\epsilon} \]
这就是说将整个模型投影到一个新的空间中,在这个新的空间中,模型不含有参数 \(\bm{\beta}\) ,只剩下参数 \(\bm{\theta}\)。然后,极大化似然函数,得到 \(\bm{\theta}\) 的估计 \(\hat{\bm{\theta}}\) ,再将 \(\hat{\bm{\theta}}\) 代入 \(\bm{\beta}\) 的广义最小二乘估计 \(\hat{\beta(\bm{\theta})}\) ,至此,模型参数全部求解完毕。相比于剖面极大似然估计,限制极大似然估计偏差更小。
\[ \log \mathcal{L}^{\star}(\bm{\theta}) = -\frac{n}{2}\log(2\pi) - \frac{1}{2}\log (\det V_{\bm{\theta}}) - \frac{1}{2}\log(\det X^{\top} V_{\theta}^{-1}X) -\frac{1}{2}\big(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})\big)^{\top}V_{\bm{\theta}}^{-1}\big(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})\big) \]
在无偏性约束下,最小均方预测误差意义下,获得最佳线性无偏预测。
\[ \begin{aligned} \min_{\bm{w}} \quad & \mathsf{Var}\{\hat{y}_0 - y_0\} \\ \text{s.t.} \quad & \mathsf{E}\{\hat{y}_0 - y_0\} = 0 \end{aligned} \]
类似前面的广义最小二乘估计一节中的预测过程,可得
\[ \hat{y}_0 = \bm{x}_0^{\top} \hat{\bm{\beta}}(\bm{\theta}) + V_{01} V_{11}^{-1}(\bm{y} - X\hat{\bm{\beta}}(\bm{\theta})) \]
形式上一点没变,除了 \(\hat{\bm{\beta}}(\bm{\theta})\) 中参数 \(\bm{\theta}\) 是上面限制极大似然估计的结果,其它符号的含义同前。
5.3 克里金插值
在空间分析中,克里金插值(Kriging Interpolation)是非常基础且重要的内容,具有很好的统计性质,是最佳线性无偏预测(Best Linear Unbiased Predictor)。下面介绍普通克里金(Ordinary kriging)插值的原理,图 5.1 是示意图。
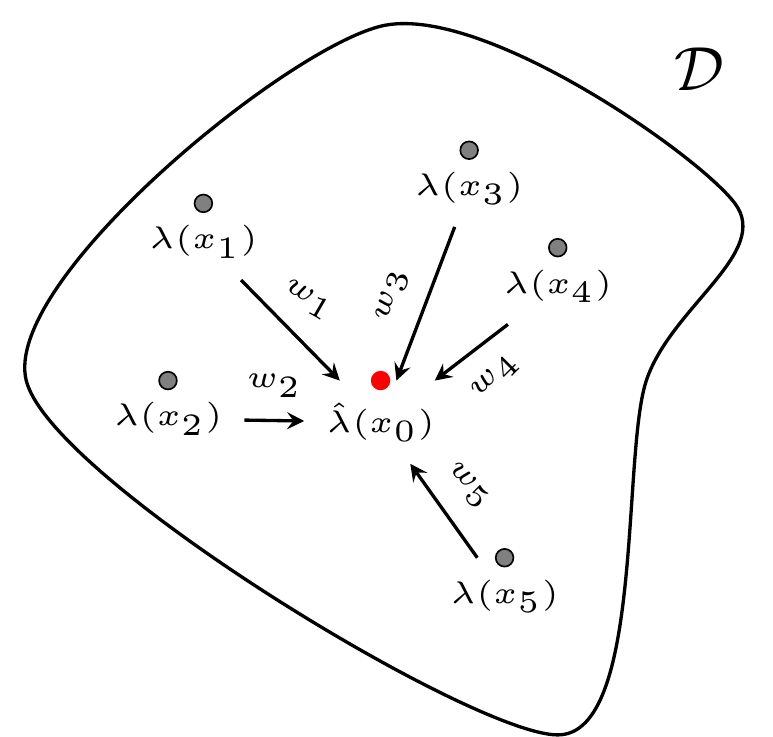
图 5.1: 普通克里金插值
已知研究区域 \(\mathcal{D} \subset \mathbb{R}^2\) 中的采样点 \(x_i \in \mathcal{D}\) 的辐射强度为 \(\lambda(x_i)\) 。对于区域 \(\mathcal{D}\) 中未采样的位置 \(x_0\),它的辐射强度 \(\lambda(x_0)\) 是多少?在满足无偏性的条件下,\(\hat{\lambda}(x_0)\) 是使预测方差最小的估计。
\[ \hat{\lambda}(x_0) = \sum_{i=1}^{n}w_i\lambda(x_i) \]
其中 \(w_i\) 是待定的权重系数。\(\hat{\lambda}(x_0)\) 是 \(\lambda(x_0)\) 的无偏估计,要使预测方差最小,需求解如下最优化问题。
\[ \begin{aligned} \min_{\bm{w}} \quad & \frac{1}{2}\mathsf{Var}\{\hat{\lambda}(x_0) - \lambda(x_0)\} \\ \text{s.t.} \quad & \mathsf{E}\{\hat{\lambda}(x_0) - \lambda(x_0) \} = 0 \end{aligned} \tag{5.3} \]
在平稳性的假设下, \(\mathsf{E}\{\lambda(x_i)\} = \mathsf{E}\{\lambda(x_0)\}\) 且 \(\mathsf{Var}\{\lambda(x_i)\} = \sigma^2\) 。根据无偏性条件可推导出
\[ \sum_{i=1}^{n}w_i = 1. \]
令 \(\bm{\lambda} = [\lambda(x_1),\lambda(x_1),\ldots,\lambda(x_n)]^{\top}\) ,\(V\) 表示随机向量 \(\bm{\lambda}\) 的协方差矩阵 \(\mathsf{Var}\{\bm{\lambda}\}\) ,其第 \(i\) 行第 \(j\) 列的元素为 \(\mathsf{Cov}\{\lambda(x_i),\lambda(x_j)\}\) ,对角线上的元素为方差 \(\mathsf{Var}\{\lambda(x_i)\}, i = 1,2,\ldots, n\) 。令 \(\bm{w} = (w_1,w_2,\ldots,w_n)^{\top}\) ,则
\[ \hat{\lambda}(x_0) = \sum_{i=1}^{n}w_i\lambda(x_i) = \bm{w}^{\top}\bm{\lambda}. \]
根据随机向量二次型,\(\hat{\lambda}(x_0)\) 的方差 \(\mathsf{Var}\{\hat{\lambda}(x_0)\}\) 有
\[ \mathsf{Var}\{\hat{\lambda}(x_0)\} = \bm{w}^{\top}\mathsf{Var}\{\bm{\lambda}\}\bm{w} = \bm{w}^{\top}V\bm{w}. \]
因此,
\[ \begin{aligned} \mathsf{Var}\{\hat{\lambda}(x_0) - \lambda(x_0)\} &= \mathsf{Var}\{\hat{\lambda}(x_0) \} + \mathsf{Var}\{\lambda(x_0)\} - 2 \mathsf{Cov}\{\hat{\lambda}(x_0), \lambda(x_0)\} \\ &= \bm{w}^{\top}V\bm{w} + \sigma^2 - 2\sum_{i=1}^{n} \mathsf{Cov}\{\lambda(x_i),\lambda(x_0)\}w_i \\ & = \bm{w}^{\top}V\bm{w} + \sigma^2 - 2[\mathsf{Cov}\{\bm{\lambda},\lambda(x_0)\}]^{\top}\bm{w} \\ & = \bm{w}^{\top}V\bm{w} + \sigma^2 - 2\bm{u}^{\top}\bm{w} . \end{aligned} \tag{5.4} \]
其中,\(\mathsf{Var}\{\lambda(x_0)\} = \mathsf{Var}\{\lambda(x_i)\}= \sigma^2\) 是未知常数,\(\bm{u} = \mathsf{Cov}\{\bm{\lambda},\lambda(x_0)\}\) 是未知的 \(n \times 1\) 向量。假设它们已知,采用拉格朗日乘数法将约束优化问题 (5.3) 转为如下无约束优化问题。
\[ \min_{\bm{w},\kappa} \mathcal{L}(\bm{w},k) = \frac{1}{2}\bm{w}^{\top}V\bm{w} + \frac{1}{2}\sigma^2 - \bm{u}^{\top}\bm{w} + \kappa (1 - \bm{1}^{\top} \bm{w}) \]
其中,\(\kappa\) 表示拉格朗日乘子,\(\bm{1}\) 表示 \(n \times 1\) 维的全 1 向量。分别对 \(\bm{w}\) 和 \(\kappa\) 求偏导,并令其分别等于零向量 \(\bm{0}\) 和零 \(0\) ,则有
\[ \begin{aligned} \frac{\partial \mathcal{L}(\bm{w},\kappa)}{\partial \bm{w}} &= V \bm{w} - \bm{u} - \kappa \bm{1}= \bm{0} \\ \frac{\partial \mathcal{L}(\bm{w},k)}{\partial \kappa} &= \bm{1}^{\top} \bm{w} - 1 = 0 \end{aligned} \]
联立上述方程可得方程组,一共 \(n+1\) 个变量和方程。
\[ \begin{bmatrix} V & \bm{1} \\ \bm{1}^{\top} & 0 \end{bmatrix} \begin{bmatrix} \bm{w} \\ -\kappa \end{bmatrix} = \begin{bmatrix} \bm{u} \\ 0 \end{bmatrix}. \]
第一个方程左乘 \(\bm{1}^{\top}V^{-1}\) ,再将第二个式子代入,可得
\[ \begin{aligned} \kappa &= \frac{1- \bm{1}^{\top}V^{-1}\bm{u}}{\bm{1}^{\top}V^{-1}\bm{1}} \\ \bm{w} &= V^{-1}(\bm{u} + \frac{1- \bm{1}^{\top}V^{-1}\bm{u}}{\bm{1}^{\top}V^{-1}\bm{1}} \bm{1}) \end{aligned} \]
所以,在位置 \(x_0\) 处的预测 \(\hat{\lambda}(x_0)\) ,
\[ \hat{\lambda}(x_0) = \bm{w}^{\top}\bm{\lambda}= (\bm{u}^{\top} + \frac{1- \bm{1}^{\top}V^{-1}\bm{u}}{\bm{1}^{\top}V^{-1}\bm{1}} \bm{1}^{\top}) V^{-1}\bm{\lambda} \]
将 \(\bm{w}\) 代入 (5.4) 可得普通克里金插值的最小均方预测误差。
\[ \mathsf{Var}\{\hat{\lambda}(x_0) - \lambda(x_0)\} = \bm{u}^{\top}V^{-1}\bm{u} - \frac{\big(1- \bm{1}^{\top}V^{-1}\bm{u}\big)^2}{\bm{1}^{\top}V^{-1}\bm{1}} \]
根据数据可以估计经验半变差函数 (3.4) 的参数,从而 \(\beta\)、\(V\) 、 \(\sigma^2\) 和 \(\bm{u}\) 都是已知的。以 \(V + \tau^2I\) 替换 \(V\) ,\(\bm{\lambda} - \beta \bm{1}\) 替换 \(\bm{\lambda}\) ,可得普通克里金插值的预测值 \(\hat{\lambda}(x_0)\) 及其方差 \(\mathsf{Var}\{\hat{\lambda}(x_0)\}\) 。相比于普通克里金插值,简单克里金插值中 \(\beta\) 是已知的,没有权重之和等于 1 的约束。
参考《Statistics for Spatial Data》[4]。
6 拓展阅读
在过去的 20 多年里,朗格拉普岛核辐射数据集在多篇文章中作为案例分析出现,用于算法模型的比较。1998 年 Peter J. Diggle 等首次提出蒙特卡洛极大似然方法估计不带块金效应的响应变量服从泊松分布的空间广义混合效应模型的参数,分析了朗格拉普岛上核辐射强度的空间分布[5]。2004 年 Ole F Christensen 在 Peter J. Diggle 等人的基础上添加了块金效应,同样使用蒙特卡洛极大似然方法估计了模型中的参数[6]。由于现有算法表现受真实数据影响比较大,随后,2006 年 Ole F Christensen 等又提出更加稳健的 Langevin-Metropolis 算法,辅以重参数化技巧提升算法性能,可以在马尔可夫链混合和收敛方面独立于数据,并在朗格拉普岛核辐射数据中做了实验,体现出预期效果[7]。2015 年 Wagner Hugo Bonat 等在朗格拉普岛核辐射数据和蚕豆根腐病数据中比较了 MCMC 算法,MCEM 算法和修正的拉普拉斯近似算法,发现拉普拉斯近似可以提供类似的结果,基于剖面似然可以获得模型参数的置信区间,相比于模拟算法,不需要算法调参和收敛分析 [8]。2016 年 Erlis Ruli 等提出改进的拉普拉斯近似算法,用于边际似然函数,处理高维随机效应的积分,比较了现有的一些基于似然函数的推断方法,体现出渐进误差更小,在朗格拉普岛核辐射强度预测中更加精确[9]。对算法实现过程感兴趣的读者可以查阅前述参考文献。
2002 年张首次提出蒙特卡洛极大似然算法给出空间广义线性混合效应模型的估计与预测[10],因混合模型的多样性,参数计算的复杂性,后续学者们分别从贝叶斯和频率方法的视角提出精确和近似的算法。近似算法的想法是找了一个近似函数替换其中的部分或者全部,使得随着迭代次数增加的情况下,估计的参数值可以趋于真值。精确算法的想法是通过模拟计算的方式硬积一个高维积分,不断增加采样的次数逼近目标函数,比如基于 MCMC 及其改进型 HMC 和 NUTS 硬积参数的联合后验分布中的高维积分做参数的全贝叶斯推断。贝叶斯方法主流的有拉普拉斯近似和全贝叶斯推断,频率方法主流的有基于似然的拉普拉斯近似和自适应高斯-埃尔米特算法。R 语言社区的 spaMM 包[11],INLA 包[12, 13]、glmmfields 包[14]、glmmTMB [15]、sdmTMB 包[16] 和 hglm 包[17]都可以用来拟合模型。
- spaMM 包采用拉普拉斯近似算法拟合空间广义线性混合效应模型,兼容 lme4 包的公式语法,提供统一的使用方式,还可以与 INLA 包集成。
- INLA 包采用随机偏微分方程方法将目标区域划分成三角网格,以拉普拉斯集成嵌套计算方法逼近参数的后验分布[18]。预测精度和速度主要由网格的细密程度决定,对于大规模空间数据集,比如数以千计的采样点,可以将网格划分得稀疏一些,总是可以计算。内部采用了并行迭代和英特尔 MKL 矩阵优化工具库。
- glmmfields 包以多元 t 分布替代多元正态分布表示高斯马尔可夫随机场拟合带极端事件的时空模型,所以它不局限于本文涉及的空间模型。glmmfields 包内建的空间和时空模型是基于 Stan 的,因此,采用全贝叶斯精确推断方式,一般以 NUTS 采样的方式获取参数后验分布,主要算法是汉密尔顿蒙特卡洛 HMC, 对自动微分变分推断方式有试验性支持。
- sdmTMB 包与 glmmTMB 包源自一脉,内部的计算框架都来自 TMB,相比而言,支持的模型更多,特别是生态学领域的空间和时空模型。
- hglm 包对于具有分层结构的混合效应模型,提出 H-Likelihood 方法拟合分层广义线性模型、空间条件自回归模型 [19]。