本文引用的所有信息均为公开信息,仅代表作者本人观点,与就职单位无关。
1 本文概览
首先挑选一些感兴趣的话题,我个人对社会经济方面的有兴趣,内在的动力在于我想了解自己所处的这个复杂的社会。在我掌握一些数据分析的工具后,想要自己动手去复现、验证看到或听到的结论,也很有兴趣提出自己的问题,并从某个角度切入。从收集数据、校验数据、探索数据、分析数据、解释数据等过程中,打磨自己的技能,同时,深入地了解社会。本文想完整展现自己的一段分析过程,以美国失业率数据为例。
约 6-7年前,我在 maps 包里了解到 unemp 数据集,是一份 2009 年美国各个郡县的失业率数据,它有三个变量,fips 郡县代码,pop 人口,unemp 失业率。还了解到另外一个数据集 county.fips,它有两个变量,fips 郡县代码, polyname 州郡名称。有这份数据,我们可以展示 2009 年美国各个地方的失业率,最直接的可视化方法就是直方图和地区分布图。 直方图将连续型的数据,划分区间,统计每个失业率区间内,郡县的数量。地区分布图将每个郡县的失业率映射到美国郡县级的地图上,可以看到失业率在空间上的分布。时至今日,还可以收集尽可能多的历史数据,展示失业率的空间变化。进一步,收集和失业率紧密相关的数据指标,以及联邦政府、中央银行的经济政策。
以美国的失业率数据为例,还有些原因,美国人口调查局发布的数据完整,有 R 包封装了相关数据接口,数据获取也方便。世界银行也发布了很多世界发展相关的数据,可以结合起来分析,有相互印证的作用。在当下的环境中,对大部分人来说,失业率不是陌生的指标,却是十分关注的指标,算是一个热门话题。
R 语言实现数据分析的完整过程,尽可能使得计算和内容可重复。希望对那些用 R 语言来工作的人有一些启发,也希望引起一些读者的兴趣,去找到自己感兴趣的话题,亲自动手探索一番,将探索的过程和结果分享出来。
2 探索工具
早些年, ggplot2 包 [1] 与 maps [2]、mapproj [3] 和 mapdata [4] 一起提供基于 Base R 的地理可视化方案。而后,又出现了 grid [5] 包、lattice 包 [6] 及其插件 latticeExtra 包 [7] 一起提供基于栅格绘图系统(Trellis Graphics)的地理可视化方案。近年来,ggplot2 包 [8] 与 sf 包 [9]、tigris [10] 和 tidycensus [11] 一起彻底革新了绘图方案,在空间数据获取、处理和可视化方面都更加的高效。这使得空间数据读取 rgdal [12] 、空间数据处理 maptools [13] 和空间几何计算 rgeos [14] 完全可以被 sf 包替代,一下子还替代了好些个空间坐标投影的 reproj 包 [15]、PROJ 包 [16]和 proj4 包 [17],基于 sp 包 [18] 的栅格数据处理 raster 包也跟着升级,不再依赖 sp 包,替之以 terra 包,与国际开源空间统计分析社区更加接轨。连接使用 Google 地图服务的 ggmap [19] 、RgoogleMaps [20]、plotKML [21] 和 mapmisc [22],可以被 tmap 包 [23] 替代。leaflet 包[24]提供开放街道地图数据的获取接口,同时提供许多地理数据可视化的方法,地图可以缩放交互。还有一些辅助作图的 R 包,常用的有处理中文字体的 showtext 包[25],提供丰富层次的调色板 viridisLite 包[26],制作动态图形的 gganimate 包[27]、echarts4r 包[28]和 plotly 包[29]等。更多内容请看 R 语言官网提供的两个视图:Spatial和SpatioTemporal。
3 数据获取
本文获取的公开数据来源
- maps 包内置的美国各郡县失业率数据,tigris 包获取美国最新的比例尺 1:2000,0000 州、郡县级地图数据。
- tidycensus 包获取美国人口调查局发布的社会经济数据。
- wbstats 包获取世界银行发布的发展数据。
获取数据的具体代码见后文。
4 数据探查
maps 包内置了美国州、郡级地图数据,从下图 4.1 不难看出,地图数据是不完整的。一眼看去,至少缺少阿拉斯加州、夏威夷州和波多黎各领地。
图 4.1: 美国州、郡地图
maps 包还内置了数据集 county.fips,记录了美国各郡县的行政代码及州郡名称,一共 3085 各郡县的 FIPS 代码 fips 和名称 polyname。
str(county.fips)
# 'data.frame': 3085 obs. of 2 variables:
# $ fips : int 1001 1003 1005 1007 1009 1011 1013 1015 1017 1019 ...
# $ polyname: chr "alabama,autauga" "alabama,baldwin" "alabama,barbour" "alabama,bibb" ...maps 包也内置了 unemp 数据集,记录了 2009 年美国各郡县的失业率,一共 3218 个郡县的失业率 unemp、人口 pop 和 FIPS 代码 fips。结合 county.fips 和 unemp 数据集来看,显然数据集 county.fips 要么早就过时了,要么收录不完整,导致至少缺少了 3218 - 3085 = 133 个郡县的 FIPS 代码。
str(unemp)
# 'data.frame': 3218 obs. of 3 variables:
# $ fips : int 1001 1003 1005 1007 1009 1011 1013 1015 1017 1019 ...
# $ pop : int 23288 81706 9703 8475 25306 3527 8884 52055 13726 11583 ...
# $ unemp: num 9.7 9.1 13.4 12.1 9.9 16.4 16.7 10.8 18.6 11.8 ...数据初步探查的结果是:相对失业率数据集 unemp 来说,美国州、郡县级地图数据不完整,各郡县 FIPS 代码数据集 county.fips 不完整。
美国各郡县的 FIPS 代码可类比我国行政区划代码,自1980年以来,每年都会发布一次,涉及一些市、区、县、乡、镇、街道等的变更。
county.fips 没有夏威夷、阿拉斯加、波多黎各的地图数据,导致 unemp 数据集里阿拉斯加、夏威夷、波多黎各和部分弗吉尼亚的小城市无法映射到地图上。
相对于 unemp 数据集,county.fips 数据集少了哪些地区的 FIPS 代码,当采用左关联来检查数据情况时,发现 county.fips 缺少 143 个郡县的代码。
tmp <- merge(x = unemp, y = county.fips, all.x = TRUE)
tmp2 <- tmp[is.na(tmp$polyname), ]
dim(tmp2)
# [1] 143 4
head(tmp2)
# fips pop unemp polyname
# 68 2013 1148 10.1 <NA>
# 69 2016 2903 8.4 <NA>
# 70 2020 153264 7.0 <NA>
# 71 2050 7061 14.8 <NA>
# 72 2060 1159 3.6 <NA>
# 73 2068 2300 3.4 <NA>数据集 tmp2 中 fips 代码的前两位代表州,参考维基百科联邦信息处理标准-州代码,可知缺失的 FIPS 代码分布在 6个州或领地,分别是 20-Kansas 堪萨斯州、21-Kentucky 肯塔基州、22-Louisiana 路易斯安那州、15-Hawaii 夏威夷州、51-Virginia 弗吉尼亚州、72-Puerto Rico 波多黎各(领地)。
相对于 unemp 数据集,分各州统计 county.fips 缺少的 FIPS 代码的数量。
# 从郡县 FIPS
tmp2$state_fips <- substr(tmp2$fips, start = 1, stop = 2)
aggregate(data = tmp2, fips ~ state_fips, FUN = length)
# state_fips fips
# 1 15 4
# 2 20 8
# 3 21 10
# 4 22 9
# 5 51 34
# 6 72 78数据集 unemp 和 county.fips 都用整型来存储 FIPS 代码,这是错误的,应该用字符型。没关联上的州编号都是 10 以上,所以上面才能用函数 substr() 抽取州的 FIPS 代码,否则得另想办法统计缺失的分布情况。
在企业中,上面的数据质量探查操作是非常典型的,如果在数据库集群中,检查数据缺失情况,那最好用 SQL 操作,上述 Base R 数据操作等价的 SQL 语句(以 SQLite 为例)如下:
SELECT state_fips,
count(1) AS cnt
FROM
(SELECT A.fips,
substr(A.fips, 1, 2) AS state_fips,
A.pop,
A.unemp,
B.polyname
FROM unemp A
LEFT JOIN county_fips B ON A.fips = B.fips
WHERE B.polyname IS NULL )
GROUP BY state_fips| state_fips | cnt |
|---|---|
| 15 | 4 |
| 20 | 8 |
| 21 | 10 |
| 22 | 9 |
| 51 | 34 |
| 72 | 78 |
5 数据探索
对于区域数据,描述其空间分布采用的常见图形是地区分布图(Choropleth maps)。也叫围栏图,一个个多边形围成的区域就好比大草原上的一个个围栏。也叫面量图,一块块区域加上该区域的属性、度量指标(经济的、人文的、社会的)。
5.1 maps 包
maps 包的函数 map() 帮助文档 ?map 给出了一个示例,地图数据就来自 maps 包,失业率数据 unemp 和行政编码数据 county.fips 也来自 maps 包。经过上面的数据探查,为美观起见,代码有所调整,结合下图 5.1,除了验证数据质量外,2009 年美国各郡县的失业率分布非常直观了。美国东、西两岸经济比较发达,失业率也比较高,从沿海到内陆,失业率由高到低,有比较明显的层次感。
library(maps)
library(mapproj)
# 失业率数据
data(unemp)
# 行政编码
data(county.fips)
# 准备调色板
colors <- viridisLite::plasma(9)
# 失业率划分区间
unemp$colorBuckets <- as.numeric(cut(
unemp$unemp,
c(seq(0, 10, by = 2), 15, 20, 25, 100)
))
# 准备图例文本
leg.txt <- c(
" <2%", " 2-4%", " 4-6%",
" 6-8%", " 8-10%", "10-15%",
"15-20%", "20-25%", " >25%"
)
# 根据区域单元的名称匹配地图数据上每个区域的 FIPS
cnty.fips <- county.fips$fips[match(
map("county", plot = FALSE)$names,
county.fips$polyname
)]
# 根据 FIPS 给地图上每个区域的失业率匹配颜色
colorsmatched <- unemp$colorBuckets[match(cnty.fips, unemp$fips)]
par(mar = c(1.5, 0, 2, 0))
# 绘制区县地图
map("county",
col = colors[colorsmatched], fill = TRUE, resolution = 0,
lty = 0, projection = "polyconic", mar = c(0.5, 0.5, 2, 0.5)
)
# 添加州边界线
map("state",
col = "white", fill = FALSE, add = TRUE,
lty = 1, lwd = 0.4, projection = "polyconic"
)
# 添加图标题
title("2009 年美国各郡县的失业率")
mtext(
text = "数据源:美国人口调查局",
side = 1, adj = 0
)
# 添加图例
legend("bottomright",
title = "失业率(%)",
legend = leg.txt,
horiz = FALSE,
fill = colors, cex = 0.85,
box.col = NA, border = NA
)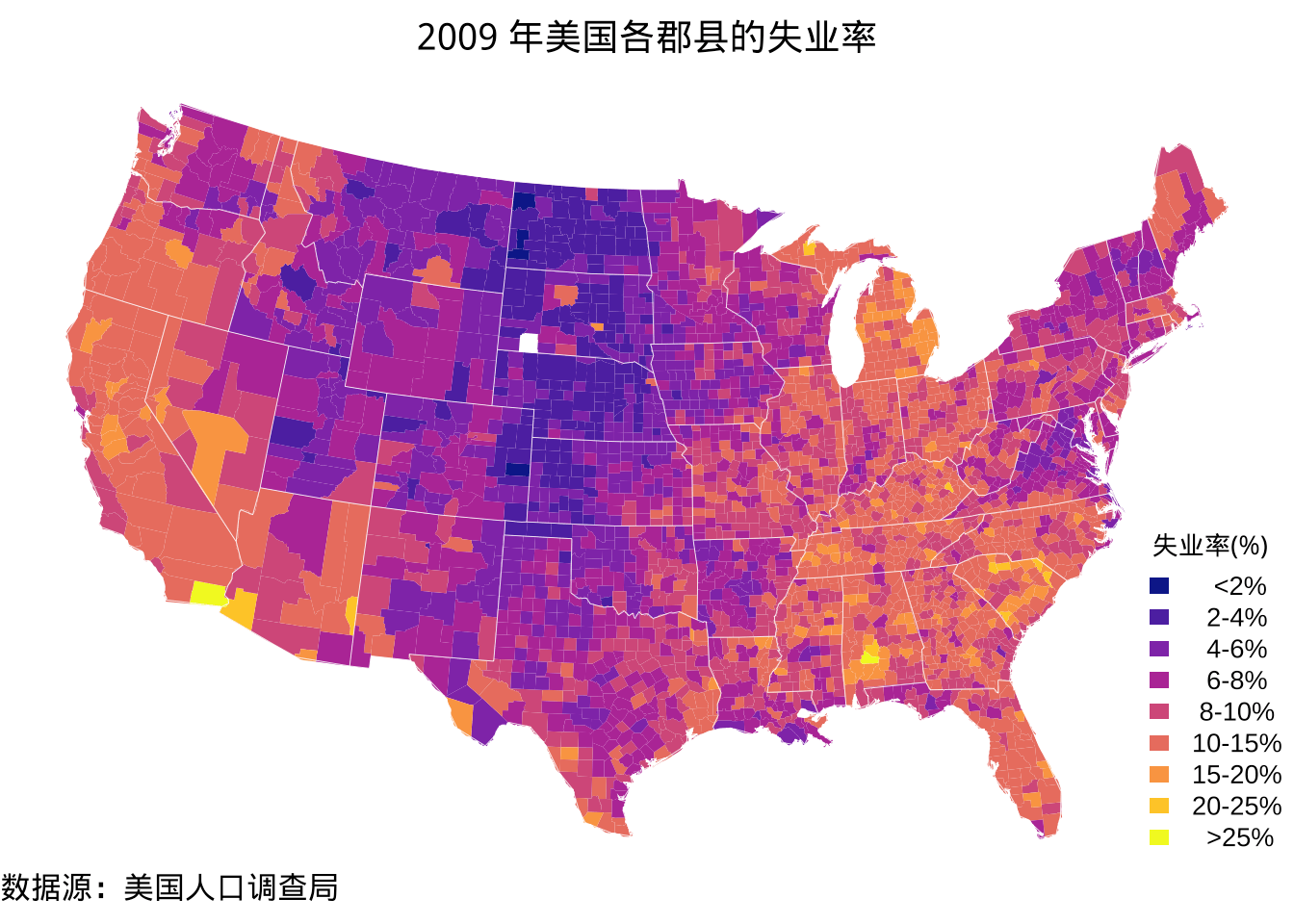
图 5.1: 2009 年美国各郡县的失业率分布
5.2 latticeExtra 包
在数据探索的工具上,也可以用 latticeExtra 包来做,不过它也是依赖于 maps 包,依赖地图数据、坐标投影等。在绘制地区分布图方面,仅仅是提供一个新的绘图方式 — 基于 grid 的 lattice 绘图系统。实际操作下来,使用的复杂度不亚于 Base R 的基础绘图系统,而图形效果是基本一致的。更多详细介绍见另一篇文章《地区分布图及其应用》。
# 美国郡边界地图数据
us_county <- map("county",
plot = FALSE, fill = TRUE, projection = "polyconic"
)
# 美国州边界数据
us_state <- map("state",
plot = FALSE, fill = TRUE, projection = "polyconic"
)
# 失业率数据和行政区域名称关联
unemp_df <- merge(unemp, county.fips, by = "fips")
# 绘图
library(lattice)
latticeExtra::mapplot(polyname ~ unemp, data = unemp_df,
# 地图数据
map = us_county,
# 配色采用 plasma 调色板
colramp = viridisLite::plasma,
# 修改默认的面板函数
panel = function(x, y, map, ...) {
# 对未收集到癌症死亡率数据的郡,添加郡边界线
panel.lines(
x = us_county$x, y = us_county$y,
lty = 1, lwd = 0.2, col = "black"
)
# 地区分布图主体
latticeExtra::panel.mapplot(x, y, map, ...)
# 添加州边界线
panel.lines(
x = us_state$x, y = us_state$y,
lty = 1, lwd = 0.2, col = "white"
)
},
# 去掉郡县边界线
border = NA,
# cuts = 10, # 等距分桶的数,和参数 breaks 二选一
breaks = c(seq(0, 10, by = 2), 15, 20, 25, 30, 35),
# 仅绘制地图支持的那些失业率数据
subset = polyname %in% us_county$names,
# 去掉坐标轴
scales = list(draw = F),
# 去掉横轴标签
xlab = "",
# 全局图形参数设置
par.settings = list(
# 副标题放在左下角
par.sub.text = list(
font = 2,
just = "left",
x = grid::unit(5, "mm"),
y = grid::unit(5, "mm")
),
# 轴线设置白色以隐藏
axis.line = list(col = "white")
),
# 副标题
sub = "数据源:美国人口调查局",
# 主标题
main = "2009 年美国各郡县的失业率"
)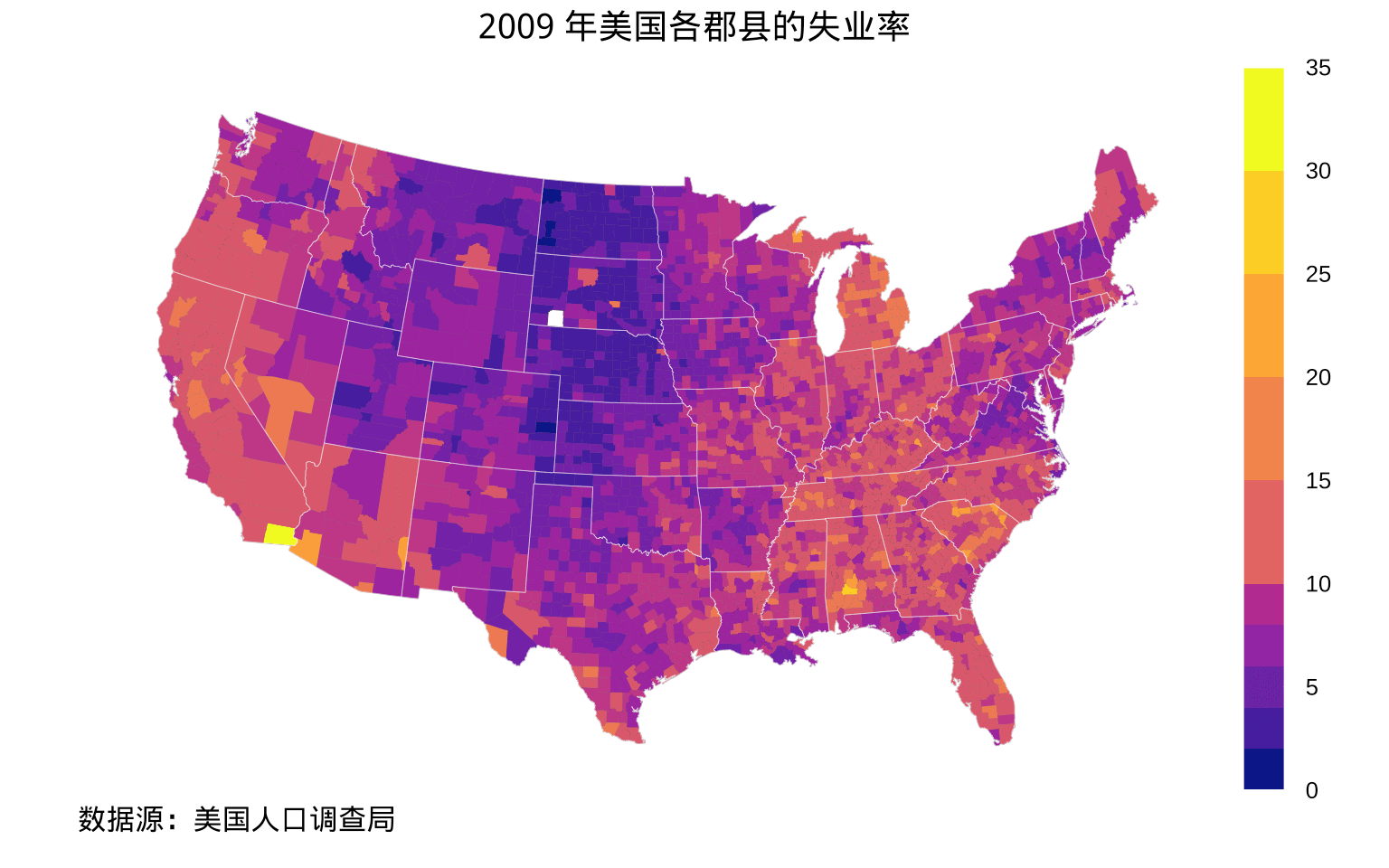
图 5.2: 2009 年美国各郡县的失业率分布
5.3 sf 包
从数据探查的结果可知,应该去获取更加完整的,和失业率数据能匹配上的地图数据。 tigris 包提供较新的美国州、郡县级矢量地图数据。地图数据的获取过程见文章《地区分布图及其应用》。
library(sf)
# 准备地图数据
us_state_map <- readRDS(file = "data/us_state_map.rds")
us_county_map <- readRDS(file = "data/us_county_map.rds")
# 查看数据
us_county_map
# Simple feature collection with 3220 features and 9 fields
# Geometry type: GEOMETRY
# Dimension: XY
# Bounding box: xmin: -3112000 ymin: -1698000 xmax: 2258000 ymax: 1559000
# Projected CRS: USA_Contiguous_Albers_Equal_Area_Conic
# First 10 features:
# STATEFP COUNTYFP COUNTYNS AFFGEOID GEOID NAME LSAD ALAND
# 1 29 227 00758566 0500000US29227 29227 Worth 06 6.906e+08
# 2 31 061 00835852 0500000US31061 31061 Franklin 06 1.491e+09
# 3 36 013 00974105 0500000US36013 36013 Chautauqua 06 2.746e+09
# 4 37 181 01008591 0500000US37181 37181 Vance 06 6.537e+08
# 5 47 183 01639799 0500000US47183 47183 Weakley 06 1.503e+09
# 6 44 003 01219778 0500000US44003 44003 Kent 06 4.366e+08
# 7 08 101 00198166 0500000US08101 08101 Pueblo 06 6.180e+09
# 8 17 175 00424288 0500000US17175 17175 Stark 06 7.462e+08
# 9 29 169 00758539 0500000US29169 29169 Pulaski 06 1.417e+09
# 10 19 151 00465264 0500000US19151 19151 Pocahontas 06 1.495e+09
# AWATER geometry
# 1 4.939e+05 MULTIPOLYGON (((114836 3450...
# 2 4.879e+05 MULTIPOLYGON (((-267685 323...
# 3 1.139e+09 MULTIPOLYGON (((1324221 647...
# 4 4.218e+07 MULTIPOLYGON (((1544260 322...
# 5 3.707e+06 MULTIPOLYGON (((625934 -988...
# 6 5.069e+07 MULTIPOLYGON (((1977965 726...
# 7 3.022e+07 MULTIPOLYGON (((-783174 122...
# 8 6.848e+05 MULTIPOLYGON (((500559 4247...
# 9 1.131e+07 MULTIPOLYGON (((312852 4616...
# 10 3.667e+06 MULTIPOLYGON (((88186 60633...为了将失业率数据合并到地图数据上,需要将地理区域唯一标识 GEOID 作类型转化。GEOID 是两个字符型变量 STATEFP 和 COUNTYFP 拼接起来的字符串变量。根据这份地图数据,可以知道美国目前一共有 3220 个郡县。
# 地理区域唯一标识
us_county_map$GEOID <- as.integer(us_county_map$GEOID)
# 将失业率数据和地图数据合并
us_county_data <- merge(
x = us_county_map, y = unemp,
by.x = "GEOID", by.y = "fips", all.x = TRUE
)从这份地图数据来看,有 8 个郡县没有失业率数据,主要分布在地广人稀的阿拉斯加州 (02-Alaska)。具体原因是什么呢?留待读者思考。
us_county_data[is.na(us_county_data$unemp),]
# Simple feature collection with 8 features and 12 fields
# Geometry type: GEOMETRY
# Dimension: XY
# Bounding box: xmin: -2349000 ymin: -1537000 xmax: -492400 ymax: 712300
# Projected CRS: USA_Contiguous_Albers_Equal_Area_Conic
# GEOID STATEFP COUNTYFP COUNTYNS AFFGEOID NAME LSAD
# 77 2105 02 105 02371430 0500000US02105 Hoonah-Angoon 05
# 82 2158 02 158 01419985 0500000US02158 Kusilvak 05
# 88 2195 02 195 02516404 0500000US02195 Petersburg 04
# 89 2198 02 198 01419980 0500000US02198 Prince of Wales-Hyder 05
# 91 2230 02 230 02339479 0500000US02230 Skagway 12
# 94 2275 02 275 02516402 0500000US02275 Wrangell 03
# 549 15005 15 005 01702380 0500000US15005 Kalawao 06
# 2413 46102 46 102 01266992 0500000US46102 Oglala Lakota 06
# ALAND AWATER pop unemp colorBuckets geometry
# 77 1.698e+10 7.802e+09 NA NA NA MULTIPOLYGON (((-1435018 -1...
# 82 4.422e+10 6.694e+09 NA NA NA MULTIPOLYGON (((-2348786 -1...
# 88 7.513e+09 2.386e+09 NA NA NA MULTIPOLYGON (((-1411642 -1...
# 89 1.363e+10 1.462e+10 NA NA NA MULTIPOLYGON (((-1304827 -1...
# 91 1.124e+09 2.878e+07 NA NA NA MULTIPOLYGON (((-1516456 -1...
# 94 6.620e+09 2.384e+09 NA NA NA MULTIPOLYGON (((-1389562 -1...
# 549 3.106e+07 1.058e+08 NA NA NA POLYGON ((-846359 -1181798,...
# 2413 5.422e+09 7.126e+06 NA NA NA MULTIPOLYGON (((-562220 704...将失业率数据 unemp 视为左表,地图数据 us_county_map 视为右表,检查一下有多少失业率数据关联不上地图数据。实际情况是一共有 6 个郡县的失业率数据关联不上地图数据。
us_county_data_tmp <- merge(
x = unemp, y = us_county_map,
by.x = "fips", by.y = "GEOID", all.x = TRUE
)
us_county_data_tmp[is.na(us_county_data_tmp$STATEFP),]
# fips pop unemp colorBuckets STATEFP COUNTYFP COUNTYNS AFFGEOID NAME LSAD
# 86 2201 2507 13.6 6 <NA> <NA> <NA> <NA> <NA> <NA>
# 88 2232 2278 7.3 4 <NA> <NA> <NA> <NA> <NA> <NA>
# 91 2270 2807 20.4 8 <NA> <NA> <NA> <NA> <NA> <NA>
# 92 2280 2836 9.8 5 <NA> <NA> <NA> <NA> <NA> <NA>
# 2415 46113 3827 12.6 6 <NA> <NA> <NA> <NA> <NA> <NA>
# 2914 51515 2768 8.9 5 <NA> <NA> <NA> <NA> <NA> <NA>
# ALAND AWATER geometry
# 86 NA NA GEOMETRYCOLLECTION EMPTY
# 88 NA NA GEOMETRYCOLLECTION EMPTY
# 91 NA NA GEOMETRYCOLLECTION EMPTY
# 92 NA NA GEOMETRYCOLLECTION EMPTY
# 2415 NA NA GEOMETRYCOLLECTION EMPTY
# 2914 NA NA GEOMETRYCOLLECTION EMPTY经过上面的检查,失业率数据和这份地图数据不是完全匹配的,但是差距也不大。要想进一步改进,甚至达到完全匹配,应该怎么做呢?就是根据收集到的失业率数据所在的年份去找相应年份的郡县地图数据。也就是去找 2009 年美国郡县级多边形矢量地图数据。余下的工作留待读者操作。
相比于前任 sp 包,sf 包将是新一代空间数据操作、分析和可视化的基石,引入 GDAL、PROJ 和 GEOS 三大空间数据处理的基础框架,和更庞大的空间数据社区接轨,不局限于 R 语言社区的一亩三分地。sf 包支持 Base R 绘图,以此绘制失业率专题地图,如图5.3所示,可见效果丝毫不逊于 Base R 和 lattice 版本,而且在兼容性、代码量、稳定性和性能等方面有明显优势。
par(mar = c(2, 0, 4, 0))
# 添加郡县地图作为底图,失业率缺失的地方涂上灰色
plot(st_geometry(us_county_map),
reset = FALSE, border = "grey90",
col = "grey80", main = "2009 年美国各郡县的失业率"
)
# 绘制图形主体
plot(us_county_data["unemp"],
pal = viridisLite::plasma,
breaks = c(seq(0, 10, by = 2), 15, 20, 25, 30, 35),
border = NA, key.pos = NULL, reset = FALSE, add = TRUE
)
# 添加州边界
plot(st_geometry(us_state_map),
col = NA, border = "gray90",
add = TRUE, lwd = 0.2
)
mtext(
text = "数据源:美国人口调查局", side = 1, adj = 0.8
)
# 调色板
colors <- viridisLite::plasma(10)
breaks <- c(seq(0, 10, by = 2), 15, 20, 25, 30, 35)
# 图例文本
leg.txt <- mapply(paste,
breaks[-length(breaks)],
breaks[-1],
collapse = " ", sep = "~"
)
# 添加图例
legend("bottomright",
legend = c(leg.txt, "NA"), title = "失业率(%)",
box.col = NA, border = NA,
horiz = FALSE, fill = c(colors, "grey80"),
cex = 0.85, xjust = 0.5
)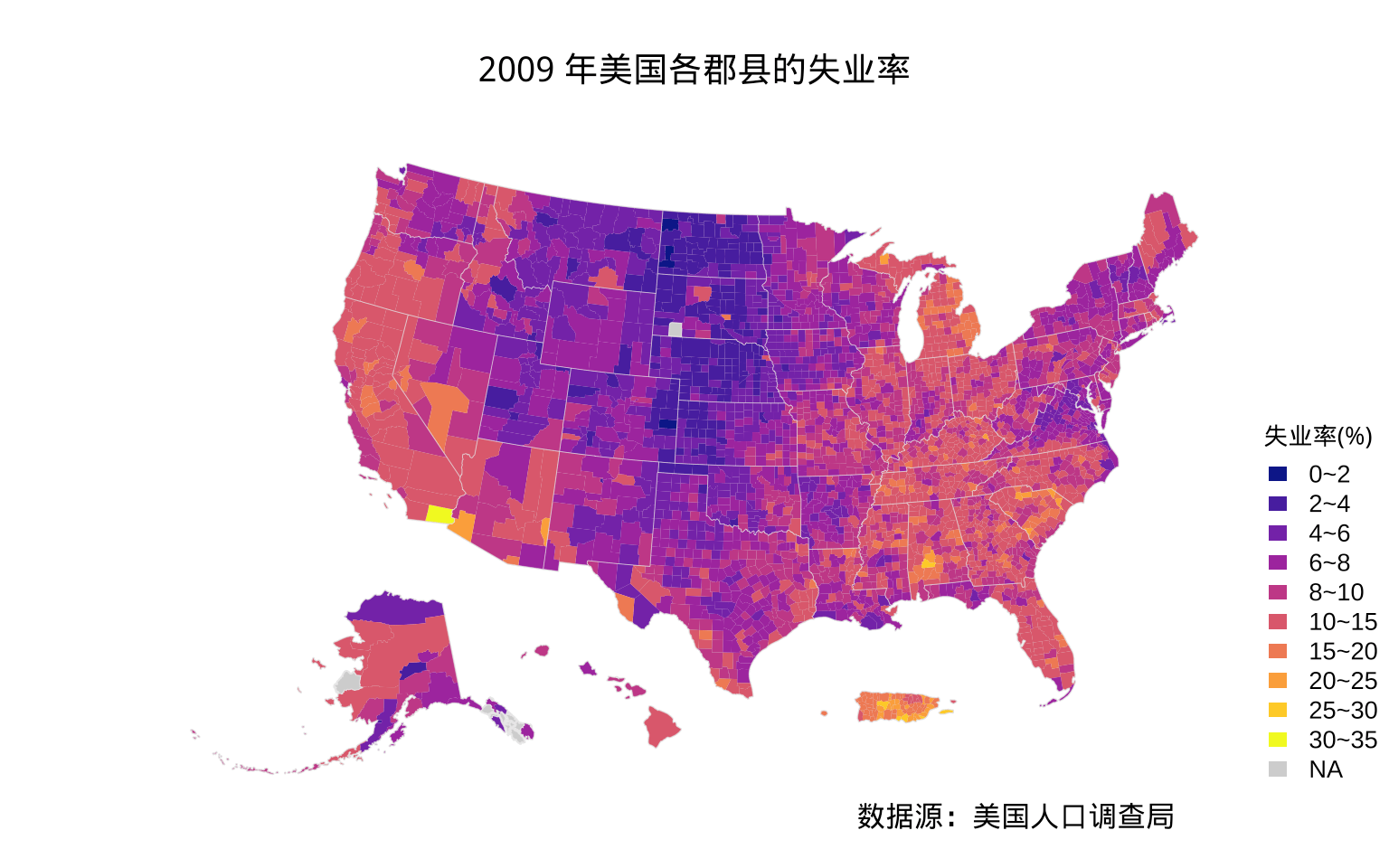
图 5.3: 2009 年美国各个郡县的失业率分布
5.4 ggplot2 包
站在 sf 包的肩膀上,ggplot2 包也可以绘制类似上图5.3的效果。ggplot2 包的特点是有非常清晰的分层,图层层层叠加实现最终效果。优点是掌握其一般规律后,代码简洁易读,缺点是 ggplot2 包不太稳定,函数每隔一段时间会有不向后兼容的破坏性更改。复现下图必须采用与本文运行环境一致的 R 包,笔者当前采用的 ggplot2 版本是 3.4.0。添加郡县级失业率数据,添加州级多边形边界线,设置调色板和图形主题,添加图例标题和副标题,调整州、郡边界线以体现层次。
library(ggplot2)
ggplot() +
geom_sf(
data = us_county_data, aes(fill = unemp),
colour = "grey80", linewidth = 0.05
) +
geom_sf(
data = us_state_map,
colour = "grey80", fill = NA, linewidth = 0.1
) +
scale_fill_viridis_c(
option = "plasma", na.value = "white"
) +
theme_void() +
labs(
fill = "失业率", caption = "数据源:美国人口调查局"
)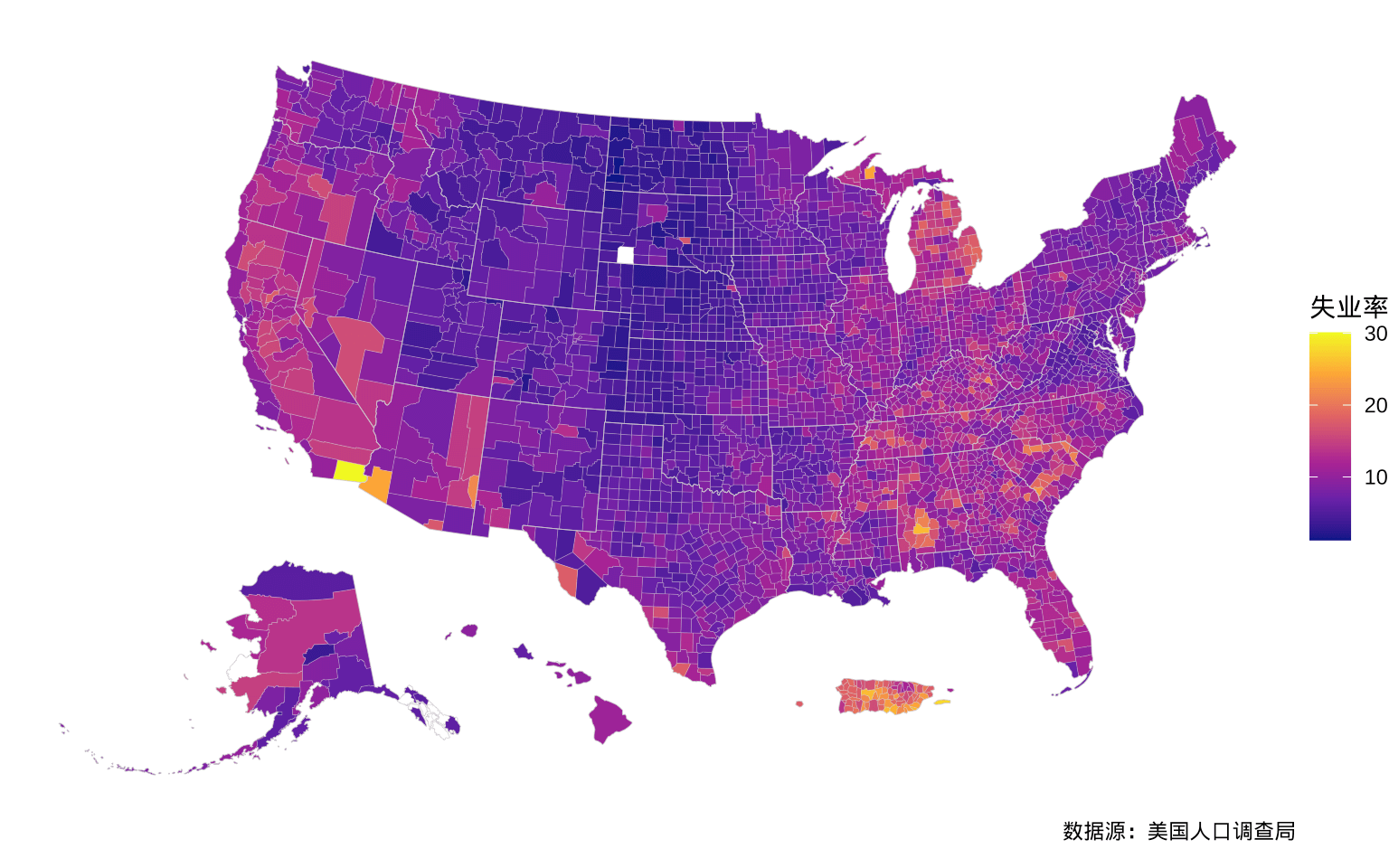
图 5.4: 2009 年美国各郡县失业率分布
请读者参考文章《地区分布图及其应用》给出失业率分段的地区分布图。
以 1PP (即一个百分点,宏观经济指标波动 1 个百分点是很大的事情了)为间隔,统计美国各个郡县的失业率分布情况,如图 5.5 所示,除少量人口多,经济发达的郡县失业率远高于其它外,剩余的呈现正态分布,失业率集中于 8% 左右。
ggplot() +
geom_histogram(data = us_county_data[!is.na(us_county_data$unemp),], aes(x = unemp),
binwidth = 1, fill = "lightblue", color = "white") +
theme_classic() +
labs(x = "失业率", y = "郡县数量")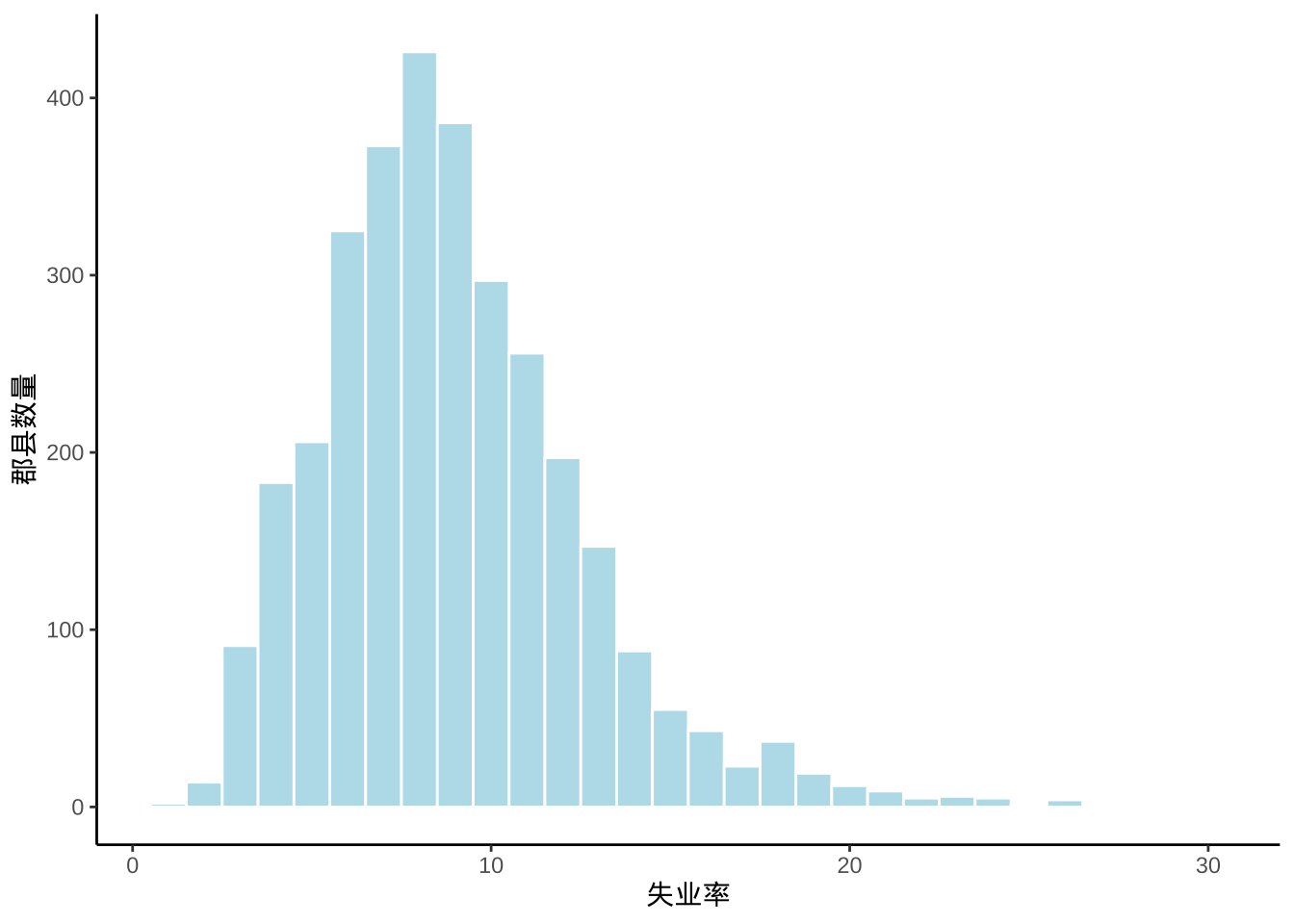
图 5.5: 2009 年美国失业率分布
unemp 数据集还包含一列 pop 人口数(但未提供人口数指标的说明),各个郡县的人口数如图5.6所示。
ggplot() +
geom_sf(
data = us_county_data, aes(fill = pop),
colour = "grey80", linewidth = 0.05
) +
geom_sf(
data = us_state_map,
colour = "grey80", fill = NA, linewidth = 0.1
) +
scale_fill_viridis_c(
option = "plasma", na.value = "white", trans = "log10",
labels = scales::label_number(scale_cut = scales::cut_short_scale())
) +
theme_void() +
labs(
fill = "人口数", caption = "数据源:美国人口调查局"
)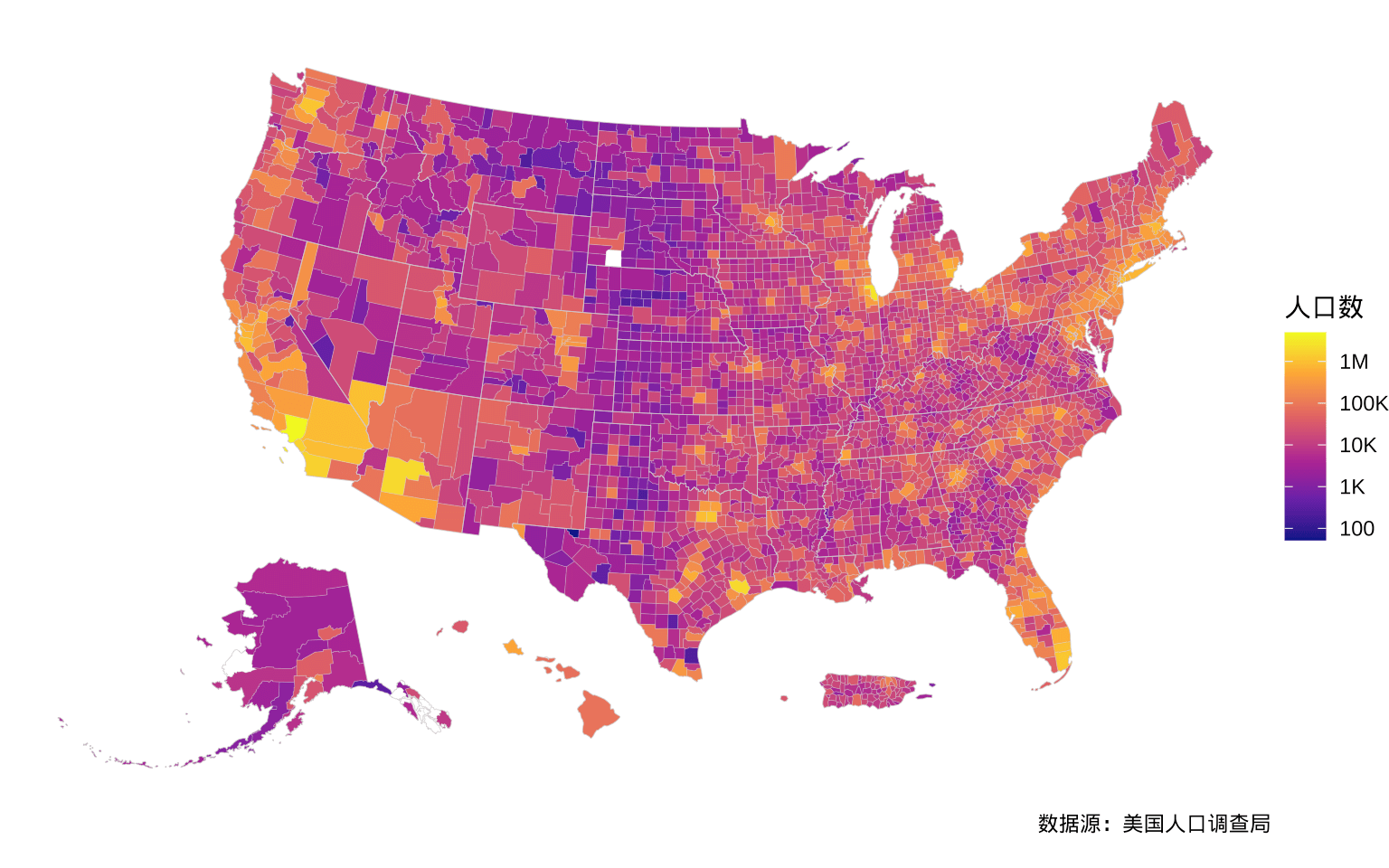
图 5.6: 2009 年美国各郡县人口分布
据查,2009 年美国人口总数超过 3 亿,unemp 数据集显示 2009 年美国各郡县人口总共约 1.5 亿。unemp 数据集中包含的各个郡县人口数具体是何含义,未知。留待读者继续探查。
sum(us_county_data$pop, na.rm = T)
# [1] 1549198626 数据分析
2008 年美国发生次贷危机,雷曼兄弟倒闭,随后席卷全球,2009 年失业率正处于历史高位。2019 年底出现新冠疫情,随后席卷全球,至今未消,2022 年俄乌爆发战争。俄罗斯作为世界上重要的能源输出国,乌克兰作为重要的粮食出口国,中国改革进入深水区,经济周期下行,去杠杆化的效应正在加速显现,失业率达到近30年以来的最高水平,国家正面临百年未有之大变局。
2022年11月15日至16日,二十国集团领导人第十七次峰会在印度尼西亚的巴厘岛举行,峰会主题为「共同复苏、强劲复苏」。G20 包含 中国、韩国、印度、美国、英国、加拿大、德国、意大利、法国、俄罗斯、日本、欧洲联盟、印度尼西亚、墨西哥、南非共和国、沙特阿拉伯、土耳其、澳大利亚、阿根廷、巴西。首先看看 G20 各个国家的整体失业率情况。
世界银行的数据获取参考文章Gapminder:关注差异、理解变化,美国人口调查局的数据获取参考文章地区分布图及其应用。
- 总失业人数(占劳动力总数的比例)(模拟劳工组织估计),指标 ID 为 SL.UEM.TOTL.ZS
- 失业人数是指目前没有工作但可以参加工作且正在寻求工作的劳动力数量。各国对劳动力和失业人数的定义各有不同。详见世界银行网站,经过比对,从数据 API 获得的数据和网站图表中显示的数据是一致的。
- 按消费者价格指数衡量的通货膨胀(年通胀率),指标 ID 为 FP.CPI.TOTL.ZG
- 按消费者价格指数衡量的通货膨胀反映出普通消费者在指定时间间隔(如年度)内购买固定或变动的一篮子货物和服务的成本的年百分比变化。通常采用拉斯佩尔公式进行计算。
- 基尼 (GINI) 系数,指标 ID 为 SI.POV.GINI
- 基尼系数用于衡量一个经济体中在个人或家庭中的收入分配(在某些情况下是消费支出)偏离完全平均分配的程度。洛伦兹曲线标示出总收入累积百分比与收入获得者累积人数的相对关系,曲线的起点为最贫困的个人或家庭。基尼系数测算洛伦兹曲线与假设的绝对平均线之间的面积,表示为在该线以下最大面积中所占的比例。因此,基尼系数为 0 表示完全平均,100% 则表示完全不平均。
从世界银行数据库获取最近 30 年宏观经济数据,实际上,据笔者了解,世界银行仅提供最近 30 年的数据。
wb_world_indicator <- wbstats::wb_data(
indicator = c(
"SL.UEM.TOTL", # 失业人数 Number of people unemployed
"SL.UEM.TOTL.ZS", # 失业率 Unemployed (%) (modeled ILO estimate)
"SL.UEM.TOTL.NE.ZS", # 失业率 Unemployed (%) national estimate
"NY.GDP.PCAP.KD.ZG", # 人均 GDP 增速
"NY.GDP.MKTP.CD", # GDP 总量
"NY.GDP.MKTP.KD.ZG", # GDP 增速
"FP.CPI.TOTL", # 消费价格指数(以 2010 年为对比基数 100)
"FP.CPI.TOTL.ZG", # 通货膨胀率
"SI.POV.GINI", # Gini 指数
"SP.DYN.LE00.IN", # 预期寿命
"NY.GDP.PCAP.CD", # 人均 GDP
"SP.POP.TOTL" # 人口总数
),
country = "countries_only",
return_wide = FALSE,
start_date = 1991, end_date = 2021
)
# 保存数据到本地,方便后续使用
saveRDS(wb_world_indicator, file = "data/wb_world_indicator.rds")从 G20 中选取 11 个国家(中国、印度、美国、英国、德国、法国、俄罗斯、日本、南非共和国、沙特阿拉伯、澳大利亚)。失业率数据、通货膨胀率数据和基尼 (GINI) 系数数据。
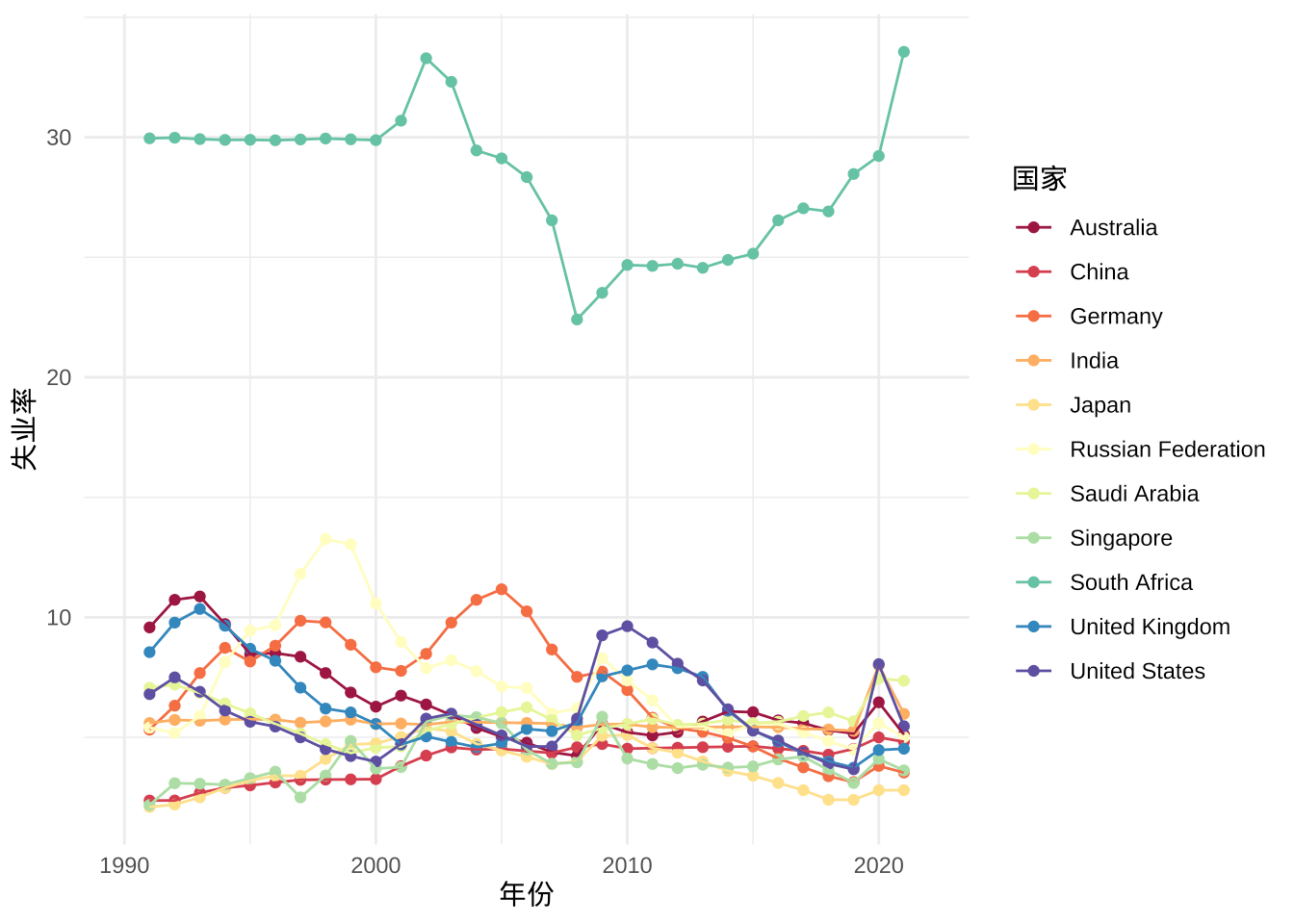
图 6.1: 失业率数据
南非失业率一直居高不下,余下的国家失业率表现比较平稳。2020 年后,美国的失业率上涨比较多。
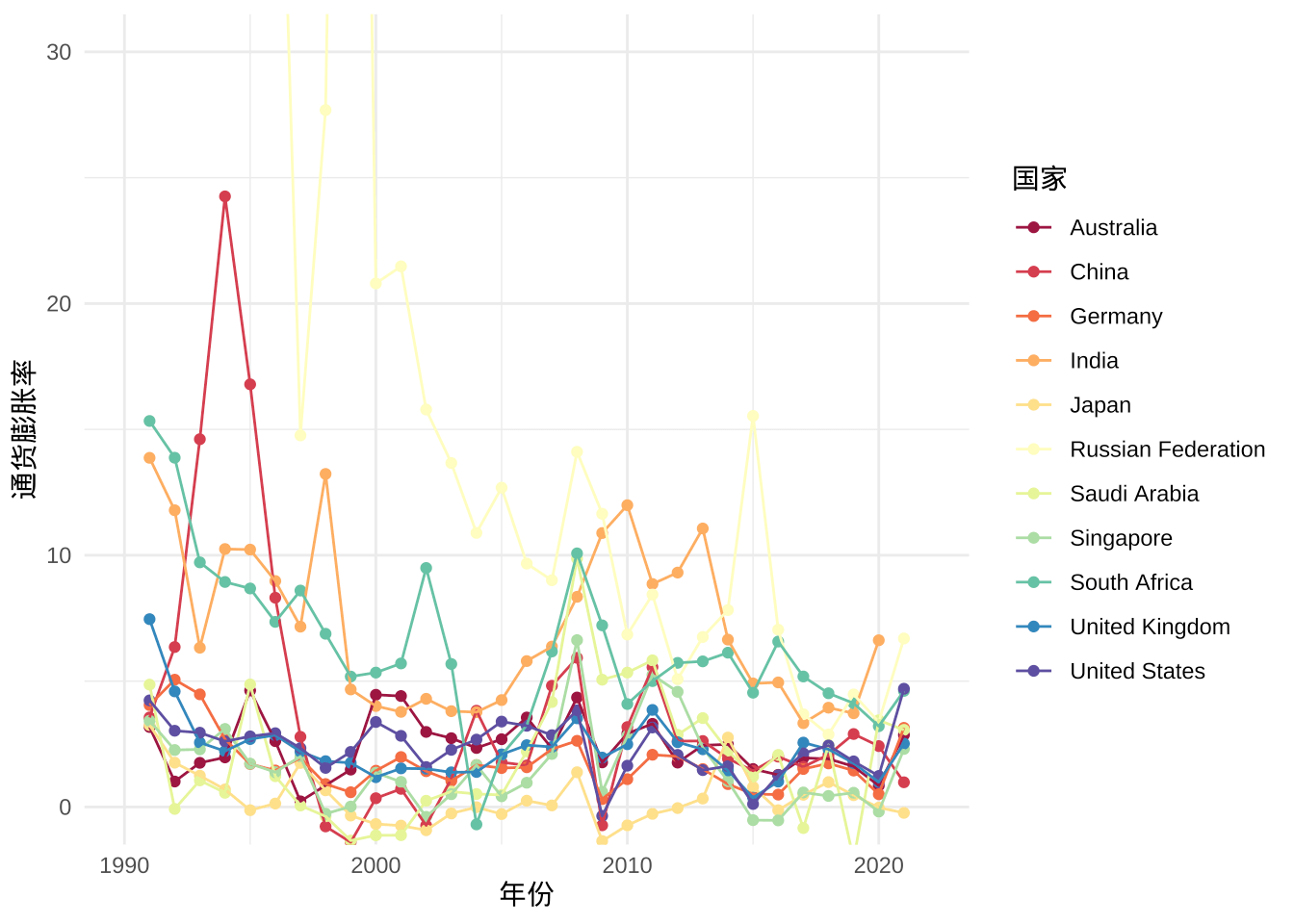
图 6.2: 通货膨胀率数据
苏联解体后,俄罗斯经济上经历了休克疗法,政局不平稳,2000 年前俄罗斯的通胀高得没边,就不去谈它了,图中也没有展示相关数据,重点关注余下的国家。
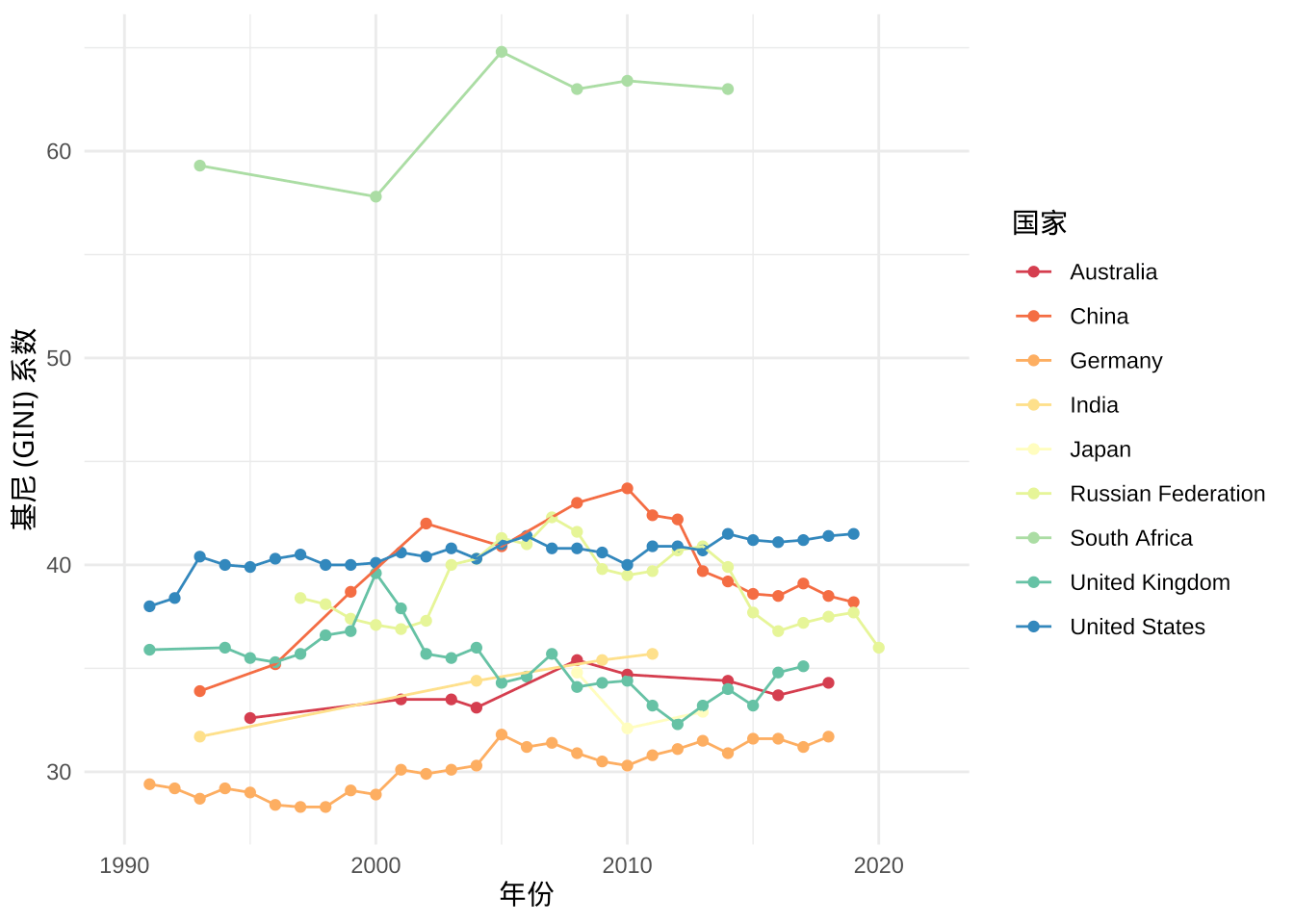
图 6.3: 基尼 (GINI) 系数数据
基尼 (GINI) 系数数据不太多,南非有很高的基尼系数,贫富差距巨大,大部分在 30% - 40% 之间。中国贫富差距比美国小,比俄罗斯大,整体属于高位。
先看看美国各州、各郡县的失业情况。
# 读取数据
us_unemp_county <- readRDS(file = "data/us_unemp_county.rds")
us_unemp_state <- readRDS(file = "data/us_unemp_state.rds")
# 绘图
ggplot() +
geom_sf(
data = us_unemp_state,
aes(fill = estimate / 10000), colour = NA
) +
scale_fill_viridis_c(option = "plasma", na.value = "grey80") +
coord_sf(crs = st_crs("ESRI:102003")) +
labs(
fill = "失业人口\n(万)",
title = "2016-2020 年度美国各州失业人口",
caption = "数据源:美国人口调查局"
) +
theme_void(base_size = 13) +
theme(
plot.title = element_text(hjust = 0.5),
legend.direction = "horizontal",
legend.position = "bottom",
legend.justification = "right",
legend.title = element_text(size = 10),
plot.caption = element_text(hjust = 0, vjust = 10)
)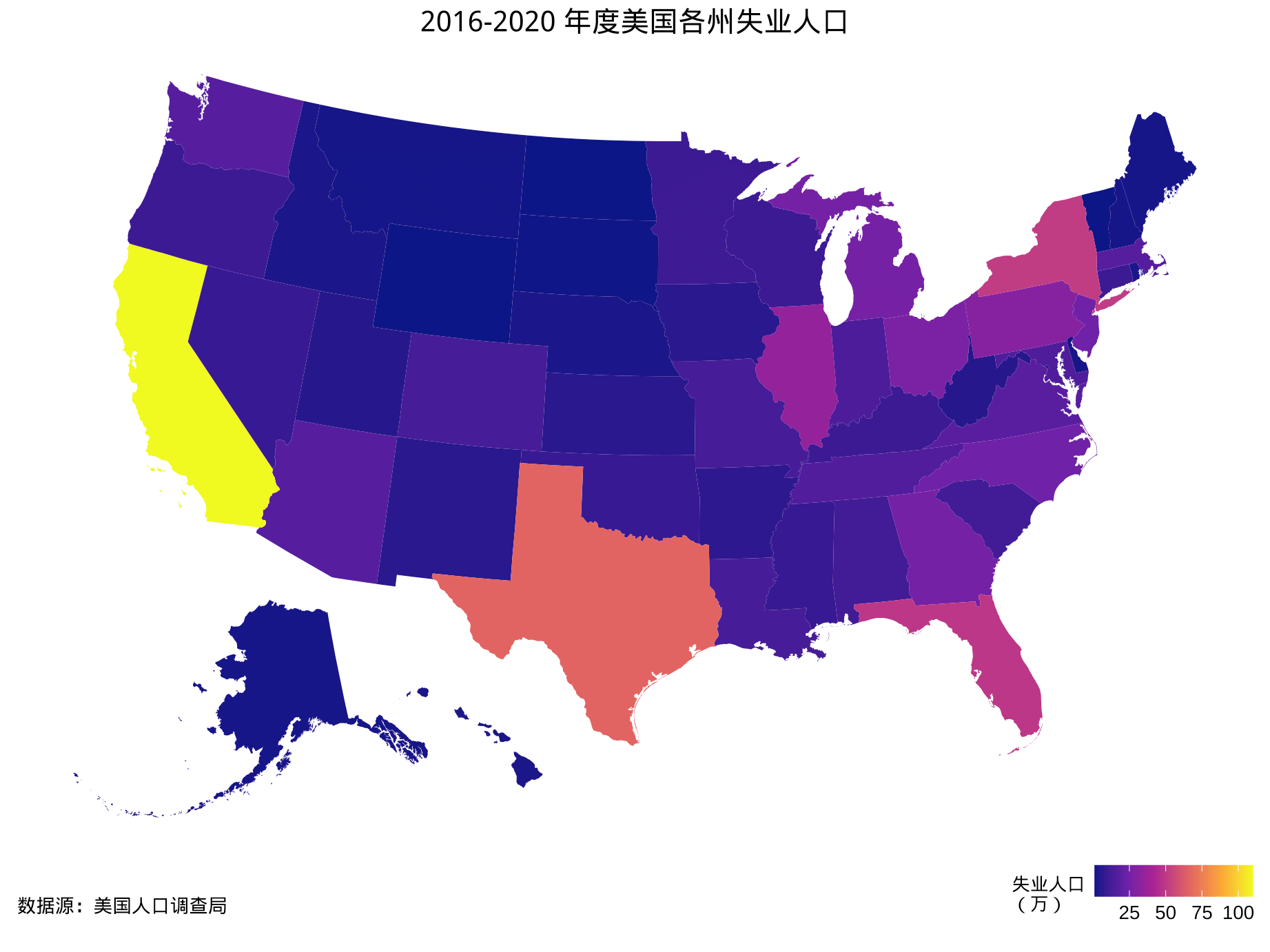
图 6.4: 2016-2020 年度美国各州失业人口
# 绘图
ggplot() +
geom_sf(
data = st_geometry(us_unemp_county), fill = "grey80", colour = NA
) +
geom_sf(
data = us_unemp_county[us_unemp_county$estimate > 0,],
aes(fill = estimate), colour = NA
) +
geom_sf(
data = us_unemp_state,
colour = alpha("gray80", 1 / 4), fill = NA, size = 0.15
) +
scale_fill_viridis_c(option = "plasma",
na.value = "grey80", trans = "log10") +
coord_sf(crs = st_crs("ESRI:102003")) +
labs(
fill = "失业人口\n",
title = "2016-2020 年度美国各郡县失业人口",
caption = "数据源:美国人口调查局"
) +
theme_void(base_size = 13) +
theme(
plot.title = element_text(hjust = 0.5),
legend.direction = "horizontal",
legend.position = "bottom",
legend.justification = "right",
legend.title = element_text(size = 10),
plot.caption = element_text(hjust = 0, vjust = 10)
)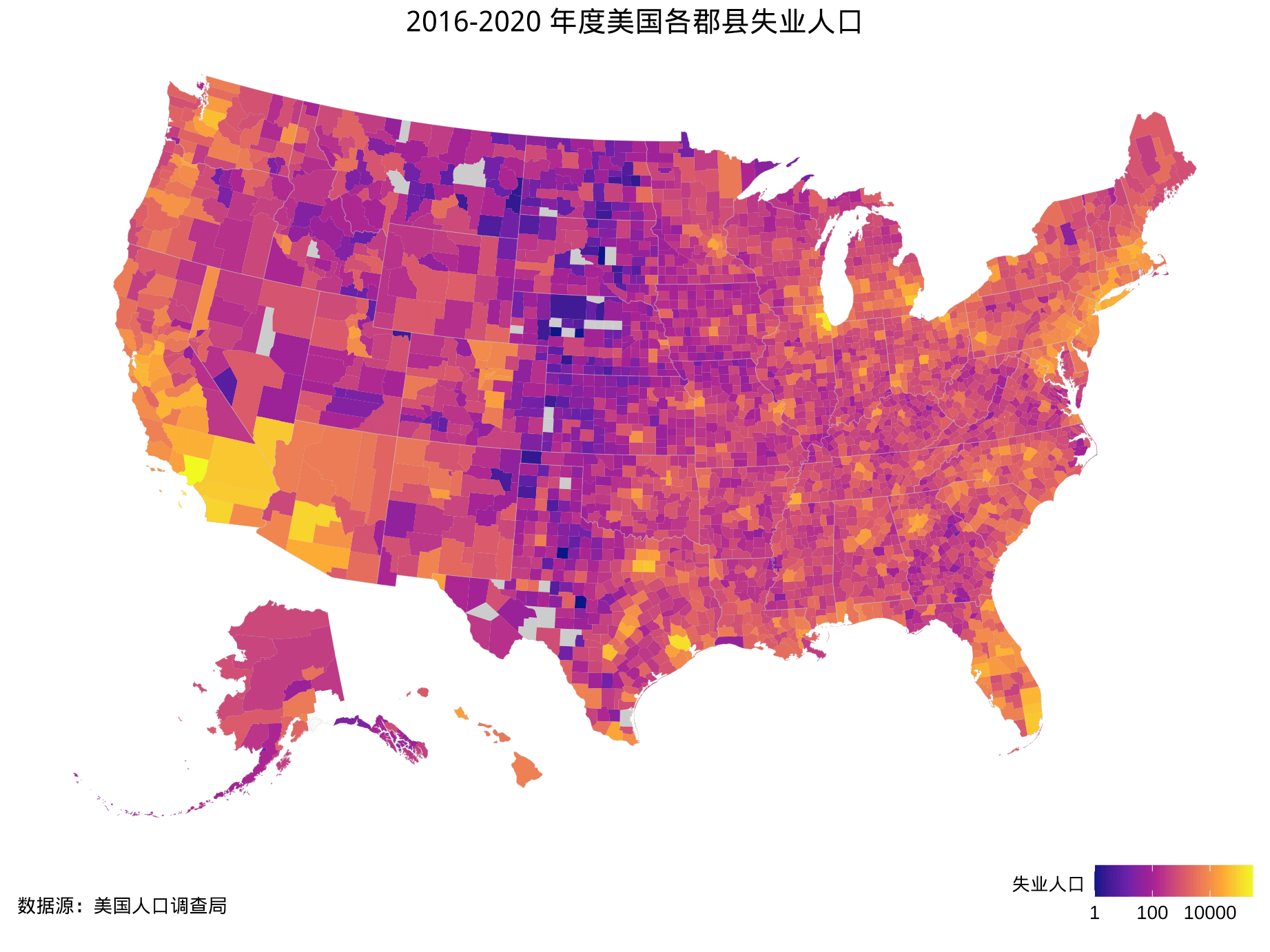
图 6.5: 2015-2020 年度美国各郡县失业人口
再以北卡州为例,看看各郡、各社区的失业情况。
nc_unemployed_county <- readRDS(file = "data/nc_unemployed_county.RDS")
ggplot(data = nc_unemployed_county) +
geom_sf(aes(fill = B27011_008E), color = NA) +
scale_fill_viridis_c(option = "C") +
theme_void()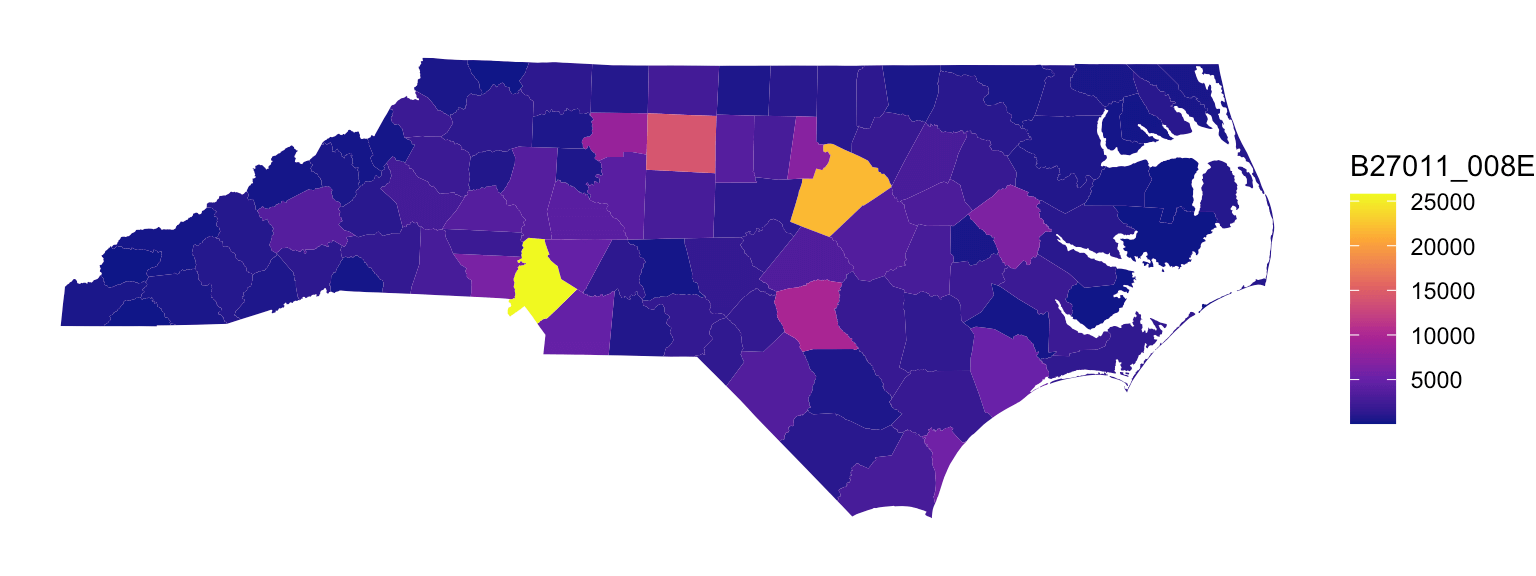
图 6.6: 北卡州各郡县失业率
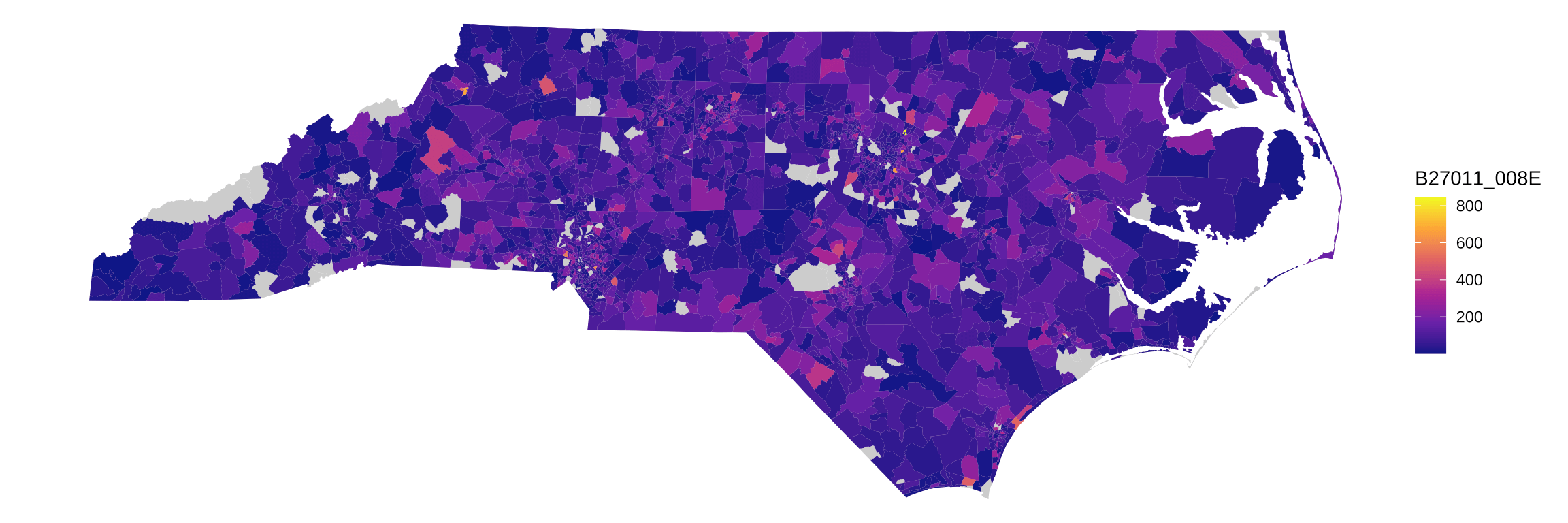
图 6.7: 北卡州各社区失业率
还有很多问题可以深入探索,比如根据美国历史至今的失业率变化情况,可否从中得到一些启示?美国人口调查局采用的失业率口径是什么?对失业率数据,采用空间区域平滑描述时空趋势变化。失业率居高不下,带来的连锁反应有哪些?继续以纽约、旧金山为例,犯罪率是否上升?CPI 是否上涨?利率是否变化?
7 参考文献
8 环境信息
在 RStudio IDE 内编辑本文的 R Markdown 源文件[30],用 blogdown [31]构建网站,Hugo 渲染 knitr 之后的 Markdown 文件,得益于 blogdown 对 R Markdown 格式的支持,图、表和参考文献的交叉引用非常方便,省了不少文字编辑功夫。文中使用了多个 R 包,为方便复现本文内容,下面列出详细的环境信息:
xfun::session_info(packages = c(
"knitr", "rmarkdown", "blogdown",
"maps", "mapproj", "lattice", "latticeExtra",
"sf", "tidycensus", "tigris", "showtext",
"ggplot2", "RSQLite", "wbstats"
), dependencies = FALSE)
# R version 4.2.2 (2022-10-31)
# Platform: x86_64-apple-darwin17.0 (64-bit)
# Running under: macOS Big Sur ... 10.16
#
# Locale: en_US.UTF-8 / en_US.UTF-8 / en_US.UTF-8 / C / en_US.UTF-8 / en_US.UTF-8
#
# Package version:
# blogdown_1.15 ggplot2_3.4.0 knitr_1.41
# lattice_0.20-45 latticeExtra_0.6-30 mapproj_1.2.9
# maps_3.4.1 rmarkdown_2.18 RSQLite_2.2.19
# sf_1.0-9 showtext_0.9-5 tidycensus_1.2.3
# tigris_2.0 wbstats_1.0.4
#
# Pandoc version: 2.19.2
#
# Hugo version: 0.108.0