首先,用 rvest 和 xml2 包抓取豆瓣电影 Top 250 排行榜数据,借此入坑网页抓取,实现基本的网页数据自由。接着,简单分析一下热门电影的时间分布,了解一点趋势。然后,用 reactable 包制作表格,展示排行榜数据。最后,简单谈谈 R 语言社区制作表格的一些 R 包。
1 抓取数据
首先加载两个 R 包 rvest 和 xml2,它们都是用来抓取和清洗网页数据的。
library(rvest)
library(xml2)以排行榜的首页为例,抓取一个页面。
# 下载页面
dat <- read_html("https://movie.douban.com/top250?start=0&filter=")
# 查看数据
dat## {html_document}
## <html lang="zh-CN" class="">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=utf-8 ...
## [2] <body>\n \n <script type="text/javascript">var _body_start = new Date ...这是一个常规的 HTML 网页文档,数据藏在一层层的 HTML 标签里,比如 <ol>和</ol>是一对,<li>和</li>是一对,<span> 和 </span> 又是一对。
tmp <- dat |>
html_elements("ol") |>
html_elements("li")
tmp## {xml_nodeset (25)}
## [1] <li>\n <div class="item">\n <div class="pic">\ ...
## [2] <li>\n <div class="item">\n <div class="pic">\ ...
## [3] <li>\n <div class="item">\n <div class="pic">\ ...
## [4] <li>\n <div class="item">\n <div class="pic">\ ...
## [5] <li>\n <div class="item">\n <div class="pic">\ ...
## [6] <li>\n <div class="item">\n <div class="pic">\ ...
## [7] <li>\n <div class="item">\n <div class="pic">\ ...
## [8] <li>\n <div class="item">\n <div class="pic">\ ...
## [9] <li>\n <div class="item">\n <div class="pic">\ ...
## [10] <li>\n <div class="item">\n <div class="pic">\ ...
## [11] <li>\n <div class="item">\n <div class="pic">\ ...
## [12] <li>\n <div class="item">\n <div class="pic">\ ...
## [13] <li>\n <div class="item">\n <div class="pic">\ ...
## [14] <li>\n <div class="item">\n <div class="pic">\ ...
## [15] <li>\n <div class="item">\n <div class="pic">\ ...
## [16] <li>\n <div class="item">\n <div class="pic">\ ...
## [17] <li>\n <div class="item">\n <div class="pic">\ ...
## [18] <li>\n <div class="item">\n <div class="pic">\ ...
## [19] <li>\n <div class="item">\n <div class="pic">\ ...
## [20] <li>\n <div class="item">\n <div class="pic">\ ...
## ...我们需要的数据藏得比较深,比如电影排名,函数 html_elements() 可以根据用户指定的 CSS 或 XPath 提取对应的数据,而函数 html_text() 可以将数据转为普通的字符串数据。更多介绍见2017年统计之都发的文章数据通灵术之爬虫技巧。有一些最基础的 CSS / HTML 和正则表达式知识即可,再借助谷歌浏览器的开发者工具,快速查找数据所在的 HTML 标签位置。这样,即使复杂如安居客房价网的网页也是可以类似搞定的。
# 电影排名 movie_rank
tmp[1] |>
html_elements("div.pic em") |>
html_text()## [1] "1"但是,规律是一致的,找到一个数据就能找到另一个,比如电影豆瓣链接。
# 电影豆瓣链接 movie_link
tmp[1] |>
html_elements("div.pic a") |>
html_attr("href")## [1] "https://movie.douban.com/subject/1292052/"电影海报是一张图片,需要将图片链接返回。
# 电影海报 movie_poster
tmp[1] |>
html_elements("div.pic a") |>
html_elements("img") |>
html_attr("src")## [1] "https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg"提取电影名称,电影名称有好几个,中文名、英文名和港台名,提取后放在一起。
# 电影名称 movie_title
tmp[1] |>
html_elements("div.hd a span") |>
html_text() |>
paste(collapse = "")## [1] "肖申克的救赎 / The Shawshank Redemption / 月黑高飞(港) / 刺激1995(台)"这个字段里的东西塞得太多了。
# 导演、主演、年份、类型 movie_extra
tmp[1] |>
html_elements("div.bd") |>
xml_find_all('.//p[@class=""]') |>
html_text()## [1] "\n 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...\n 1994 / 美国 / 犯罪 剧情\n "将豆瓣评分数据提取出来。
# 豆瓣评分 movie_rating
tmp[1] |> html_elements("div.bd .star .rating_num") |>
html_text()## [1] "9.7"将包含「人评价」的字符串过滤出来,其它的都不需要。
# 评价人数 movie_comments
tmp[1] |> html_elements(css = "div.bd .star span") |>
html_text() |>
grep(pattern = "人评价", value = TRUE)## [1] "2860862人评价"通过观察,了解到豆瓣排行榜的列表页的链接规律,每页显示 25 部电影,一共有 10 页,如下构造 250 部电影在 10 个页面的链接。
douban_movie_top250_links <- sprintf("https://movie.douban.com/top250?start=%s&filter=", 25*0:9)最后,将上面发现的规律应用于所有页面的爬取。
scrape_movie_info <- function(douban_movie_link) {
douban_movie_page <- read_html(douban_movie_link) |>
html_elements("ol") |>
html_elements("li")
douban_movie <- vector(length = 25, mode = "list")
# 每一个页面对应 25 部电影
for (i in 1:25) {
douban_movie[[i]] <- data.frame(
# 电影排名
rank = douban_movie_page[i] |>
html_elements("div.pic em") |>
html_text(),
# 电影名字
title = douban_movie_page[i] |>
html_elements("div.hd a span") |>
html_text() |>
paste(collapse = ""),
# 电影海报
poster = douban_movie_page[i] |>
html_elements("div.pic a") |>
html_elements("img") |>
html_attr("src"),
# 电影链接
link = douban_movie_page[i] |>
html_elements("div.pic a") |>
html_attr("href"),
# 导演、主演、年份、类型
extra = douban_movie_page[i] |>
html_elements("div.bd") |>
xml_find_all('.//p[@class=""]') |>
html_text(),
# 电影评分
rating = douban_movie_page[i] |>
html_elements("div.bd .star .rating_num") |>
html_text(),
# 电影评价人数
comments = douban_movie_page[i] |>
html_elements(css = "div.bd .star span") |>
html_text() |>
grep(pattern = "人评价", value = TRUE)
)
}
# 返回页面上的电影
do.call("rbind.data.frame", douban_movie)
}豆瓣排行榜 Top250 部电影分 10 页,一页一页地爬取,每爬一页,休息一下,太过频繁,容易给服务器造成压力,那就离封杀屏蔽不远了,做个有道德水准的爬虫。
# 250 部电影分 10 页
douban_movie_pages <- vector(length = 10, mode = "list")
# 一页一页地爬取
for (i in 1:10) {
douban_movie_pages[[i]] <- scrape_movie_info(douban_movie_link = douban_movie_top250_links[i])
# 缓一缓
Sys.sleep(5)
}将每一页数据合并成一个大的数据框 data.frame。
douban_movie_top250 <- do.call("rbind.data.frame", douban_movie_pages)2 清洗数据
电影排名、豆瓣链接、电影海报和电影名称都是现成的,不需要进一步清洗,下面 extra 字段不是很结构化,藏的信息太多,如导演、主演、年份、国家、类型等。本文初涉网页抓取,只简单清理一下,以后有时间做深入分析可能会接着清洗。
# 清洗电影额外信息
douban_movie_top250$extra <- trimws(gsub(x = douban_movie_top250$extra, pattern = "\n", replacement = ""))经过观察,年份信息藏在 extra 字段中,需要根据年份的特点抽取出来。年份就是四个挨着的数字,用正则表达式表示就是 \d{4},是不是很简单?
# 过滤年份
str_extract <- function(text, pattern, ...) regmatches(text, regexpr(pattern, text, ...))
# 提取上映年份
douban_movie_top250$year <- str_extract(text = douban_movie_top250$extra, pattern = "(\\d{4})")将字符串 "2679088人评价" 中的数字提取出来,很简单,去掉「人评价」三个字,留下数字。
# 清洗评价人数
douban_movie_top250$comments <- gsub(x = douban_movie_top250$comments, pattern = "人评价", replacement = "")
douban_movie_top250$comments <- as.integer(douban_movie_top250$comments)豆瓣评分其实是一个评级,一共 10 级,最小跨度是 0.1 级。所以,可以当作有序的分类变量,或者数值型变量,或者简单点,保持原始字符类型。
# 豆瓣评分
# douban_movie_top250$rating <- as.numeric(douban_movie_top250$rating)最后,保存清洗完的数据,方便后续探索和展示。
saveRDS(douban_movie_top250, file = "data/douban_movie_top250.rds")3 数据探索
使用 ggplot2 绘制一幅气泡图,横轴为豆瓣评分,纵轴为上映年份,评价人数映射给气泡大小和颜色,如图3.1所示,相当直观地展示这组原始数据。
library(ggplot2)
douban_movie_top250 <- readRDS(file = "data/douban_movie_top250.rds")
ggplot(data = douban_movie_top250, aes(x = rating, y = year)) +
geom_point(aes(size = comments, color = comments),
show.legend = c("size" = FALSE, "color" = TRUE),
alpha = 0.5
) +
scale_color_binned(
type = scale_color_viridis_b, option = "C",
labels = scales::label_number(scale_cut = scales::cut_short_scale())
) +
theme_classic() +
theme(panel.grid.major.y = element_line(colour = "gray95")) +
labs(
x = "豆瓣评分", y = "上映年份", title = "豆瓣电影 Top 250",
color = "评价人数", caption = "数据源:豆瓣电影"
)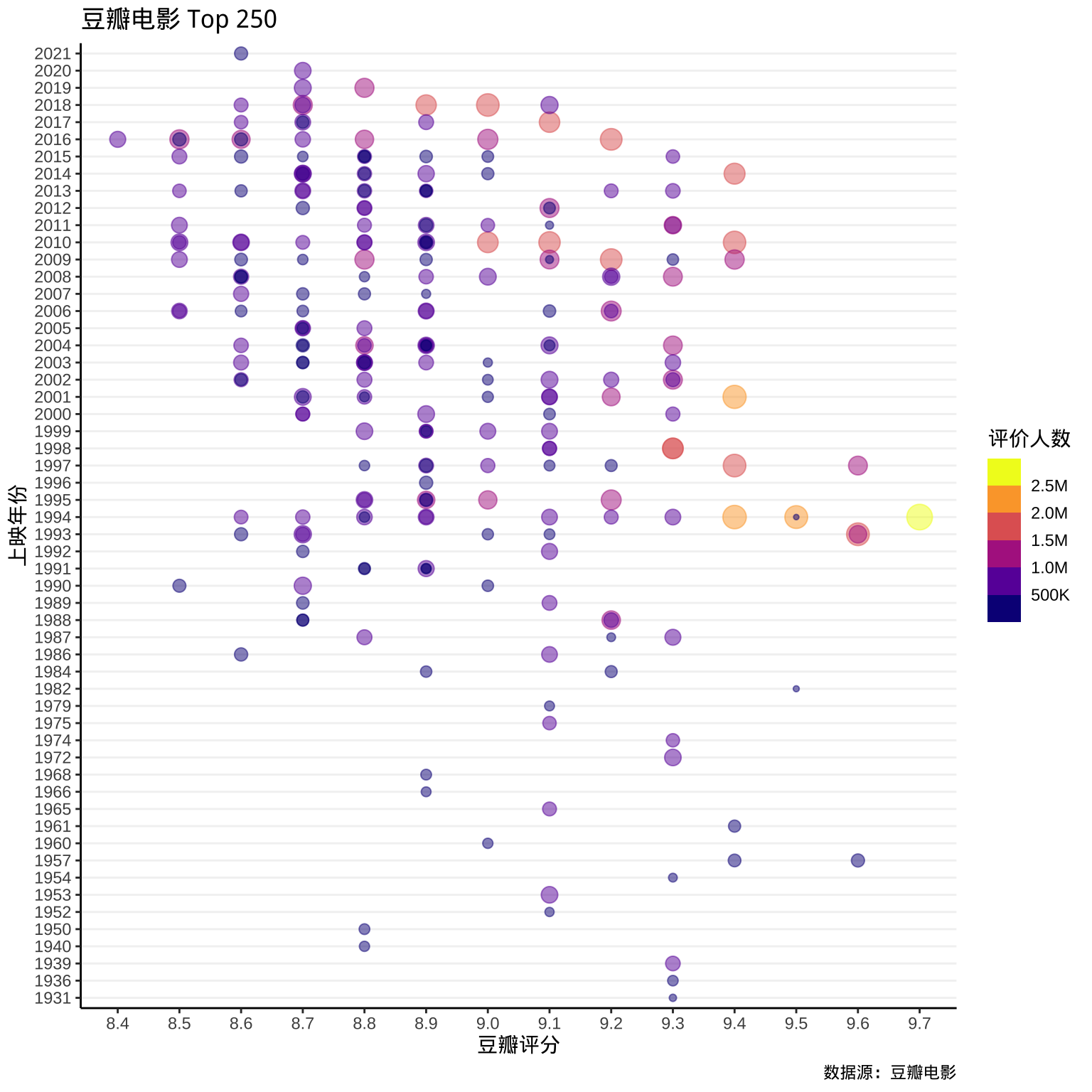
图 3.1: 豆瓣电影排行榜 Top250
意料之外的是随着电影数量增加好电影并没有像数量一样增加,而且最热门的电影竟然来自 1994 年的《肖申克的救赎》?大大出乎我的预料,尽管我知道它很有名, 但是我不知道它竟然如此有名,超过了《美国往事》、《教父》三部曲、《海上钢琴师》、《当幸福来敲门》等等。
绘制此散点图,虽然有重叠的点,但不能使用抖动手法,不管是对纵向时间还是横向评分,一旦抖动就造成理解困难,甚至可以说是带来了错误。 评分是 0.1 为一级,年份抖动极可能抖到其他年份去了,所以只能设置透明度缓解。也不宜设置名称标注,不像国家名称,电影名一般比较长,标注的覆盖会严重影响数据的展示。
4 数据展示
使用表格 reactable (Lin 2022) 展示豆瓣电影排行版数据,相比于原网页,只留下了必要的关键信息。
library(reactable)
## 汉化表格
options(reactable.language = reactableLang(
pageSizeOptions = "\u663e\u793a {rows}",
pageInfo = "{rowStart} \u81f3 {rowEnd} \u9879\u7ed3\u679c,\u5171 {rows} \u9879",
pagePrevious = "\u4e0a\u9875",
pageNext = "\u4e0b\u9875"
))没有什么花巧计谋,稳扎稳打,根据reactable包的帮助文档,简简单单展示关键信息,方便以后取用即可。
subset(douban_movie_top250,
select = setdiff(colnames(douban_movie_top250), c("link", "poster"))
) |>
reactable(
striped = TRUE, # 隔行高亮
searchable = TRUE, # 支持搜索
columns = list(
rank = colDef(name = "豆瓣排名", align = "center"),
title = colDef(name = "电影名称", minWidth = 250,
cell = function(value, index) { # 电影名加超链接
htmltools::tags$a(href = douban_movie_top250[index, "link"], target = "_blank", value)
}),
extra = colDef(name = "其它信息", minWidth = 450),
rating = colDef(name = "豆瓣评分", align = "center"),
comments = colDef(name = "评价人数"),
year = colDef(name = "上映年份", align = "center")
)
)留了搜索的窗口,方便根据演员或导演来找电影,试试搜索「张国荣」或「斯皮尔伯格」。大致扫了几眼,好多电影都没看过,以后有时间了慢慢刷吧,顺便写点影评什么的。那么多好看的电影还没来得及看呢,一想到这,现在快餐式的电影就没啥意思了。
5 表格概览
除了交互式网页图形可以展示数据,交互式表格作为一种数据展示的重要补充,准确刻画数据本身,相信它诞生的历史一定比图形早。作为数据分析和可视化领域的佼佼者,R 语言社区提供了大量制作表格的扩展包,支持导出各种各样的格式,如 Word、 LaTeX、Markdown 和 HTML 等。
制作 HTML 静态网页表格,可以用 gt、gtExtras和gtsummary 包(Sjoberg et al. 2021),针对模型输出,可以用 modelsummary 包。适合用于公司、部门指标大盘,不需要有太多探索分析和交互,只需要将核心指标及其达成情况汇总展示。
制作交互式网页表格,可以用reactable 包和reactablefmtr包,适合一些数据产品的开发,需要一定的探索分析和交互应用。比如 Georgios Karamanis 使用 reactable 包复现 2022 年 Axios Harris Poll 100 民意调查结果,关于此调查的更多背景见网址。
| R 包 | 描述 |
|---|---|
| knitr1 | A General-Purpose Package for Dynamic Report Generation in R |
| kableExtra | Construct Complex Table with kable and Pipe Syntax |
| gt | Easily Create Presentation-Ready Display Tables |
| gtExtras | A Collection of Helper Functions for the gt Package |
| gtsummary | Presentation-Ready Data Summary and Analytic Result Tables |
| reactable | Interactive Data Tables Based on React Table |
| reactablefmtr | Easily Customize Interactive Tables Made with Reactable |
| flextable | Functions for Tabular Reporting |
| ftExtra | Title: Extensions for Flextable |
| huxtable | Easily Create and Style Tables for LaTeX, HTML and Other Formats |
| DT | A Wrapper of the JavaScript Library DataTables |
| formattable | Create Formattable Data Structures |
reactable 包站在巨人TanStack Table的肩膀上,TanStack Table 前身是 React Table,背靠鼎鼎大名的前端框架 React ,目前 reactable 包基于 React Table v7。 目前,reactable 包有好些常用的效率性的功能还未就绪,已知问题清单见此处。比如,不支持向量化的方式对多个列应用同样的格式化方法,即有 A、B、C 三个列需要以百分比的格式展示,使用 reactable 包需要写三段类似的代码,造成一定冗余。唯一的好处是在未来修改某个列,其它列相互不受影响。reactable 不支持像 DT 包那样导出数据,需要另外借助 Shiny 制作下载按钮。
6 环境信息
本文是在 RStudio IDE 内用 R Markdown 编辑的,用 blogdown 构建网站,Hugo 渲染 knitr 之后的 Markdown 文件,得益于 blogdown 对 R Markdown 格式的支持,图、表和参考文献的交叉引用非常方便,省了不少文字编辑功夫。文中使用了多个 R 包,为方便复现本文内容,下面列出详细的环境信息:
xfun::session_info(packages = c(
"knitr", "rmarkdown", "blogdown",
"reactable", "xml2", "rvest", "ggplot2", "showtext"
), dependencies = FALSE)## R version 4.3.0 (2023-04-21)
## Platform: x86_64-apple-darwin22.4.0 (64-bit)
## Running under: macOS Ventura 13.4
##
##
## Locale: en_US.UTF-8 / en_US.UTF-8 / en_US.UTF-8 / C / en_US.UTF-8 / en_US.UTF-8
##
## time zone: Asia/Shanghai
## tzcode source: internal
##
## Package version:
## blogdown_1.17 ggplot2_3.4.2 knitr_1.43 reactable_0.4.4
## rmarkdown_2.21 rvest_1.0.3 showtext_0.9-6 xml2_1.3.4
##
## Pandoc version: 2.19.2
##
## Hugo version: 0.112.57 参考文献
knitr 包的
kable()函数可以制作表格。↩︎