本文引用的所有信息均为公开信息,仅代表作者本人观点,与就职单位无关。
本文将先回顾 2000 年以来 R 语言社区在做数据产品、工具、应用的一些历史;接着简要介绍《2021 年 Gartner 分析和商业智能平台魔力象限》,国内外商业智能分析领域出现的系列产品以及未来趋势;然后介绍 Web 开发框架 — Shiny 生态以及一些典型作品;再介绍制作一款数据产品可能涉及到的方方面面,包括技术的、非技术的,以及一些个人思考,不一定对,仅供参考,笔者也会随着时间迭代。
1 回顾历史
从 tcltk (Lawrence and Verzani 2012) 到 RGtk2 (Lawrence and Temple Lang 2010),再到 shiny(Chang et al. 2021),自 2001 年 Peter Dalgaard 在《R News》介绍 tcltk (Dalgaard 2001) 算起,整整 20 年过去了, 打造数据产品的主力工具换了一茬又一茬,过程中出现了一些优秀的代表作品,基于 tcltk 的 Rcmdr (Fox 2005)(2003 年首发),基于 rJava 的 JGR(Helbig, Theus, and Urbanek 2005)(2006 年首发),基于 RGtk2 的 rattle (Williams 2011)(2013 年首发),基于 shiny 的 radiant (Nijs 2021)(2015 年首发),风水轮流转,十年一轮回。除了 Shiny 应用,其它都有很重的系统软件依赖,在不同系统上的安装过程复杂不一,为开发应用的学习成本比较高,我想主要还是受历史局限,2003 年,国内有笔记本电脑的怕是也屈指可数,浏览器和网页技术远没有现在这么流行。不过,现在回过头再去看,不免惊叹于当时的想法是多么超前!
1.1 Rcmdr
Rcmdr 包主要由 John Fox 开发,在 R 软件工作空间中加载后,会出现如图1.1所示的图形用户界面,它是基于 R 内置的 tcltk 包开发的。顾名思义,tcltk 是 Tcl (Tool Command Language) 和 Tk (Graphical User Interface Toolkit) 的合体。

图 1.1: Rcmdr 包:统计分析与 tcltk 应用
Rcmdr 具有非常多的统计功能,还有很多开发者帮助建设周边,目前 CRAN 上扩展插件包就有 42 个,也曾号称是 IBM SPSS 的开源替代品。
[1] "RcmdrPlugin.aRnova" "RcmdrPlugin.BiclustGUI"
[3] "RcmdrPlugin.BWS1" "RcmdrPlugin.BWS2"
[5] "RcmdrPlugin.coin" "RcmdrPlugin.DCCV"
[7] "RcmdrPlugin.DCE" "RcmdrPlugin.depthTools"
[9] "RcmdrPlugin.DoE" "RcmdrPlugin.EBM"
[11] "RcmdrPlugin.EcoVirtual" "RcmdrPlugin.Export"
[13] "RcmdrPlugin.EZR" "RcmdrPlugin.FactoMineR"
[15] "RcmdrPlugin.GWRM" "RcmdrPlugin.HH"
[17] "RcmdrPlugin.IPSUR" "RcmdrPlugin.KMggplot2"
[19] "RcmdrPlugin.MA" "RcmdrPlugin.MPAStats"
[21] "RcmdrPlugin.NMBU" "RcmdrPlugin.orloca"
[23] "RcmdrPlugin.PcaRobust" "RcmdrPlugin.RiskDemo"
[25] "RcmdrPlugin.RMTCJags" "RcmdrPlugin.ROC"
[27] "RcmdrPlugin.SCDA" "RcmdrPlugin.sos"
[29] "RcmdrPlugin.survival" "RcmdrPlugin.sutteForecastR"
[31] "RcmdrPlugin.TeachingDemos" "RcmdrPlugin.TeachStat"
[33] "RcmdrPlugin.temis" "RcmdrPlugin.UCA"
[35] "RcmdrPlugin.WorldFlora" 1.2 JGR
JGR1 (Java Gui for R) 主要由 Markus Helbig 开发,它非常小巧,但是提供了大部分常用的数据操作、探索和统计分析功能,如单样本、两样本和 K 样本检验,相关性分析、列联分析、线性和广义线性模型等。在那个年代以如此迅速的手法集成 R 语言和学术界的成果是非常厉害的,也不怪乎它敢对标 SPSS、 JMP 和 Minitab 等商业统计分析软件。

图 1.2: JGR 包:统计分析与 rJava 应用
1.3 rattle
rattle 包主要由 Graham J. Williams 基于 RGtk2 开发。RGtk2 类似 tcltk 包2,它是另一个跨平台开源框架GTK的 R 语言接口,面向数据挖掘工作者。因此,集成了大量常见的算法模型,如关联规则、随机森林、支撑向量机、决策树、聚类分析、因子分析、生存分析、时序分析等。支持连接数据库,做数据变换和数据可视化等探索分析,用户在图形用户界面1.3上的操作都会被记录下来,生成对应的 R 语言代码,方便后续修改和脚本化。

图 1.3: rattle 包:数据挖掘与 Gtk+ 应用
期间,还陆续出现了一些开源统计分析软件,比如 GNU PSPP、jamovi 和 JASP,都提供图形化的用户界面,也都号称是 SPSS 软件 的免费替代,但是从来没有真的替代过。专门化的贝叶斯分析软件有 JAGS 和 Stan 等,而商业化的典型统计软件,还有 SAS,最近它开始筹备上市了,其它专门化的软件更是可以列出一个长长的单子,此处略去。下面仅就 JASP 简单介绍,JASP 是一款独立免费开源的统计软件,不是一个 R 包,源代码托管在 Github 上,主要由阿姆斯特丹大学 E. J. Wagenmakers 教授领导的团队维护开发,实现了很多贝叶斯和频率统计方法,具体功能见这里,统计方法和原理见博客,相似的图形用户界面使得 JASP 可以作为 SPSS 的替代,也远非前面的 JGR 可比。
| Analysis | Frequentist | Bayesian |
|---|---|---|
| A/B Test(A/B 测试) | – | ✓ |
| ANOVA(方差分析) | ✓ | ✓ |
| ANCOVA(协方差分析) | ✓ | ✓ |
| AUDIT (module) | ✓ | ✓ |
| Bain (module) | – | ✓ |
| Binomial Test(二项检验) | ✓ | ✓ |
| Confirmatory Factor Analysis (CFA) | ✓ | – |
| Contingency Tables(列联分析,又叫卡方检验) | ✓ | ✓ |
| Correlation: Pearson, Spearman, Kendall(相关性检验) | ✓ | ✓ |
| Distributions (module)(统计分布) | ✓ | ✓ |
| Equivalence T-Tests: Independent, Paired, One-Sample (module)3 | ✓ | ✓ |
| Exploratory Factor Analysis (EFA)(探索因子分析) | ✓ | – |
| Generalized Linear Mixed Models(广义线性混合效应模型) | ✓ | ✓ |
| JAGS (module)(贝叶斯软件 JAGS) | – | ✓ |
| Learn Bayes (module)(贝叶斯学习) | – | ✓ |
| Linear Mixed Models(线性混合效应模型) | ✓ | ✓ |
| Linear Regression(线性回归) | ✓ | ✓ |
| Logistic Regression (逻辑回归) | ✓ | – |
| Log-Linear Regression(对数线性回归) | ✓ | ✓ |
| Machine Learning (module)(机器学习) | ✓ | – |
| MANOVA(多元单因素方差分析) | ✓ | – |
| Mediation Analysis(中介分析)4 | ✓ | – |
| Meta-Analysis (module)(元分析) | ✓ | ✓ |
| Multinomial (多项回归) | ✓ | ✓ |
| Network (module) (网络分析) | ✓ | – |
| Principal Component Analysis (主成分分析) | ✓ | – |
| Prophet (module)(贝叶斯时间序列分析) | – | ✓ |
| Repeated Measures ANOVA(重复测量方差分析) | ✓ | ✓ |
| Reliability (module)(可靠性) | ✓ | ✓ |
| Structural Equation Modeling (module) (结构方程模型) | ✓ | – |
| Summary Statistics (module)(描述统计) | – | ✓ |
| T-Tests: Independent, Paired, One-Sample (T 检验) | ✓ | ✓ |
| Visual Modeling: Linear, Mixed, Generalized Linear (module) | ✓ | – |
1.4 Shiny
R Shiny 框架
shiny 是 2012 年正式登陆 R 语言官方仓库 CRAN (Comprehensive R Archive Network)的,在 2015 年以后才开始形成生产力,经过最近几年的快速发展,截止当前,直接或间接依赖 shiny 的 R 包已有近 1000 个5,还不算 Bioconductor 上发布的,实际上还有很多存放在 Github 上。类似 Rcmdr,shiny 也有很多插件包,提供一些附加功能,比如交互反馈 shinyFeedback、主题配色 shinythemes、输入校验 shinyvalidate、筛选器样式 shinyWidgets 等,下面列出部分:
[1] "shiny" "shiny.i18n" "shiny.info"
[4] "shiny.pwa" "shiny.react" "shiny.reglog"
[7] "shiny.router" "shiny.semantic" "shiny.worker"
[10] "shinyAce" "shinyaframe" "shinyalert"
[13] "shinyanimate" "shinyauthr" "shinybrms"
[16] "shinybrowser" "shinyBS" "shinybusy"
[19] "shinyChakraSlider" "shinyChakraUI" "shinyCohortBuilder"
[22] "shinycssloaders" "shinycustomloader" "shinyCyJS"
[25] "shinydashboard" "shinydashboardPlus" "shinydisconnect"
[28] "shinydlplot" "shinyDND" "shinydrive"
[31] "shinyEffects" "shinyFeedback" "shinyFiles"
[34] "shinyfilter" "shinyfullscreen" "shinyGizmo"
[37] "shinyglide" "shinyGovstyle" "shinyHeatmaply"
[40] "shinyhelper" "shinyhttr" "shinyIRT"
[43] "shinyjqui" "shinyjs" "shinyKGode"
[46] "shinyKnobs" "shinyloadtest" "shinylogs"
[49] "shinyLP" "shinymanager" "shinymaterial"
[52] "shinyMatrix" "shinyMergely" "shinymeta"
[55] "shinyML" "shinyMobile" "shinymodels"
[58] "shinyMolBio" "shinyMonacoEditor" "shinyNORRRM"
[61] "shinyNotes" "shinyobjects" "shinypanel"
[64] "shinypanels" "shinypivottabler" "shinyPredict"
[67] "shinyr" "shinyRadioMatrix" "shinyrecipes"
[70] "shinyreforms" "shinyRGL" "shinyscreenshot"
[73] "shinySearchbar" "shinySelect" "shinyservicebot"
[76] "shinyShortcut" "shinySIR" "shinystan"
[79] "shinysurveys" "shinyTempSignal" "shinytest"
[82] "shinytest2" "shinythemes" "shinyTime"
[85] "shinytitle" "shinyToastify" "shinytoastr"
[88] "shinyTree" "shinyvalidate" "shinyWidgets" 相比于之前介绍的 Rcmdr、JGR 和 rattle, shiny 扩展包没有系统软件依赖,甚至可以直接嵌入到网站博客里,如图1.4,这无论是对生态开发者还是应用开发者来说,都是非常友好的。另外,入门的学习成本非常低,应用的前后端代码可以纯用 R 语言实现。判断一个工具是否成熟,还可以看书写出得多不多,文档全不全,面对企业级大规模应用够不够稳定高效,好在 Wickham (2021) 亲自操刀写了《Mastering Shiny》,值得反复学习。
图 1.4: Shiny 应用
Shiny 是一个开发 Web 应用的框架,相当于前面提及的 tcltk,在它之上可以开发出各种各样的应用,在一些 R 服务框架 的帮助下,一些计算密集型的任务可以剥离开,打包成模型服务,供 Shiny 应用的服务端调用。
本文 Shiny 首字母大写的时候表示 Web 开发框架,否则表示 R 语言扩展包 shiny。
1.4.1 radiant
Vincent Nijs 在 2015 年开发了 radiant 应用,完全基于 R 语言和 Shiny 框架,定位商业分析,包含基础统计计算、实验设计分析、多元统计分析和常用数据挖掘模型等,算是相当早的具备一定规模和流行度的 Shiny 应用。

图 1.5: radiant 包:商业分析与 R Shiny 应用
1.4.2 shinybrms
顾名思义,shinybrms 是另一个 R 包 brms 的 Shiny 扩展,由 Frank Weber 开发,2020 年登陆 CRAN 仓库。它依赖贝叶斯计算框架 Stan 的 R 接口 rstan 包,预编译非常多的贝叶斯统计模型,比如线性模型、广义线性模型、线性混合效应模型、广义线性混合效应模型、广义可加混合效应模型等,站在 Shiny 的肩膀上,shinybrms 调用 Stan 编写的模型,实现模型计算、模型诊断、过程分析、模型评估和可视化,让贝叶斯数据分析过程在拖拉拽中完成。

图 1.6: shinybrms 包:贝叶斯分析与 R Shiny 应用


1.5 Shiny 周边
这个周边既有补充也有替代,既有 Shiny 生态内也有生态外。
都说现在是看脸的时代,自然少不了数据可视化组件,而且是易用、流畅、美观,总之一句话,体验要好。这些组件当中,有的能力比较综合,可以连接各类数据库,提供 SQL 编辑窗口,直接对取数结果可视化分析,比如 Apache Superset 是数据可视化(Data Visualization)和数据探索(Data Exploration)平台,同类产品还有Redash。有的专注数据可视化,比如Apache ECharts 是交互式网页绘图和数据可视化的库,同类产品还有 Plotly,它 提供各种各样的图形,涵盖统计、三维、科学、地理、金融等五大类。还有的面向特定的语言,比如bokeh 是一个交互式网页可视化的 Python 模块。还有的,如 Observable Plot 主打探索性数据可视化,像是 Jupyter Notebook 和 bokeh 的合体。而fastpages 是易于使用的博客平台,深度结合静态网站生成器Jekyll,有来自 Jupyter Notebook 的增强支持,可以让博客看起来是一个个的数据报告或仪表盘,以 COVID-19 为例,可以看出它是 blogdown + R Markdown + Netlify + Hugo + Pandoc 的合体。还有的,比如D3 采用 Web 标准的数据可视化库,支持 SVG、Canvas 和 HTML 渲染方式,是一个非常基础的 JavaScript 库,在许多项目中使用,比如做日志监控的Grafana。 作为新一代通用技术写作工具,Quarto 支持各类编程语言,Markdown、R Markdown 和 Jupyter Notebook 等主流文档格式,可以输出多种格式的文档,如动态网页 HTML、便携文档 PDF、移动优先的电子书籍 MOBI 和 EPUB 等。总之,无论技术如何更新换代,更加易用,更加便携,更加美观,更加通用的全能型选手必将引领潮流。
2021 年 Gartner 对分析和商业平台的定义是易于使用且能支撑全分析工作流 — 即从数据准备到可视化探索和洞察报告生成。魔力象限中的产品都具有数据可视化能力,可以接入各种各样的数据源,使用交互式图表搭建刻画关键指标的仪表盘,区别在于增强分析(Augmented Analytics)方面的支持程度 — 机器学习和人工智能技术在数据准备、洞察生成和解释等方面为决策者和分析师赋能提效的有多少,以及在帮助非技术序列的终端用户自助探索分析的有多少。简而言之,就是教机器给人讲好数据故事。从图1.9中不难看出,领先的都是国外老牌的 IT 企业,国内唯一入选的是阿里云,且评测中的 12 项能力全面弱于平均水平。图中横轴表示前瞻性,纵轴表示执行力,四个象限从右上到左下依次是领导者、挑战者、特定领域者(Niche Player)和有远见者。

图 1.9: 2021 年 Gartner 分析和商业智能平台魔力象限
数据科学涵盖的同样非常广泛,如dataiku所介绍,以及个人理解,涉及数据准备 Data Preparation,且无论是各类数据库连接操作,还是导入小数据文件 Excel 后探索。可视化 Visualization 在数据探索、分析以及在后续建模中都是不可或缺的。再者就是利用各类机器学习算法 Machine Learning 建模,包括对数据生成机制的推理和未来不确定性的预估、预测。无论数据分析还是建模都有赖于数据质量的保障,因此数据运维 DataOps 重要性不言而喻,涉及数据完整性、有效性、准确性、一致性、及时性、唯一性等方面,挑战不可谓小,详细解释见数据质量漫谈。机器学习的运维 MLOps 也不可小觑,模型版本迭代、数据特征监控、上下游乃至全链路的安全质量保障,比如熔断、降级、兜底等机制和能力建设。提及运维就不得不说分析型应用 Analytic Apps,针对模型上线后的效果监控,线上线下数据质量监控,各个链路环节的服务监控和分析。复杂的系统都是需要协作 Collaboration 的,协作的配合机制、团队的权责边界都需要每个成员清晰明了。管理和控制如此复杂的系统,模型、数据、代码的上、下线都是需要管控 Governance 的。如此复杂的系统工程,团队分工协作,如何归因和衡量效果 Explainability,让复杂简单化,让黑盒白盒化,特征重要性、相关性、因果性等做到可解释,同样是非常大的挑战。优化复杂的系统以获取整体性的收益,是需要架构优化 Architecture 的。综合起来,就是数据科学的十项关键能力:数据准备 Data Preparation、数据展示 Visualization、数据建模 Machine Learning、数据运维 DataOps、模型运维 MLOps、分析应用 Analytic Apps、团队协作 Collaboration、质量管控 Governance、解释能力 Explainability、平台架构 Architecture。
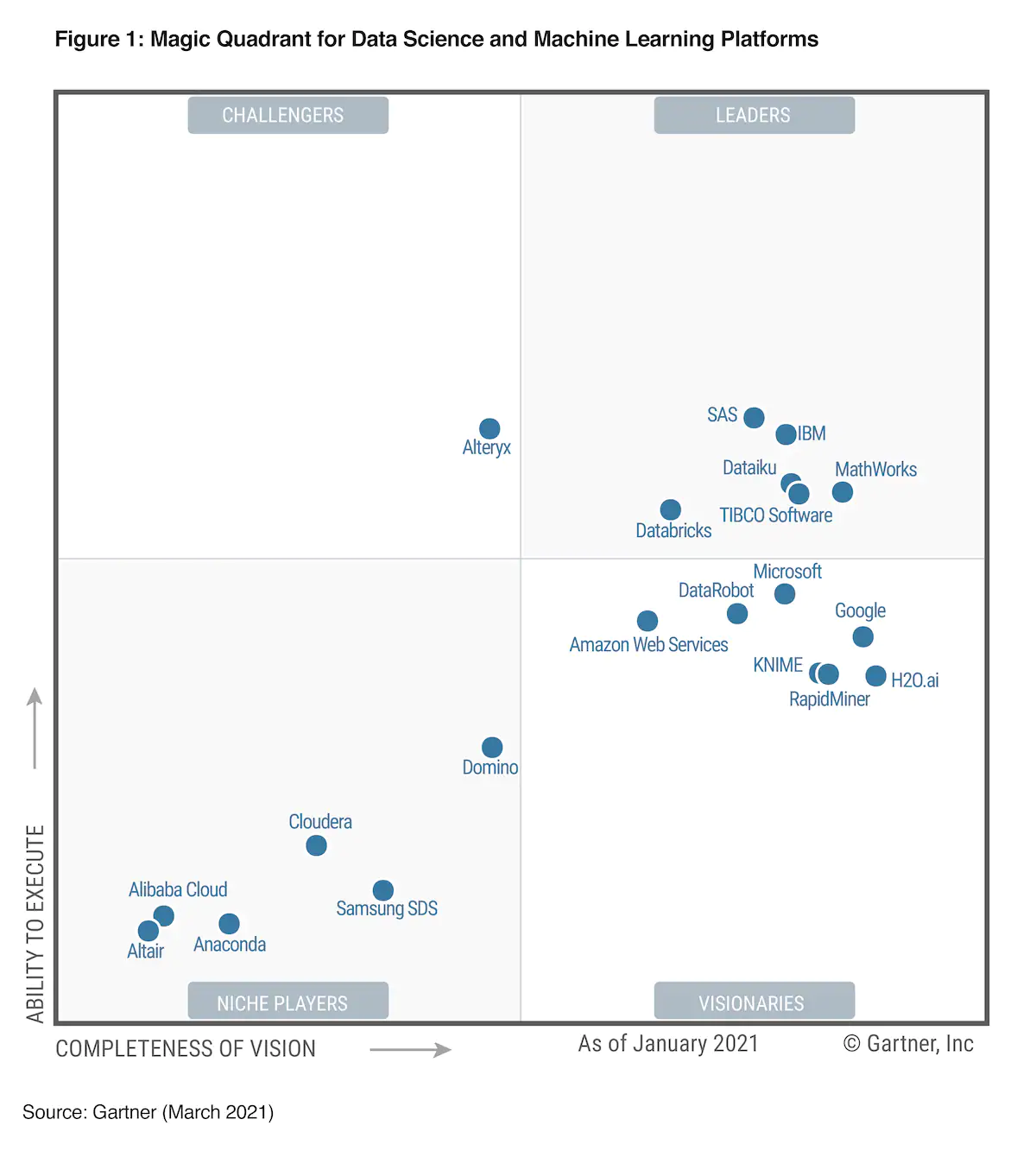
图 1.9: 2021 年 Gartner 数据科学与机器学习平台魔力象限
2018 年美团技术博客介绍了大规模的餐饮娱乐知识图谱—美团大脑,其前端展示层面就采用了业内通用的开源三维可视化库 three.js,夏华夏在 2020 国际智能城市峰会上做了美团大脑的具体演示6,《第一财经》新闻栏目也做了报道!
2 数据产品
2.1 产品开发
数据分析师/工程师日常需要搭建数据指标体系,制作数据报表看板,输出数据洞察和专项分析,行业供需分析,经营诊断分析和问题追踪归因。制作数据报表和看板是最常见的一种形式,这里,统一一下术语,都称作数据产品。制作一款数据产品,包含提出需求、PRD 评审、产品设计、前后端开发、数据开发、测试验收、最终上线等流程。能力比较全面的工程师,能够主动发现业务痛点,提出产品需求,完成产品设计,数据开发校验,产品开发,测试上线,收集反馈,迭代优化,形成闭环。小厂或者数据团队比较小的时候,需要的能力会比较全面,差别主要在粗放和精细化之间的程度不同。
技术方面,数据开发和产品开发耗时最多,非技术方面,找到好的问题就需要花费很多时间,涉及日积月累的业务理解,获取数据及探查建模,可大可小的跨团队协作交流,调研部门/公司内外现有产品工具,完成探索性数据分析,负责整个产品工具的设计和开发,及时向上沟通管理,把控整个项目的风险。既然是独立负责完整项目,项目管理自然也是非常关键的,最重要的是及时向上反馈,全流程的时间安排,不至于全程紧张或先松后紧或先紧后松的情况。这些都需要在实际工作中才能锻炼出来的,因此,多说事倍功半,数据开发和产品开发偏重技术,又可批量化、标准化地整理出来,继而做技术推广,可以迁移到读者对应的具体业务场景中去。
2.2 产品对标
做数据型产品是当前数据分析的一个方向,一般核心指标的大屏监控、可重复性的数据探索分析和OLAP(在线联机分析处理)产品等都可以合并到商业智能分析,具备一定的探索性、重复性和交互性的沉浸式。关键是找到有价值的业务场景,写好剧本(布局设计),做好道具(筛选器、图表)。即使没有任何说明,用户一进来看到分析主题(比如城市分析),产品就能给他所预期的东西,让用户能在里面玩上一天,不停地探索不停地获取输入。需求模块、供给模块,结合时间、空间精细划分,实现城市概览、城市对比、业务趋势、业务对比。典型的产品见下表,主要来自百度、阿里、腾讯、字节等大厂。
| 产品 | 能力 | 费用 | 场景 | 公司 |
|---|---|---|---|---|
| Sugar | 自助BI报表分析和制作可视化数据大屏 | 订阅费 3万/年起 | 大屏 | 百度 |
| DataV | 数据可视化应用搭建工具 | 订阅费 2.4万/年起 | 大屏 | 阿里 |
| RayData | 三维数据可视化编辑工具 | 预估数万/年起 | 大屏 | 腾讯 |
| DataWind | 数据分析、探索和洞察工具 | 预估数万/年起 | 报表 | 字节 |
| Quick BI | 数据分析、自助分析、数据报表平台 | 预估数万/年起 | 报表 | 阿里 |
| Apache Superset | 数据可视化和探索平台 | 免费 | 报表 | 开源 |
除了 Sugar 等三款商业解决方案,还有51WORLD等,除了 Apache Superset 也还有很多 OLAP 分析工具,比如redash等。商业智能分析 BI(Business Intelligence,BI)软件阿里 Quick BI、腾讯BI 围绕自助分析、即席分析和自主取数、数据分析和可视化等方面,当然大都支持数据库连接、数据权限管控、应用权限管控、高级定制分析。大屏产品,特别是ToC 的情况下,对前后端的开发要求很高,也会增加交互设计、视觉设计等环节,开发周期也会相对长很多。既是大屏应用,常出现于中控室,指挥中心等有独立/拼凑的大型电子显示屏的地方。一旦定型,一般也不会有太多的探索交互,大屏呈现的就是最重要的部分,主要负责实时监控,路演展示、市场宣传等。

图 2.1: 大屏数据可视化产品
事实上,Shiny 应用可以是统计分析软件,也可以是聚焦某一业务的核心报表,还可以承载特定分析场景的数据模型,还可以是大屏数据可视化监控,还可以是可交互可重复的分析报告。在专业的统计分析软件 R 语言的帮助下,它特别适用于做增强分析。
2.3 产品定位
在企业数据运营过程中,考虑使用场景、产品特点、实施角色以及可利用的工具,大致可以将数据运营需求分为四类,如下表所示,数据运营需求分类:
| 产品 | 应用场景 | 产品特点 | 实施角色 | 工具 |
|---|---|---|---|---|
| 分析报告 | 对模式不固定的数据进行探索、组织与解释,形成一次性数据分析报告并提供决策支持 | 基于人对数据的解读;需求发散 | 数据分析师、数据工程师 | Excel、SQL、R、Tableau 等 |
| 报表型产品 | 通过拖拽式或简单代码方式进行开发,对模式固定的数据组装和报表展现 | 开发效率高,开发门槛低;报表表达能力差 | 数据分析师 | 报表工具 |
| 定制式分析型产品 | 对固定模式的数据和分析方法,形成可重复式的数据分析产品并提供决策支持 | 开发效率较高,支持对数据的深度应用,开发过程可复用、可扩展,对有一定编程能力的开发者开发门槛较低;产品交互能力较弱 | 数据分析师、数据工程师 | Python、R、Tableau 等 |
| 定制式展示型产品 | 对固定模式的数据进行产品的高度定制,通过强化交互和用户体验,满足个性化的数据展示需求 | 展现样式丰富、交互能力强;仅适合有前端能力的开发者,开发效率较低,数据二次处理能力较差 | 前端工程师 | ECharts、Highcharts 等 |
2.4 技术思考
统计学最高奖项 COPSS 奖获得者 Hadley Wickham 在《R for Data Science》一书中描述了数据科学工作流。

图 2.2: 数据科学工作流
开发 Shiny 应用就是在对业务和数据的理解上,把探索发现的价值释放出来,和商业分析师、决策者,乃至运营、产品、一线人员交流,将价值落地在具体的业务场景上。
面对不同的数据量级,SQL 写法是不一样的,一般来说,数据量级越大,SQL 越复杂,SQL 函数的理解要求越深入,性能调优要求越高,处理 GB 级和 TB 级数据的 SQL 已经不是一个样子了。举个简单的例子,统计某个手机 App 一天的活跃用户和统计一年的活跃用户。为了能够让 R Shiny 应用轻快地跑起来,除了运维、系统等基础服务,应用层需要将数据处理逻辑尽可能下沉,数据处理归数据处理,数据可视化归数据可视化,前端交互归前端,后端模型归后端。
以搜索业务为例,搜索是连接用户需求和商户(还可以是商品、泛商品、一般知识、新闻等)供给的桥梁,无论是百度、谷歌这样的通用搜索,还是微博、头条这样的垂直搜索,每天用户输入的搜索词以及页面内各个部分曝光、点击带来的数据量都是非常可观的。
复杂性在于很多不同的数据情况需要考虑,带来很多判断逻辑,如何处理和组织这些判断逻辑是最难的事情,不能让复杂度膨胀,要控制维护成本,数据适应性强一点,代码灵活性高一点,而处理和组织判断逻辑需要对数据和业务有深入的了解。
3 环境信息
在 RStudio IDE 内编辑本文的 R Markdown 源文件,用 blogdown 构建网站,Hugo 渲染 knitr 之后的 Markdown 文件,得益于 blogdown 对 R Markdown 格式的支持,图、表和参考文献的交叉引用非常方便,省了不少文字编辑功夫。文中使用了多个 R 包,为方便复现本文内容,下面列出详细的环境信息:
xfun::session_info(packages = c(
"knitr", "rmarkdown", "blogdown"
))## R version 4.2.1 (2022-06-23)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur ... 10.16
##
## Locale: en_US.UTF-8 / en_US.UTF-8 / en_US.UTF-8 / C / en_US.UTF-8 / en_US.UTF-8
##
## Package version:
## base64enc_0.1.3 blogdown_1.10 bookdown_0.27 bslib_0.4.0
## cachem_1.0.6 digest_0.6.29 evaluate_0.15 fastmap_1.1.0
## fs_1.5.2 glue_1.6.2 graphics_4.2.1 grDevices_4.2.1
## highr_0.9 htmltools_0.5.3 httpuv_1.6.5 jquerylib_0.1.4
## jsonlite_1.8.0 knitr_1.39 later_1.3.0 magrittr_2.0.3
## memoise_2.0.1 methods_4.2.1 mime_0.12 promises_1.2.0.1
## R6_2.5.1 rappdirs_0.3.3 Rcpp_1.0.9 rlang_1.0.4
## rmarkdown_2.14 sass_0.4.2 servr_0.24 stats_4.2.1
## stringi_1.7.8 stringr_1.4.0 tinytex_0.40 tools_4.2.1
## utils_4.2.1 xfun_0.31 yaml_2.3.5
##
## Pandoc version: 2.18
##
## Hugo version: 0.101.04 参考文献
安装 JGR 包需要如下两步,其一安装 JDK 和配置 R 环境,让 R 软件能够识别到 Java 开发环境
# 安装 JDK brew install openjdk@11 # 配置 R 环境 sudo R CMD javareconf其二,从源码安装 rJava 包
↩︎install.packages(c('rJava', 'JGR'), type = 'source')需要安装一些依赖,下面仅以 MacOS 系统为例,先安装系统软件
brew install gtk+再从源码安装 R 包 RGtk2。
↩︎install.packages('RGtk2', type = 'source')等效 T 检验:零假设是 \(\mu = \mu_0\) 而备择假设是 \(\mu \neq \mu_0\),其中 \(\mu_0\) 已知,它是一般 T 检验的特殊形式。↩︎
中介分析是因果推断中非常重要的部分,R 语言扩展包 mediation (Tingley et al. 2014) 是典型的代表。↩︎
数字根据
tools::dependsOnPkgs('shiny', installed = tools::CRAN_package_db())统计得到。↩︎马斯克研究无人航天器登陆火星,美团研究无人飞行器送外卖。https://www.yicai.com/news/100695161.html↩︎
表格来自 美团 R 语言数据运营实战↩︎