本文概览
分析目标:患者在医生诊断后,预测需要等待多久时间来住院,探索影响入院等待时间的因素
分析思路:
探索影响入院等待时间的因素
- 根据相关性寻找原因,用回归分析
- 影响等待时间的因素,时间长一点短一点,只要来住院,这个问题似乎更重要
更加准确地预测等待时间
- 预测问题,可用机器学习的方法
分析流程
- 弄清楚各个指标的含义,特别是离群值和缺失值的实际意义
- 描述性统计分析,从数据中获得初步认识,为数据建模和结果解释做依据
- 建立广义线性模型和机器学习模型
- 模型评估、选择、结果分析和解释
- 分析目标
- 患者在医生诊断后,需要等待多久时间来住院,探索影响入院等待时间的因素
- 根据观测结果和相关性寻找原因的问题,属于回归分析
- 更加准确地预测等待时间(时间长一点短一点只有来住院)
- 影响等待时间的因素(这个问题似乎更重要)
- 分析流程
- 弄清楚各个指标的含义,包括离群值和缺失值的实际意义
- 描述性统计分析,从数据中获得进一步认识,为数据建模做依据
- 建立模型,模型评估和选择
- 模型结果分析和解释
数据操作
dat <- read.csv(file = "data/hospital_waiting_time.csv",
header = TRUE, check.names = FALSE, fileEncoding = "GBK")# A tibble: 2,625 × 11
等待时间 门诊次 住院次 开住院条日期 性别 年龄 入院疾病分类 入院目的
<dbl> <int> <int> <fct> <fct> <int> <fct> <fct>
1 1 2 1 3 0 42 3 1
2 1.2 7 1 3 0 32 1 1
3 20 43 1 3 1 59 1 1
4 6 1 1 3 1 9 3 1
5 8.9 3 1 3 1 45 3 1
6 2.9 1 1 3 1 73 3 1
7 7.9 10 1 3 0 50 4 1
8 2.8 3 1 3 1 25 1 1
9 2.7 6 1 3 1 14 2 1
10 5 2 1 3 1 20 3 1
# ℹ 2,615 more rows
# ℹ 3 more variables: 住院类别 <fct>, 入院病情 <fct>, 医生 <fct>- 门诊次:挂号看诊次数
- 住院次:办理住院的次数
- 开住院条的日期:住院天数
plot(dat$门诊次) # 为什么有几百次的门诊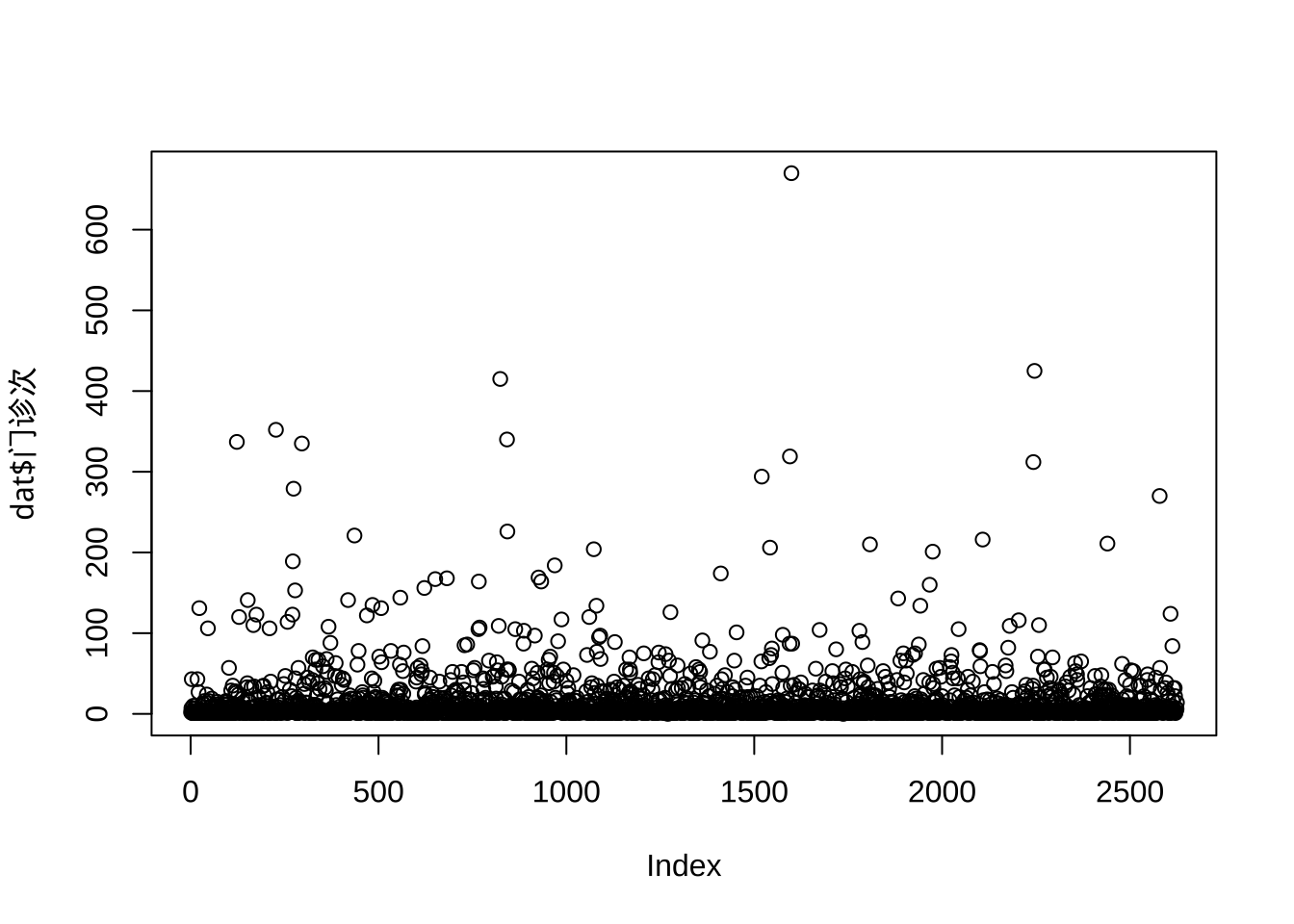
plot(dat$开住院条日期) # 实际还有一类是缺失值
- 住院次数特别多的人,比如10次以上,是比较异常的,情况比较少,两种住院类型都有,等待时间比较短
subset(dat, 住院次 > 10) 等待时间 门诊次 住院次 开住院条日期 性别 年龄 入院疾病分类 入院目的
227 9.9 352 150 3 0 80 1 1
617 0.0 84 22 4 1 41 1 2
709 3.9 5 14 4 0 46 1 1
736 0.1 86 23 4 1 41 1 2
933 0.0 164 36 4 0 57 3 1
1091 20.0 68 19 1 1 44 3 1
1417 1.0 12 15 1 0 46 1 1
1599 27.9 670 11 1 1 59 3 1
1788 28.2 89 38 2 0 70 4 1
1922 0.7 73 14 2 1 25 4 1
住院类别 入院病情 医生
227 2 1 2
617 1 1 4
709 2 1 2
736 1 1 4
933 1 1 2
1091 2 1 2
1417 2 1 2
1599 2 1 2
1788 1 1 2
1922 2 1 2plot(dat$住院次[dat$住院次 < 10], ylab = "住院次数", xlab = "")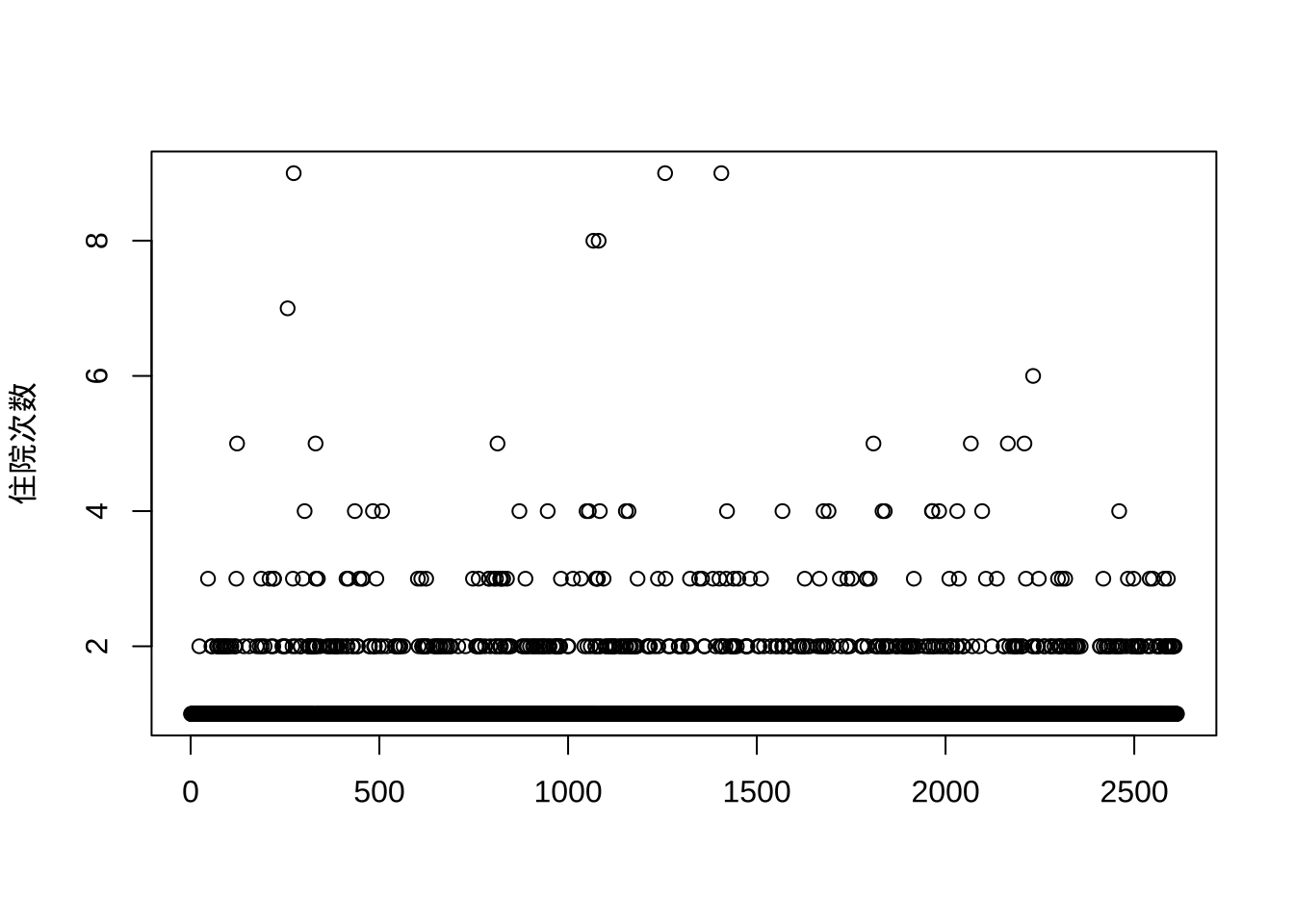
- 等待时间为0,说明情况紧急,急需住院,也可能是着急占床位,入院病情是否相符。响应变量近似看作服从对数正态分布,取值为0,对应的密度也是0,其实可以去掉
subset(dat, 等待时间 == 0)[1:6, ] 等待时间 门诊次 住院次 开住院条日期 性别 年龄 入院疾病分类 入院目的
30 0 1 1 3 1 40 4 1
57 0 1 2 3 1 14 2 2
84 0 1 1 3 0 19 4 2
85 0 2 1 3 0 48 3 1
124 0 3 1 3 1 67 1 1
135 0 3 1 3 1 58 4 1
住院类别 入院病情 医生
30 1 1 2
57 1 1 2
84 2 1 2
85 1 1 2
124 2 1 2
135 1 1 4- 开住院条日期缺失,说明可能没办住院手续,等待时间如何分布
boxplot(subset(dat, is.na(开住院条日期), select = "等待时间"))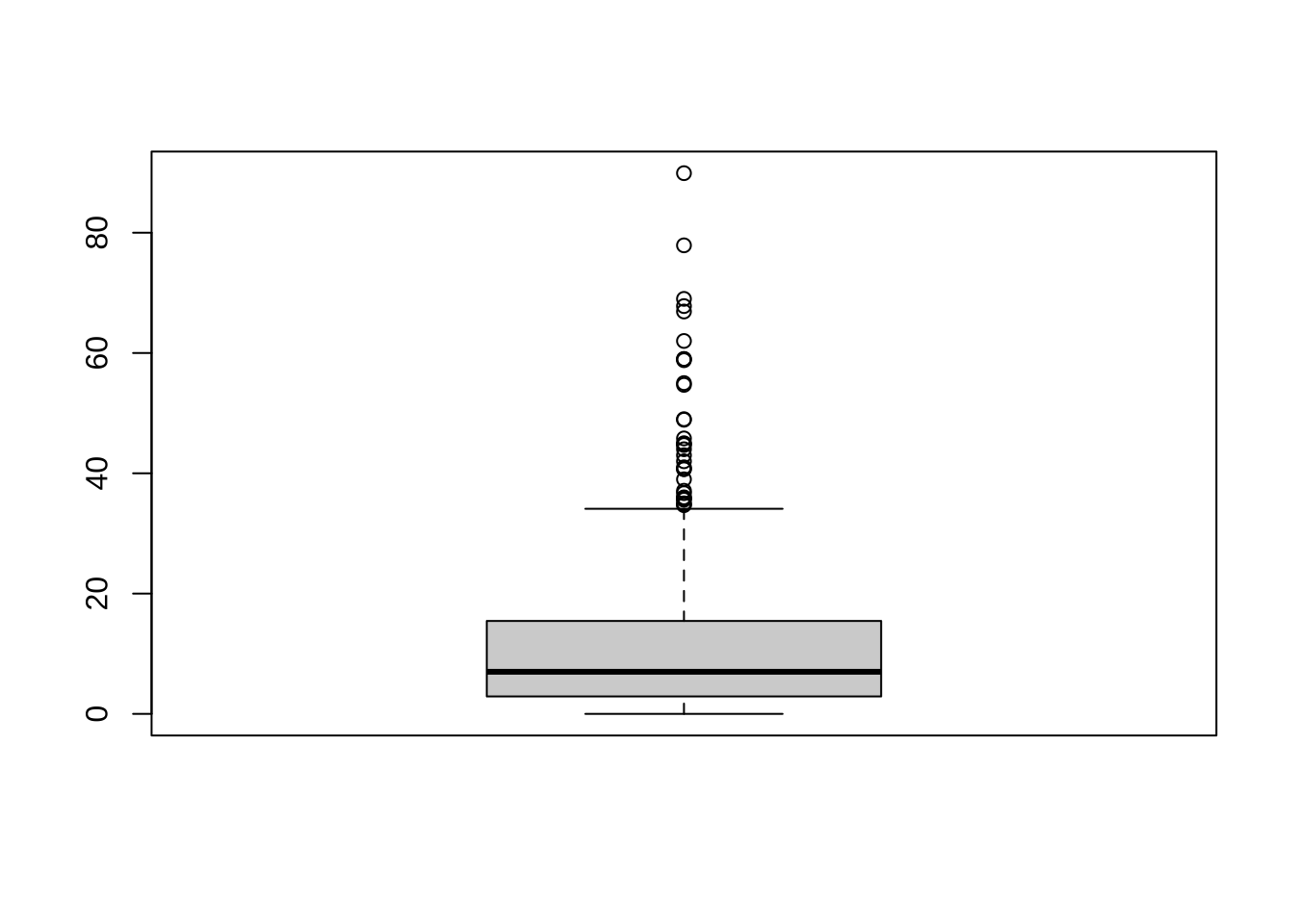
- 去掉等待时间为 0,门诊次为 0 的记录,住院次数特别多的情况
- 年龄标准化,门诊次对数变换,开住院条日期缺失单独作为一类
- 将罕见的情况,对模型来说,可以认为是异常情况
# 去掉异常值
sub_dat <- subset(dat, 等待时间 != 0 & 门诊次 != 0 & 住院次 <= 10)
# 年龄标准化,门诊次对数变换
sub_dat <- transform(sub_dat, 年龄 = (年龄 - mean(年龄)) / sd(年龄), 门诊次 = log(门诊次), 开住院条日期 = ifelse(is.na(开住院条日期), 0, 开住院条日期))
tibble::as_tibble(sub_dat)# A tibble: 2,356 × 11
等待时间 门诊次 住院次 开住院条日期 性别 年龄 入院疾病分类 入院目的
<dbl> <dbl> <int> <dbl> <fct> <dbl> <fct> <fct>
1 1 0.693 1 3 0 0.277 3 1
2 1.2 1.95 1 3 0 -0.229 1 1
3 20 3.76 1 3 1 1.14 1 1
4 6 0 1 3 1 -1.39 3 1
5 8.9 1.10 1 3 1 0.428 3 1
6 2.9 0 1 3 1 1.84 3 1
7 7.9 2.30 1 3 0 0.681 4 1
8 2.8 1.10 1 3 1 -0.582 1 1
9 2.7 1.79 1 3 1 -1.14 2 1
10 5 0.693 1 3 1 -0.835 3 1
# ℹ 2,346 more rows
# ℹ 3 more variables: 住院类别 <fct>, 入院病情 <fct>, 医生 <fct>数据探索
等待时间的分布
- 等待时间的是偏态分布,右偏
library(ggplot2)
gWT1 <- ggplot(data = sub_dat, aes(等待时间)) +
geom_histogram()
gWT2 <- ggplot(data = sub_dat, aes(x = factor(1), y = 等待时间)) +
geom_jitter()
gWT3 <- ggplot(data = sub_dat, aes(x = factor(1), y = 等待时间)) +
geom_boxplot()
gWT4 <- ggplot(data = sub_dat, aes(x = factor(1), y = 等待时间)) +
geom_violin()
library(cowplot)
plot_grid(gWT1, gWT2, gWT3, gWT4, label_size = 12)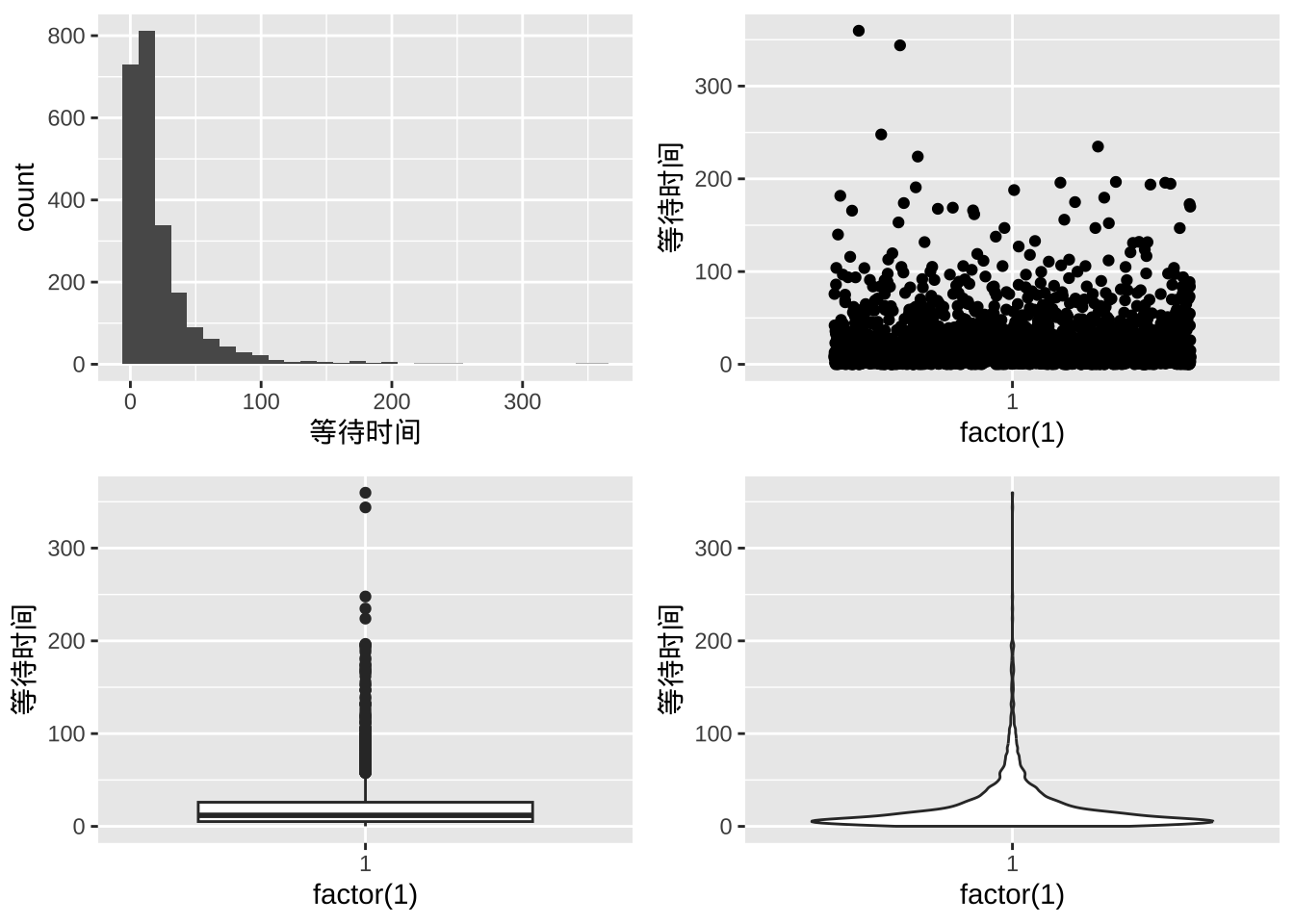
- 对数化等待时间的分布
ggplot(data = sub_dat, aes(log(等待时间))) +
geom_histogram()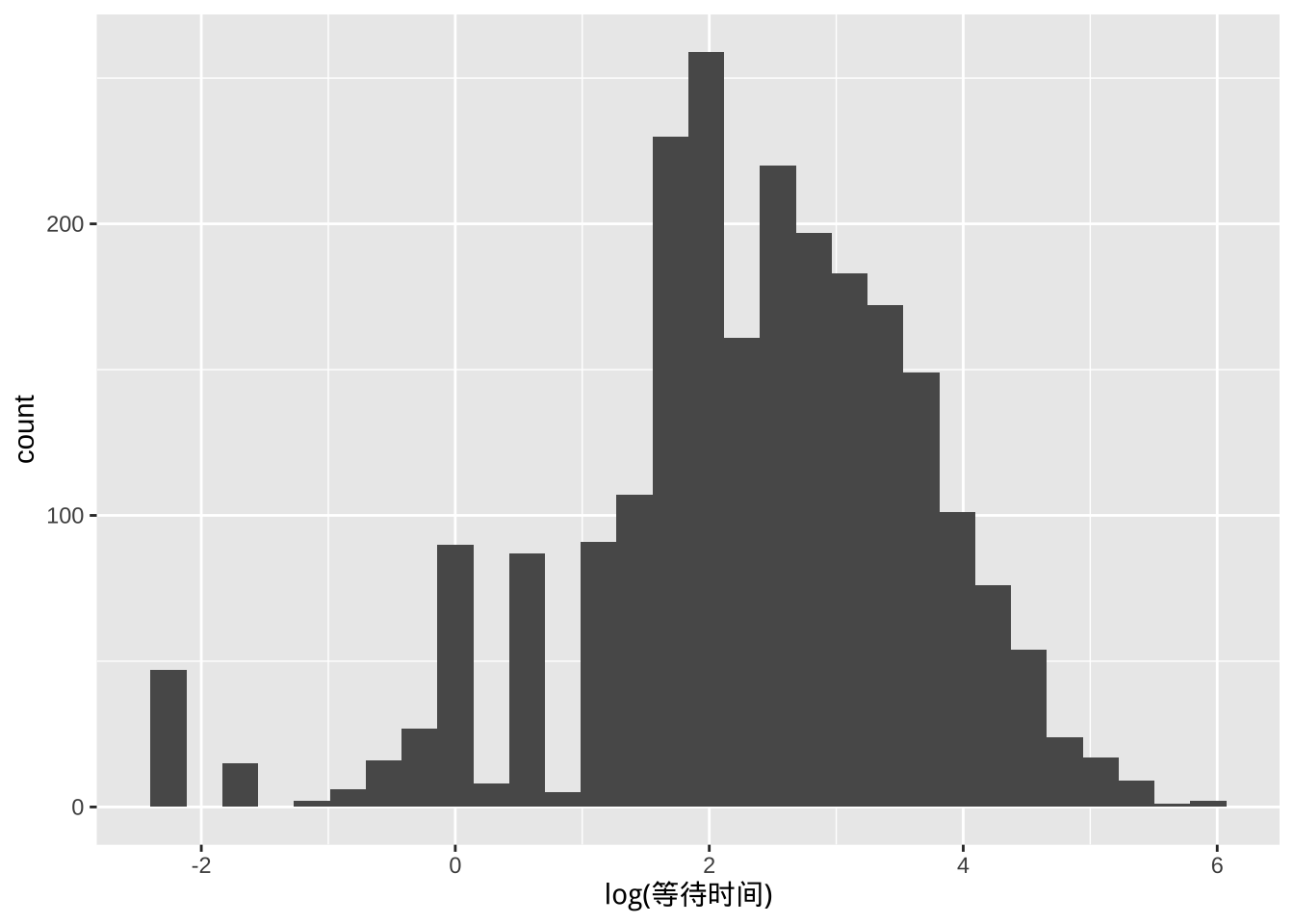
等待时间和医生及入院病情的关系
- 2号病情属于比较紧急的情况,都是立即办住院,和医生的类型无关,这也符合常识
ggplot(data = dat, aes(x = 医生, y = 等待时间, color = 医生)) +
geom_jitter() +
facet_grid(~入院病情)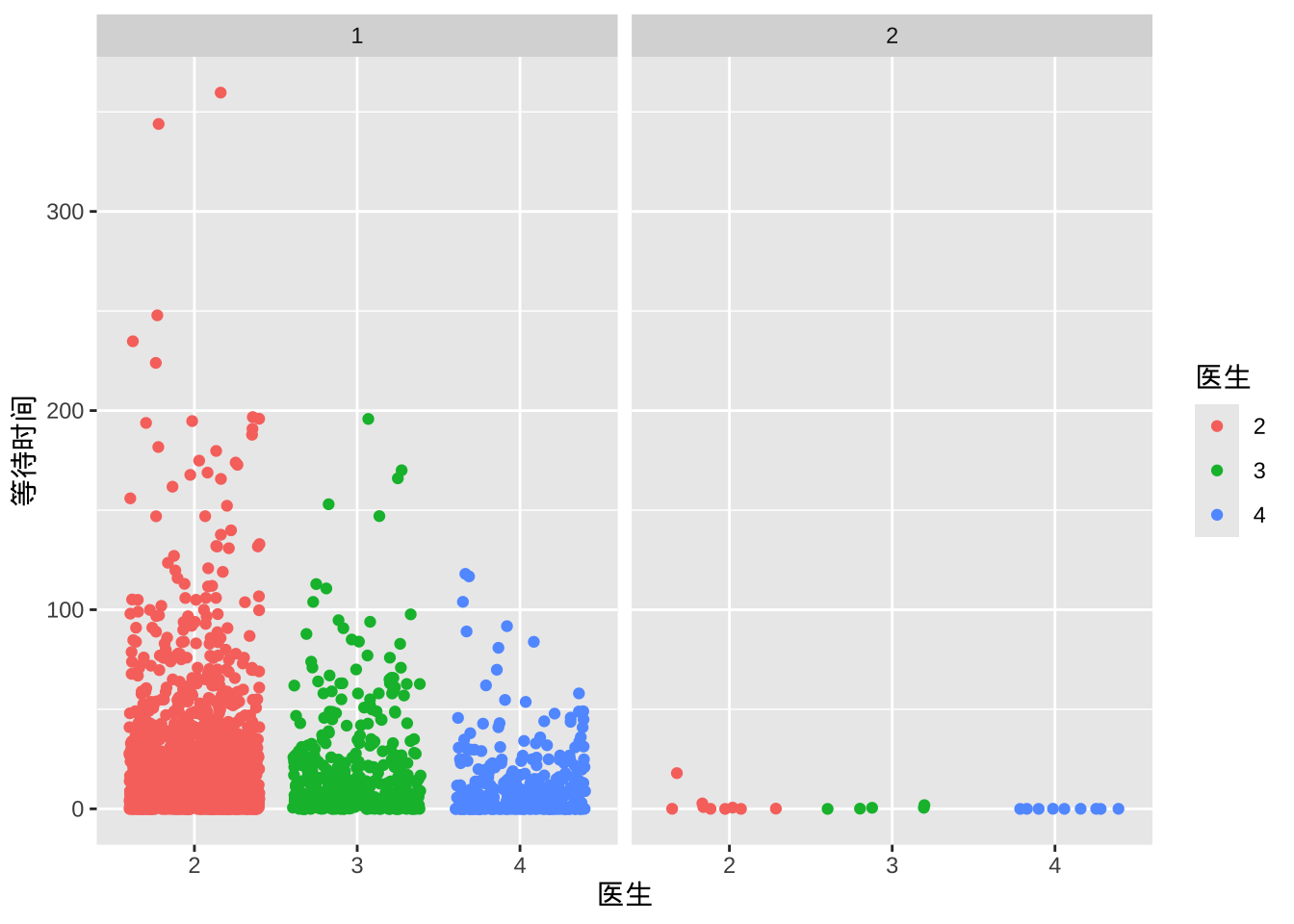
按医生类别和入院病情分组平均
aggregate(等待时间 ~ 医生 + 入院病情, data = sub_dat, mean) 医生 入院病情 等待时间
1 2 1 22.10
2 3 1 22.79
3 4 1 16.18
4 2 2 4.44
5 3 2 0.75等待时间和住院类别及入院目的的关系
- 2号和3号入院目的的等待时间短,1号住院类别相比2号短
ggplot(data = sub_dat, aes(x = 住院类别, y = 等待时间, color = 住院类别)) +
geom_jitter() +
facet_grid(~入院目的)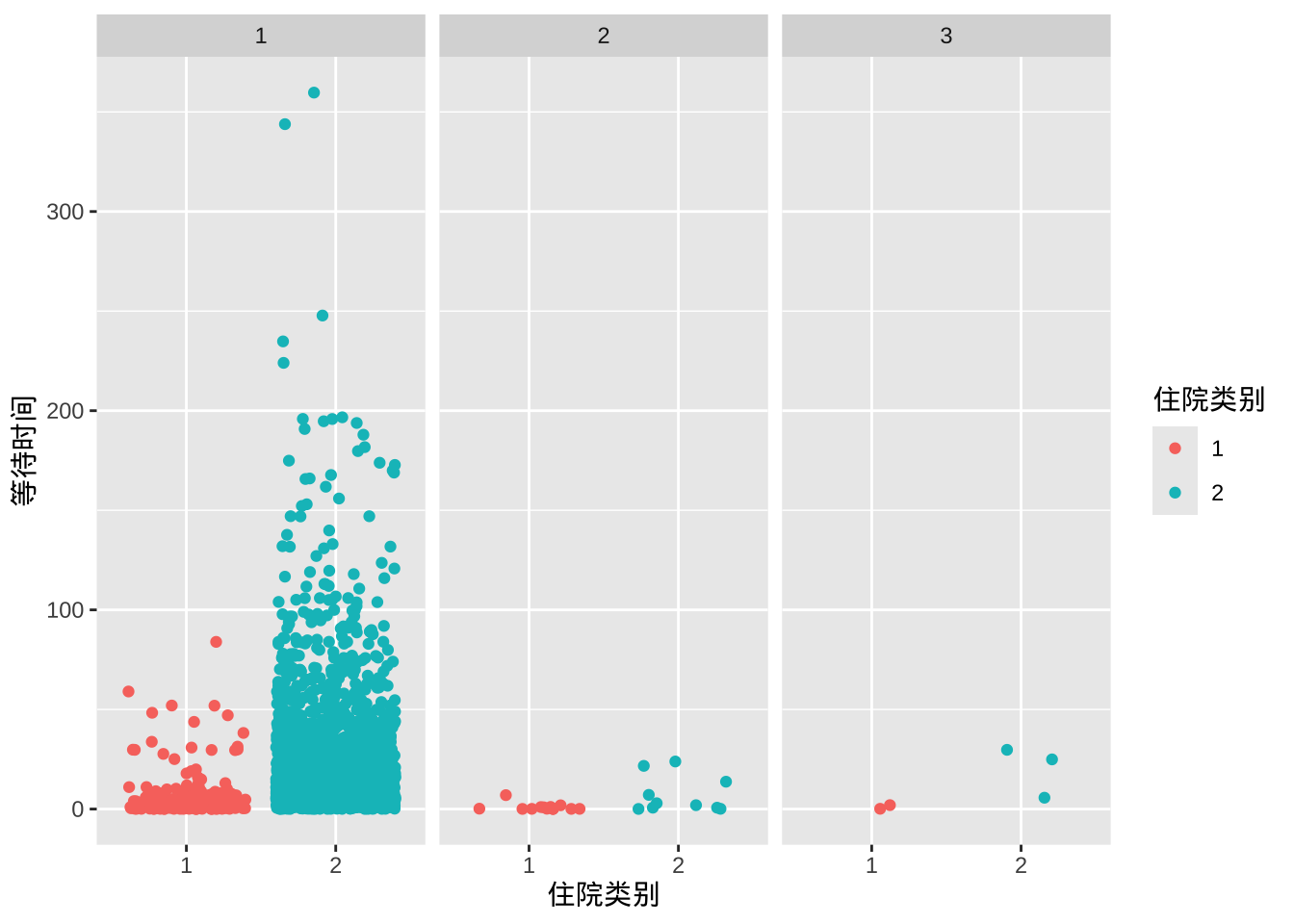
按入院类别和入院目的分组平均
aggregate(等待时间 ~ 住院类别 + 入院目的, data = sub_dat, mean) 住院类别 入院目的 等待时间
1 1 1 8.7272
2 2 1 22.6162
3 1 2 0.9286
4 2 2 7.2800
5 1 3 1.0500
6 2 3 20.1000等待时间和病人性别及年龄的关系
- 和性别关系不大
- 年龄跨度从2岁到98岁
g3 <- ggplot(data = dat, aes(x = 年龄, y = 等待时间)) +
geom_point() +
facet_grid(~性别)
g4 <- ggplot(data = dat, aes(x = 年龄, y = log(等待时间))) +
geom_point() +
facet_grid(~性别)
plot_grid(g3, g4, label_size = 12)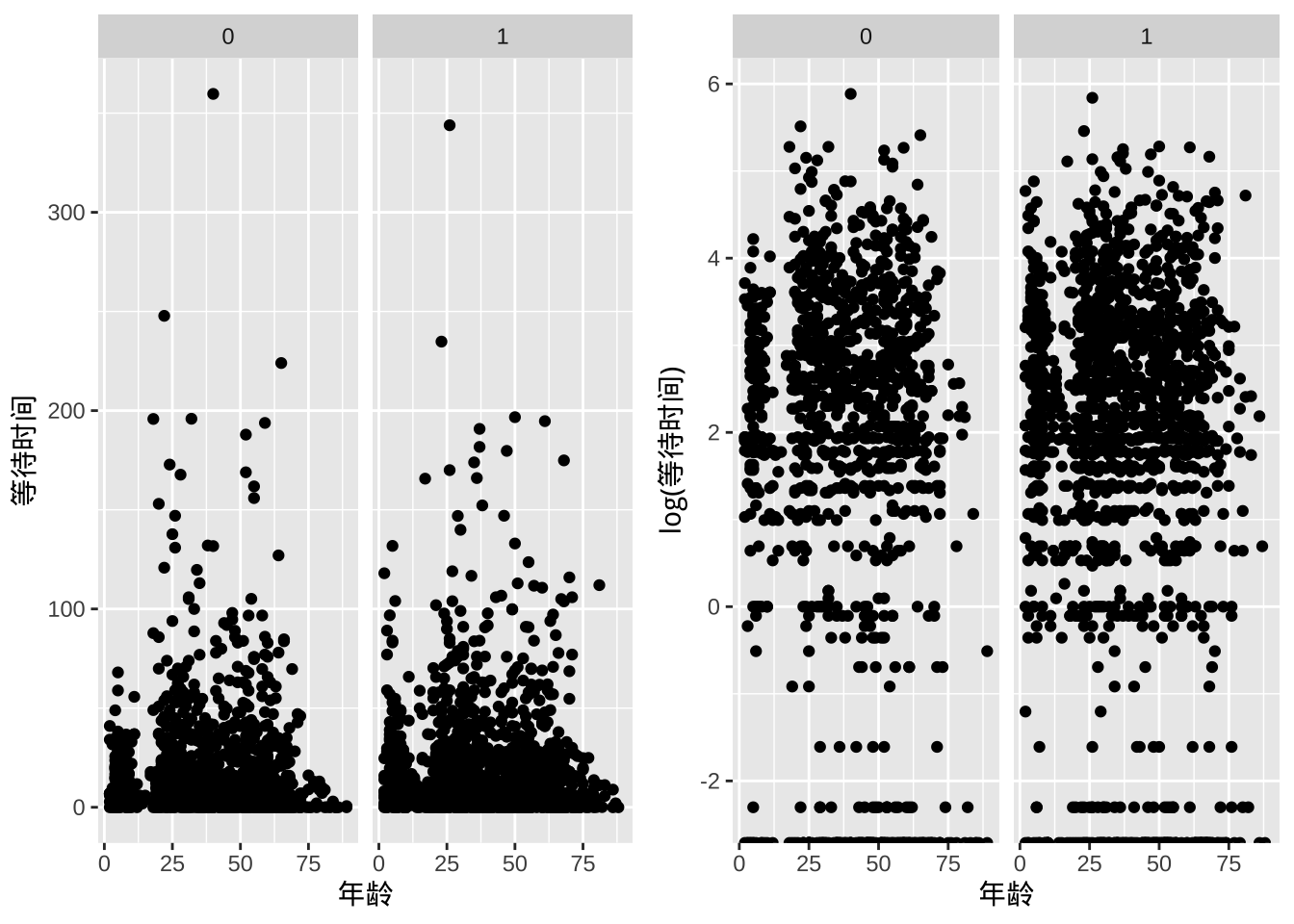
广义线性模型
gamma_glm_fit <- glm(
data = sub_dat, formula = 等待时间 ~ .,
family = Gamma(link = "inverse") # or Gamma(link = "log")
)
AIC(gamma_glm_fit)[1] 18875summary(gamma_glm_fit)
Call:
glm(formula = 等待时间 ~ ., family = Gamma(link = "inverse"),
data = sub_dat)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.114066 0.013075 8.72 < 2e-16 ***
门诊次 -0.000761 0.000987 -0.77 0.44096
住院次 0.003294 0.002199 1.50 0.13433
开住院条日期 -0.002363 0.000861 -2.75 0.00608 **
性别1 0.002359 0.002363 1.00 0.31823
年龄 -0.002795 0.001238 -2.26 0.02400 *
入院疾病分类2 -0.014005 0.002883 -4.86 1.3e-06 ***
入院疾病分类3 0.012238 0.003520 3.48 0.00052 ***
入院疾病分类4 0.002447 0.005696 0.43 0.66756
入院目的2 0.192645 0.071648 2.69 0.00722 **
入院目的3 0.007143 0.043864 0.16 0.87065
住院类别2 -0.067509 0.012366 -5.46 5.3e-08 ***
入院病情2 0.218393 0.150866 1.45 0.14787
医生3 -0.002755 0.003234 -0.85 0.39434
医生4 0.012250 0.005139 2.38 0.01723 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Gamma family taken to be 1.634)
Null deviance: 3555.1 on 2355 degrees of freedom
Residual deviance: 3219.7 on 2341 degrees of freedom
AIC: 18875
Number of Fisher Scoring iterations: 7虽然预测效果差,但是不妨碍去找影响因素
library(brms)
log_glm_brm_fit1 <- brm(
data = sub_dat, formula = 等待时间 ~ .,
family = lognormal(link = "identity", link_sigma = "log"),
refresh = 0,
backend = "rstan"
)
log_glm_brm_fit1
loo_fit1 <- loo(log_glm_brm_fit1) # LOOIC 越小越好
log_glm_brm_fit2 <- brm(
data = sub_dat, formula = 等待时间 ~ .,
family = Gamma(link = "log"),
refresh = 0,
backend = "rstan"
)
log_glm_brm_fit2
loo_fit2 <- loo(log_glm_brm_fit2) # LOOIC 越小越好
# Leave-one-out cross-validation
loo_compare(loo_fit1, loo_fit2, criterion = "waic")假定等待时间服从伽马分布比服从对数正态分布拟合效果好一些
结果解释
- 是男是女对等待时间的贡献水平是基本一样的,性别这个变量在这个数据集或者说这类病中影响不大;
- 年龄对等待时间是正的贡献,年龄越大,等待时间越长;
- 以疾病类型1为参照,2号疾病有更大影响,相对1号,等待时间更长,3号和4号疾病反之;
- 以1号入院目的为参照,2号入院目的对等待时间是负的贡献,即出现2号入院目的,等待时间会更短;
- 住院类型1号和2号都对等待时间有正的贡献;
- 相比于2号医生,3号医生对等待时间是正的贡献,4号医生是负的贡献,说明患者去4号医生那看病后,更快去办入院手续,从相对值来看,这位医生很可能挂专家门诊,并且比三号医生更加有名。
模型评估
使用机器学习的算法,需要把数据集做拆分为训练集和测试集,对测试集做10折交叉验证,用平均均方误差衡量模型的性能。
# n 样本量 z 折数 seed 设置抽样的随机数种子
# 将样本随机地分成 z 份
cv <- function(n = 100, z = 9, seed = 2019) {
set.seed(seed)
idx_seq <- rep(1:z, ceiling(n / z))[1:n] # 初始化 1-9 组成的指标序列,长度等于样本量
reorder_idx_seq <- sample(x = idx_seq, size = n, replace = FALSE) # 对指标序列 idx_seq 重排
mm <- vector("list", z) # 初始化列表,存储原序列的下标集
for (i in 1:z) {
mm[[i]] <- (1:n)[reorder_idx_seq == i] # 第i折对应的原序列的下标集
}
return(mm)
}
n <- nrow(sub_dat)
kfold <- 10
idx <- cv(n, kfold, seed = 2019)
D <- 1 # 等待时间 在第 1 列
# 初始化向量用于存储均方误差
MSE <- rep(0, kfold)模型比较
伽马广义线性模型
for (i in 1:kfold) {
m <- idx[[i]]
M <- mean((sub_dat[m, D] - mean(sub_dat[m, D]))^2) # 用平均值预测 等待时间 的均方误差
log_lm_fit <- glm(
data = sub_dat[-m, ], formula = 等待时间 ~ .,
family = Gamma(link = "inverse")
)
MSE[i] <- mean((sub_dat[m, D] - predict(log_lm_fit, sub_dat[m, ]))^2) / M # 测试集上算均方误差
}
mean(MSE) # 1.420639[1] 1.555决策树回归
library(rpart)
rpart_fit <- rpart(data = sub_dat, 等待时间 ~ .)
plot(rpart_fit)
library(rpart.plot)
rpart.plot(rpart_fit, type = 2, faclen = 0)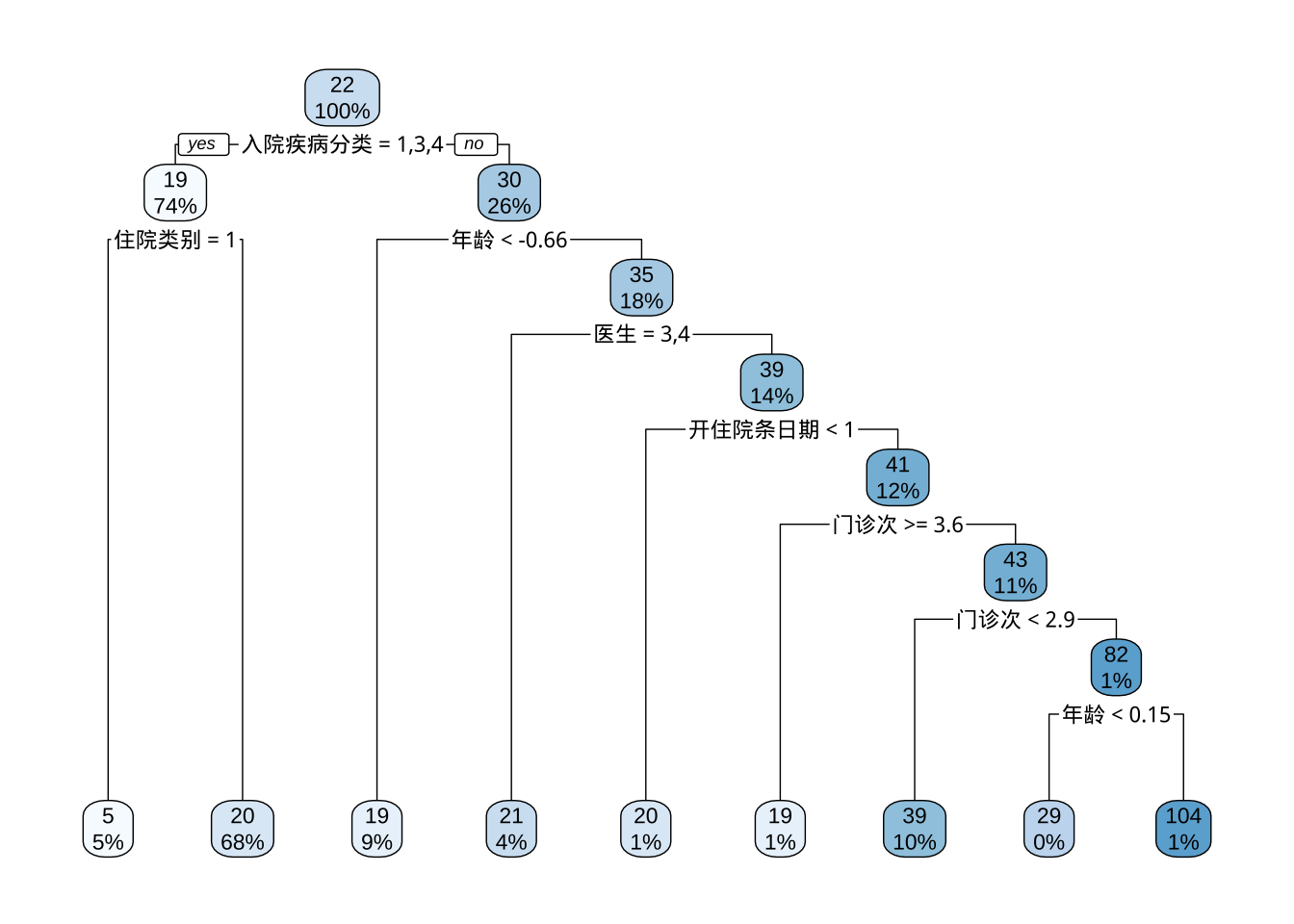
for (i in 1:kfold) {
m <- idx[[i]]
M <- mean((sub_dat[m, D] - mean(sub_dat[m, D]))^2) # 用平均值预测 等待时间 的均方误差
rpart_fit <- rpart(data = sub_dat[-m, ], 等待时间 ~ .)
MSE[i] <- mean((sub_dat[m, D] - predict(rpart_fit, sub_dat[m, ]))^2) / M # 测试集上算均方误差
}
# 相对均方误差 越小越好
mean(MSE) # 10 折下来的平均结果 0.9805241[1] 0.9892随机森林
library(randomForest)
for (i in 1:kfold) {
m <- idx[[i]]
M <- mean((sub_dat[m, D] - mean(sub_dat[m, D]))^2) # 用平均值预测 等待时间 的均方误差
rf_fit <- randomForest(data = sub_dat[-m, ], 等待时间 ~ .)
MSE[i] <- mean((sub_dat[m, D] - predict(rf_fit, sub_dat[m, ]))^2) / M # 测试集上算均方误差
}
# 相对均方误差 越小越好
mean(MSE) # 10 折下来的平均结果 0.9859137[1] 0.9894rf_fit <- randomForest(
x = sub_dat[, -1], y = sub_dat[, 1],
importance = TRUE, proximity = TRUE
)
# 变量重要性
rf_fit$importance %IncMSE IncNodePurity
门诊次 -5.11389 237698.8
住院次 10.82338 40762.8
开住院条日期 2.50794 112733.8
性别 4.97812 42302.2
年龄 31.14779 339764.3
入院疾病分类 107.25242 110993.5
入院目的 1.35767 5496.1
住院类别 30.17924 31561.0
入院病情 0.04886 702.8
医生 9.95702 48591.2两列都是数值越大,变量越重要
支持向量机
library(e1071)
# x 全部得是数值型的
svm_fit <- svm(data = sub_dat, 等待时间 ~ .)
for (i in 1:kfold) {
m <- idx[[i]]
M <- mean((sub_dat[m, D] - mean(sub_dat[m, D]))^2) # 用平均值预测 等待时间 的均方误差
svm_fit <- svm(data = sub_dat[-m, ], 等待时间 ~ .)
MSE[i] <- mean((sub_dat[m, D] - predict(svm_fit, sub_dat[m, ]))^2) / M # 测试集上算均方误差
}
# 相对均方误差 越小越好
mean(MSE) # 10 折下来的平均结果 1.031385 效果非常差,不能接受[1] 1.037神经网络
library(nnet)
# library(caret)
set.seed(2019)
comp_grid <- expand.grid(
.decay = c(0.5, 0.4, 0.3, 0.2, 0.1, 0.05),
.size = c(4, 5, 6, 7, 8)
)
nnet_fit <- caret::train(
等待时间 / max(等待时间) ~ .,
data = sub_dat,
method = "nnet", maxit = 1000,
tuneGrid = comp_grid, trace = FALSE
)
print(nnet_fit) # size = 5 and decay = 0.05Neural Network
2356 samples
10 predictor
No pre-processing
Resampling: Bootstrapped (25 reps)
Summary of sample sizes: 2356, 2356, 2356, 2356, 2356, 2356, ...
Resampling results across tuning parameters:
decay size RMSE Rsquared MAE
0.05 4 0.08035 0.06014 0.05025
0.05 5 0.08032 0.06044 0.05022
0.05 6 0.08036 0.05975 0.05025
0.05 7 0.08035 0.05997 0.05022
0.05 8 0.08036 0.05996 0.05023
0.10 4 0.08080 0.04873 0.05069
0.10 5 0.08079 0.04891 0.05066
0.10 6 0.08079 0.04903 0.05064
0.10 7 0.08079 0.04912 0.05063
0.10 8 0.08079 0.04917 0.05062
0.20 4 0.08110 0.04362 0.05127
0.20 5 0.08109 0.04399 0.05122
0.20 6 0.08109 0.04428 0.05118
0.20 7 0.08109 0.04449 0.05116
0.20 8 0.08110 0.04463 0.05114
0.30 4 0.08139 0.03846 0.05178
0.30 5 0.08138 0.03911 0.05170
0.30 6 0.08137 0.03965 0.05164
0.30 7 0.08137 0.04007 0.05160
0.30 8 0.08138 0.04037 0.05157
0.40 4 0.08166 0.03285 0.05222
0.40 5 0.08164 0.03391 0.05212
0.40 6 0.08162 0.03478 0.05204
0.40 7 0.08162 0.03549 0.05198
0.40 8 0.08162 0.03605 0.05193
0.50 4 0.08190 0.02699 0.05261
0.50 5 0.08186 0.02846 0.05248
0.50 6 0.08184 0.02969 0.05238
0.50 7 0.08182 0.03070 0.05230
0.50 8 0.08182 0.03154 0.05224
RMSE was used to select the optimal model using the smallest value.
The final values used for the model were size = 5 and decay = 0.05.for (i in 1:kfold) {
m <- idx[[i]]
M <- mean((sub_dat[m, D] - mean(sub_dat[m, D]))^2) # 用平均值预测 等待时间 的均方误差
nnet_fit <- nnet(data = sub_dat[-m, ], 等待时间 / max(sub_dat[, D]) ~ ., size = 5, decay = 0.05, trace = FALSE)
MSE[i] <- mean((sub_dat[m, D] - predict(nnet_fit, sub_dat[m, ]) * max(sub_dat[, D]))^2) / M # 测试集上算均方误差
}
# 相对均方误差 越小越好
mean(MSE) # 10 折下来的平均结果 0.9601197[1] 0.9557Box-Cox 变换
Box-Cox 变换后,再做线性拟合
library(MASS)
b <- boxcox(等待时间 ~ ., data = sub_dat)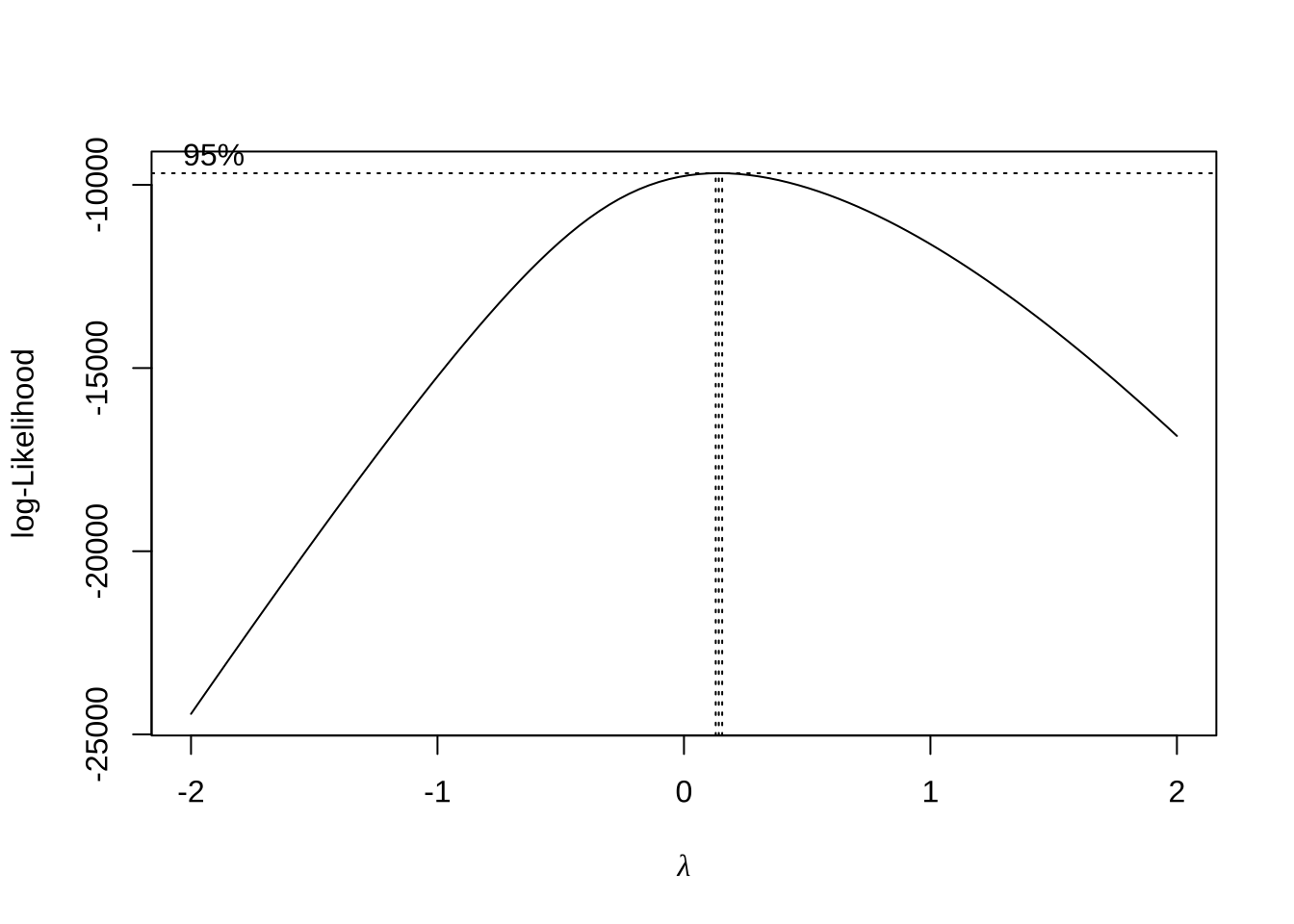
i <- which(b$y == max(b$y))
b$x[i] # 选 lambda[1] 0.1414选好 lambda 先拟合线性模型做 baseline
lm_fit <- lm(等待时间^0.14 ~ ., data = sub_dat)
step_lm_fit <- step(lm_fit, trace = FALSE)
AIC(step_lm_fit)[1] 49.03summary(step_lm_fit)
Call:
lm(formula = 等待时间^0.14 ~ 门诊次 + 住院次 + 开住院条日期 +
年龄 + 入院疾病分类 + 入院目的 + 住院类别 +
入院病情 + 医生, data = sub_dat)
Residuals:
Min 1Q Median 3Q Max
-0.7174 -0.1536 -0.0013 0.1637 0.7811
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.15867 0.02617 44.27 < 2e-16 ***
门诊次 0.01503 0.00431 3.49 0.0005 ***
住院次 -0.01918 0.00788 -2.43 0.0150 *
开住院条日期 0.00878 0.00372 2.36 0.0184 *
年龄 0.00781 0.00527 1.48 0.1385
入院疾病分类2 0.08262 0.01388 5.95 3.1e-09 ***
入院疾病分类3 -0.01758 0.01284 -1.37 0.1710
入院疾病分类4 0.00280 0.02196 0.13 0.8985
入院目的2 -0.31052 0.05143 -6.04 1.8e-09 ***
入院目的3 -0.04582 0.10943 -0.42 0.6755
住院类别2 0.23974 0.02125 11.28 < 2e-16 ***
入院病情2 -0.16362 0.08430 -1.94 0.0524 .
医生3 0.00730 0.01480 0.49 0.6221
医生4 -0.05547 0.01716 -3.23 0.0012 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.244 on 2342 degrees of freedom
Multiple R-squared: 0.125, Adjusted R-squared: 0.12
F-statistic: 25.7 on 13 and 2342 DF, p-value: <2e-16for (i in 1:kfold) {
m <- idx[[i]]
M <- mean((sub_dat[m, D] - mean(sub_dat[m, D]))^2) # 用平均值预测 等待时间 的均方误差
lm_fit <- lm(等待时间^0.14 ~ ., data = sub_dat[-m, ])
MSE[i] <- mean((sub_dat[m, D] - predict(nnet_fit, sub_dat[m, ]) * max(sub_dat[, D]))^2) / M # 测试集上算均方误差
}
# 相对均方误差 越小越好
mean(MSE) # 10 折下来的平均结果 0.9404893[1] 0.9405